







目录
-
概述
-
环境准备
-
什么是分词
- 分词目的
- 分词器
-
彩蛋
概述
关于elasticsearch教程写了关于安装和安装踩坑记两篇博文, 现在就来写点项目中使用中文分词器的历程。
本文旨在分局项目es中使用中文分词器的心得,对es分词器做初步讲解,如有错误和不当之处,欢迎批评指正。
环境准备
- 全新最小化安装的centos 7.5
- elasticsearch 6.4.0
什么是分词
分词这个词表明的意思已经很明了,就是将一句话分成多个词语, 比如: “我爱祖国” 会被拆分为 【我,爱,祖国】。
那么为什么需要拆分成这样呢? 这就要从全文检索数据存储结构说起,深入的存储结构我就不深入讲解了,因为我也不知道具体的[/奸笑]。正式开始,es内部基于apache lucene做了进一步的封装,如果直接使用lucene做全文检索,相信用过的前辈们顿感头顶凉意,有了es封装,小辈们至少可以省一瓶霸王洗发水。
分词的目的
es可以从千万级别数据量快速检索出对应的文档,要归功于一个叫倒排索引的家伙, 通过词汇找到对应的文档,既然有倒排索引,那么同样出现了一个正向索引的东东,下面就来认识一下倒排索引
正向索引
先来说说正向索引,在搜索引擎中,每个文档(每条数据)都会被分词,得到每个词出现的频率以及位置,示例:
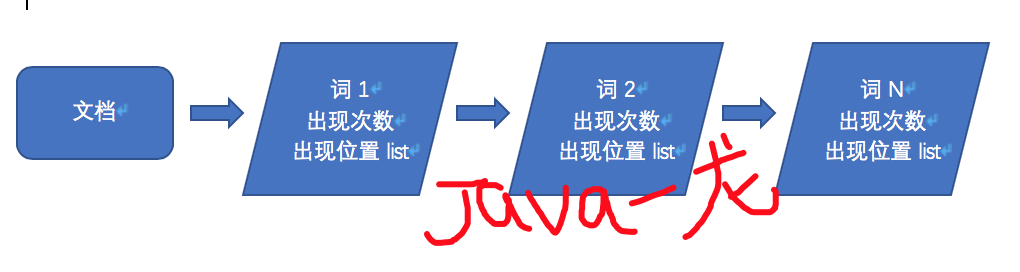
当搜索 词1 时,搜索引擎就要将所有的文档遍历获取到在哪些文档中存在, 类似mysql做查询, 通过文档去找词,当数据量千万级别以上并且多个词进行搜索,想想都好可怕啊!!!
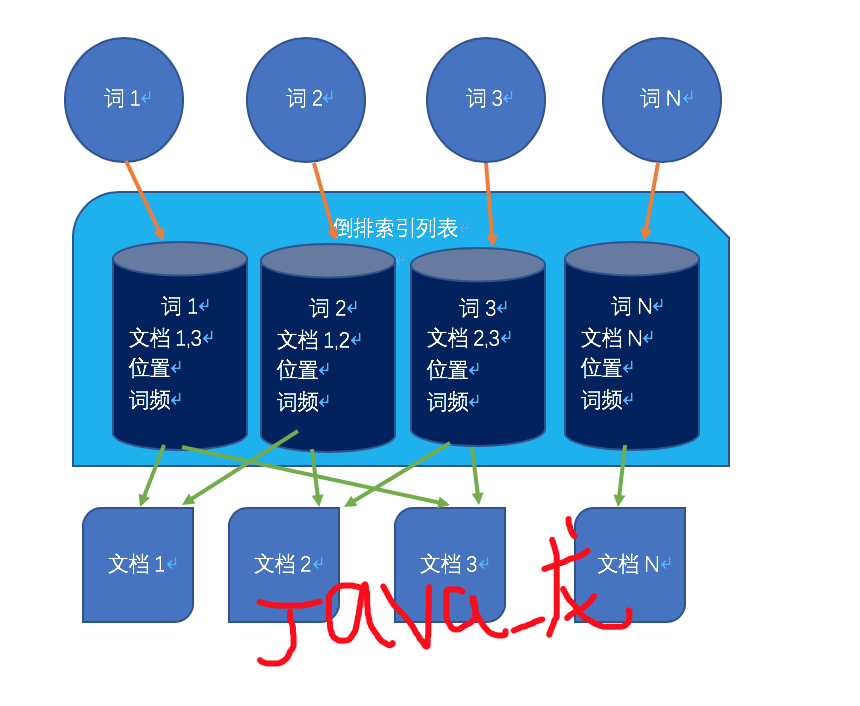
倒排索引
倒排索引反向正向索引,通过词去找文档,通过倒排索引文件,建立词与文档的关系。如下图所示:
分词器
官方解释: 分词是将文本(如任何电子邮件的正文或者一篇文章)转换为标记或术语的过程,这些标记或术语被添加到倒排索引中便于搜索。分析由分析器执行,它可以是内置的分析器,也可以是定义每个索引的自定义分析器。
言而总之,分词器作用就是将文档(文章内容等)进行分词,将词语和文档的关系存入倒排索引便于搜索,举例:
elasticsearch内置的英文分词器效果如下:
"The QUICK brown foxes jumped over the lazy dog!"
英文分词器会将以上语句分成不同的词汇。它将小写每个词汇,除去众多的停用词(the)和减少词汇复意(foxes → fox, jumped → jump, lazy → lazi)。最后,在倒排索引中加入以下词汇:
[ quick, brown, fox, jump, over, lazi, dog ]
elasticsearch内置分词器有standard analyzer,simple analyzer,whitespace analyzer,stop analyzer,Keyword analyzer,pattern analyzer,language analyzers,fingerprint analyzer这8种
注意: 这些内置的分词器对中文支持效果都很差
standard analyzer
默认分词器,它提供了基于语法的分词(基于Unicode文本分割算法,如Unicode® Standard Annex #29所指定的),适用于大多数语言,对中文分词效果很差。
分词示例:

