







java部分
DOM4J
与利用DOM、SAX、JAXP机制来解析xml相比,DOM4J 表现更优秀,具有性能优异、功能强大和极端易用使用的特点,只要懂得DOM基本概念,就可以通过dom4j的api文档来解析xml。dom4j是一套开源的api。实际项目中,往往选择dom4j来作为解析xml的利器。
先来看看dom4j中对应XML的DOM树建立的继承关系
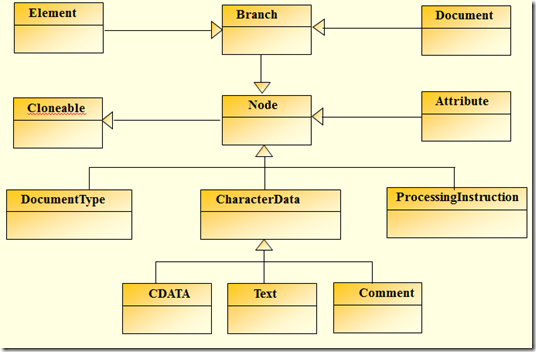
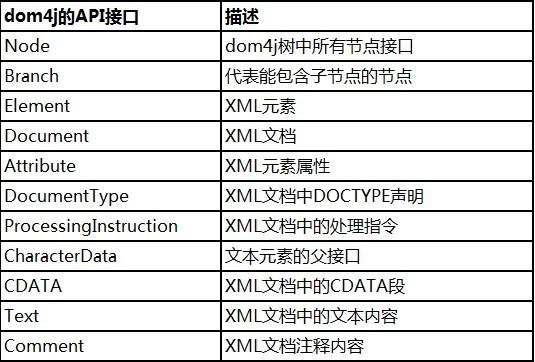
针对于XML标准定义,对应于图2-1列出的内容,dom4j提供了以下实现:
同时,dom4j的NodeType枚举实现了XML规范中定义的node类型。如此可以在遍历xml文档的时候通过常量来判断节点类型了。
常用API
class org.dom4j.io.SAXReader
read 提供多种读取xml文件的方式,返回一个Domcument对象
interface org.dom4j.Document
iterator 使用此法获取node
getRootElement 获取根节点
interface org.dom4j.Node
getName 获取node名字,例如获取根节点名称为bookstore
getNodeType 获取node类型常量值,例如获取到bookstore类型为1——Element
getNodeTypeName 获取node类型名称,例如获取到的bookstore类型名称为Element
interface org.dom4j.Element
attributes 返回该元素的属性列表
attributeValue 根据传入的属性名获取属性值
elementIterator 返回包含子元素的迭代器
elements 返回包含子元素的列表
interface org.dom4j.Attribute
getName 获取属性名
getValue 获取属性值
interface org.dom4j.Text
getText 获取Text节点值
interface org.dom4j.CDATA
getText 获取CDATA Section值
interface org.dom4j.Comment
getText 获取注释
环境:
Dom4j-1.6.1
Dom4j解析需要XML需要的最小类库为:
dom4j-1.6.1.jar
jaxen-1.1-beta-6.jar
目标:
解析一个xml,输出所有的属性和元素值。
测试代码:
XML文件:
zhangsan
32
home add
com add
lisi
22
home add
com add
com add
解析代码:
packagecom.topsoft.test;importorg.dom4j.io.SAXReader;importorg.dom4j.Document;importorg.dom4j.DocumentException;importorg.dom4j.Element;importorg.dom4j.Node;importjava.util.Iterator;importjava.util.List;importjava.io.InputStream;/*** Created by IntelliJ IDEA.
