







1. 布隆过滤器
1.1 算法简介
布隆过滤器(BloomFilter)由一个很长的二进制向量和一系列抗碰撞的Hash函数组成, 可以用于快速判断一个元素是否在一个集合中。优点:空间仅由二进制向量决定,并且查询时间远超一般算法(仅需计算k 个Hash函数的值);缺点:有一定的错误识别率,并且一旦元素被添加到布隆过滤器中就很难再将该元素从布隆过滤器中删除。
1.2 算法原理
初始状态时,BloomFilter是一个长度为m 的比特数组(二进制向量),每一位都置为0。
![]()
把1个新元素x 添加进BloomFilter,对x 计算k 个散列函数哈希值(哈希值作为比特数组的下标),将比特数组中对应位设置为1。
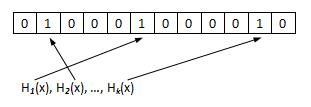
判断元素y 是否存在于BloomFilter中,对y 计算k 个散列函数哈希值,若对应位置的位皆为1,则说明y 存在于BloomFilter中。
1.3 算法实现
虽然布隆过滤器具有一定错误识别率,但可以通过调整m 和k 的值来使得错误识别率可容忍,对于误判元素可以建立一个白名单。这里有一份代码实现:链接。
2. 应用场景:大数据去重
在面试阿里、腾讯时经常会问到“如何对大数据进行去重”的类似问题,比如:给定2个文件,里面保存的是url,对这2个文件中的url进行去重。这里提供3种解题思路:
(1)把文件A切割成k 个小文件(使得内存可容忍,例如占1/2内存),把文件B切割成k 个小文件,先读入A的第1个小文件,依次与B的k 个小文件做去重比较,算法复杂度O(n^2)。
(2)遇到1个url时,计算Index = Hash(url) % m的值,将该url 写入到标号为Index 的小文件中,留意相同值的url会被写到同一个小文件中,以此去重,算法复杂度O(n)。
(3)先对文件A的url建立一个BloomFilter,在遍历文件B的url时判断是否存在于BloomFilter中,若是则删除,算法复杂度O(n),虽然具有一定错误识别率,但更节省空间,并且实际运行可能比方案(2)更快。
(注:在Linux中有特定命令可以完成2个文件的去重)
# 前提条件:两个文件不得有重复的行(即两个文件都要提前去重)
# uniq : 检查及删除文本文件中重复出现的行列。
# 语法:uniq[选项] 文件
# 最重要参数: 默认(去重) | -d(显重) | -u(删重)
# 1. 取出两个文件的并集
cat file1 file2 | sort | uniq >file3
# 2. 取出两个文件的交集
cat file1 file2 | sort | uniq -d >file3
# 3. 删除交集
cat file1 file2 | sort |uniq -u >file33. 应用场景:区块链
区块链中,如何判断一笔交易有效,除了需要提供默克尔树路径证明(证明其的确作为一笔历史交易存在于账本中,详细可参考:链接),还需要从一个双花交易池中判断该交易是否被双花。这里对问题进行建模,就变成判断交易x 是否存在于双花交易池集合中,我们可以通过BloomFilter实现该双花交易池,既省空间又保证判断效率。
这里额外提一下UTXO模型,很多人把账户式记账与UTXO记账搞混了,注意区块链是不会明确记录一个账户下有多少余额的(否则就没有隐私性了,不会有人愿意把自己的财产公之于众),那么UTXO是怎样实现资金流动的呢?举一个例子,假如A 付给C 5个比特币,B 付给C 2个比特币;若C 想付给D 6个比特币,它先把5个比特币支付给D ,再支付D 1个比特币,支付自己1个比特币。
在区块链系统中一般都是伪匿名性,例如:一个账户拥有多个盲化地址。想要实现完全匿名性其实也可以,具体可以参考NIZK 相关论文,虽然这种技术都是公开的,但是我们最好不要去实现,因为完全匿名性的比特币系统就可以拿来洗黑钱了,并且理论可证明的(理想环境下的)安全并不意味着实际生产的安全。















 2563
2563











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