分词效果如下:
[ the, 2, quick, brown, foxes, jumped, over, the, lazy, dog's, bone ]
simple analyzer
它提供了基于字母的分词,如果遇到不是字母时直接分词,所有字母均置为小写
分词示例:

分词效果如下:
[ the, quick, brown, foxes, jumped, over, the, lazy, dog, s, bone ]
whitespace analyzer
它提供了基于空格的分词,如果遇到空格时直接分词
分词示例:

分词效果如下:
[ The, 2, QUICK, Brown-Foxes, jumped, over, the, lazy, dog's, bone. ]
stop analyzer
它与simple analyzer相同,但是支持删除停用词。它默认使用_english_stop单词。
分词示例:

分词效果如下:
[ quick, brown, foxes, jumped, over, lazy, dog, s, bone ]
keyword analyzer
它提供的是无操作分词,它将整个输入字符串作为一个词返回,即不分词。
分词示例:

分词效果如下:
[ The 2 QUICK Brown-Foxes jumped over the lazy dog's bone. ]
pattern analyzer
它提供了基于正则表达式将文本分词。正则表达式应该匹配词语分隔符,而不是词语本身。正则表达式默认为\W+(或所有非单词字符)。
分词示例:

分词效果如下:
[ the, 2, quick, brown, foxes, jumped, over, the, lazy, dog, s, bone ]
language analyzers
它提供了一组语言的分词,旨在处理特定语言.它包含了一下语言的分词:
阿拉伯语,亚美尼亚语,巴斯克语,巴西语,保加利亚语,加泰罗尼亚语,cjk,捷克语,丹麦语,荷兰语,英语,芬兰语,法语,加利西亚语,德语,希腊语,印度语,匈牙利语,爱尔兰语,意大利语,拉脱维亚语,立陶宛语,挪威语,波斯语,葡萄牙语,罗马尼亚语,俄罗斯语,索拉尼语,西班牙语,瑞典语,土耳其语,泰国语。
fingerprint analyzer
它提供了了一种fingerprinting算法,该算法被OpenRefine项目用于帮助集群。
输入文本是模式化语言,经过规范的删除扩展字符、排序、删除索引到分词中。如果配置了停用词列表,也将删除停用词。
分词示例:

分词效果如下:
[ and consistent godel is said sentence this yes ]
彩蛋
下一篇将写关于es插件安装以及中文分词器使用的相关教程以及踩坑记,欢迎关注和收藏














 475
475











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