* User: leizhimin
* Date: 2008-3-26 15:53:51
* Note: Dom4j遍历解析XML测试*/
public classTestDom4j {/*** 获取指定xml文档的Document对象,xml文件必须在classpath中可以找到
*
*@paramxmlFilePath xml文件路径
*@returnDocument对象*/
public staticDocument parse2Document(String xmlFilePath) {
SAXReader reader= newSAXReader();
Document document= null;try{
InputStream in= TestDom4j.class.getResourceAsStream(xmlFilePath);
document=reader.read(in);
}catch(DocumentException e) {
System.out.println(e.getMessage());
System.out.println("读取classpath下xmlFileName文件发生异常,请检查CLASSPATH和文件名是否存在!");
e.printStackTrace();
}returndocument;
}public static voidtestParseXMLData(String xmlFileName) {//产生一个解析器对象
SAXReader reader = newSAXReader();//将xml文档转换为Document的对象
Document document =parse2Document(xmlFileName);//获取文档的根元素
Element root =document.getRootElement();//定义个保存输出xml数据的缓冲字符串对象
StringBuffer sb = newStringBuffer();
sb.append("通过Dom4j解析XML,并输出数据:\n");
sb.append(xmlFileName+ "\n");
sb.append("----------------遍历start----------------\n");//遍历当前元素(在此是根元素)的子元素
for (Iterator i_pe =root.elementIterator(); i_pe.hasNext();) {
Element e_pe=(Element) i_pe.next();//获取当前元素的名字
String person =e_pe.getName();//获取当前元素的id和sex属性的值并分别赋给id,sex变量
String id = e_pe.attributeValue("id");
String sex= e_pe.attributeValue("sex");
String name= e_pe.element("name").getText();
String age= e_pe.element("age").getText();//将数据存放到缓冲区字符串对象中
sb.append(person + ":\n");
sb.append("\tid=" + id + " sex=" + sex + "\n");
sb.append("\t" + "name=" + name + " age=" + age + "\n");//获取当前元素e_pe(在此是person元素)下的子元素adds
Element e_adds = e_pe.element("adds");
sb.append("\t" + e_adds.getName() + "\n");//遍历当前元素e_adds(在此是adds元素)的子元素
for (Iterator i_adds =e_adds.elementIterator(); i_adds.hasNext();) {
Element e_add=(Element) i_adds.next();
String code= e_add.attributeValue("code");
String add=e_add.getTextTrim();
sb.append("\t\t" + e_add.getName() + ":" + " code=" + code + " value=\"" + add + "\"\n");
}
sb.append("\n");
}
sb.append("-----------------遍历end-----------------\n");
System.out.println(sb.toString());
System.out.println("---------通过XPath获取一个元素----------");
Node node1= document.selectSingleNode("/doc/person");
System.out.println("输出节点:" +
"\t"+node1.asXML());
Node node2= document.selectSingleNode("/doc/person/@sex");
System.out.println("输出节点:" +
"\t"+node2.asXML());
Node node3= document.selectSingleNode("/doc/person[name=\"zhangsan\"]/age");
System.out.println("输出节点:" +
"\t"+node3.asXML());
System.out.println("\n---------XPath获取List节点测试------------");
List list= document.selectNodes("/doc/person[name=\"zhangsan\"]/adds/add");for(Iterator it=list.iterator();it.hasNext();){
Node nodex=(Node)it.next();
System.out.println(nodex.asXML());
}
System.out.println("\n---------通过ID获取元素的测试----------");
System.out.println("陷阱:通过ID获取,元素ID属性名必须为“大写ID”,小写的“id”会认为是普通属性!");
String id22= document.elementByID("22").asXML();
String id23= document.elementByID("23").asXML();
String id24= null;if (document.elementByID("24") != null) {
id24= document.elementByID("24").asXML();
}else{
id24= "null";
}
System.out.println("id22= " +id22);
System.out.println("id23= " +id23);
System.out.println("id24= " +id24);
}public static voidmain(String args[]) {
testParseXMLData("/person.xml");
}
}
运行结果:
通过Dom4j解析XML,并输出数据:
/person.xml
----------------遍历start----------------
person:
id=1 sex=m
name=zhangsan age=32
adds
add: code=home value="home add"
add: code=com value="com add"
person:
id=2 sex=w
name=lisi age=22
adds
add: code=home value="home add"
add: code=com value="com add"
add: code=com value="com add"
-----------------遍历end-----------------
---------通过XPath获取一个元素----------
输出节点:
zhangsan
32
home add
com add
输出节点: sex="m"
输出节点:32---------XPath获取List节点测试------------home add
com add---------通过ID获取元素的测试----------
陷阱:通过ID获取,元素ID属性名必须为“大写ID”,小写的“id”会认为是普通属性!
id22=home addid23=com addid24= null
Process finished with exit code 0
实例一:
//先加入dom4j.jar包
importjava.util.HashMap;importjava.util.Iterator;importjava.util.Map;importorg.dom4j.Document;importorg.dom4j.DocumentException;importorg.dom4j.DocumentHelper;importorg.dom4j.Element;/*** @Title: TestDom4j
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 746
746











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









