







1.引言
通常我们会遇到很多要判断一个元素是否在某个集合中的业务场景,一般想到的是将集合中所有元素保存起来,然后通过比较确定。链表、树、散列表(又叫哈希表,Hash table)等等数据结构都是这种思路。但是随着集合中元素的增加,我们需要的存储空间也会呈现线性增长,最终达到瓶颈。同时检索速度也越来越慢,上述三种结构的检索时间复杂度分别为O(n),O(logn),O(1)。这种时候,布隆过滤器就是一种比较好的解决方案了。
2.什么是布隆过滤器
布隆过滤器(Bloom Filter)其实是基于bitmap的一种应用, 1970 年由布隆提出。它由一个很长的二进制比特数组和一系列哈希函数构成,用于高效地检索数据是否存在。通俗的说可以把布隆过滤器理解为一个集合,我们可以往里面添加值,并且能判断某个值是否在里面。当布隆过滤器告诉我们某个值存在时,其实这个值只是有可能存在;可是它说某个值不存在时,那这个值就真的不存在。
3.工作机制

如图1 所示,初始化比特数组的值全为0,长度m=23,并假设有k=3个能把数据均匀映射到值域为 [0,m) 的哈希函数,经过一系列添值操作后,数组的值会散乱地被赋为1。我们先将数据a、b、c放入布隆过滤器,对a、b、c各自分别使用三个哈希函数得到映射值(即比特数组索引下标)。再根据下标将比特数组对应的值置为1,从而表示这三个数据已经存在。
然后我们用两个不曾被布隆过滤器标记的数据d、e模拟布隆过滤器的筛选过程。同样要使用前文设定的3个哈希函数,经散列得到比特数组索引下标,然后按下标查询得到对应的数组值。如果说3个索引值里出现了至少一个值为0,那么可以肯定的说这个数据肯定不存在,比如d。但是也会出现e这种情况,查得的值均为1,但是e明明不存在。其实出现这种情况的原因很好理解:那些被置为 1 的位置也可能是由于其他元素的操作而改变的。所以布隆过滤器存在假正率(False Positive)。
4.时间复杂度 空间复杂度
时间复杂度:在查找过程里,取值过程是直接查找,但是取值的次数等于哈希函数的个数成,所以时间复杂度为O(k),k为哈希函数的个数。另外哈希计算可以使用硬件加速,故查找效率很高。
空间复杂度:存储上,假设比特数组长度为m=10000000,则申请的内存大小为10000000bit=1250000B=1220.703125KB≈1.20MB≈0.001164GB。这在动辄内存8G起步的设备上,其实占用很小。
5.正确率和容错
首先对False positive概率进行推导:
假设 Hash 函数以等概率条件选择并设置比特数组中的某一位,m 是该位数组的大小,k 是 Hash 函数的个数,那么位数组中某一特定的位在进行元素插入时的 Hash 操作中没有被置位的概率是:

那么在所有 k 次 Hash 操作后该位都没有被置 "1" 的概率是:

如果我们插入了 n 个元素,那么某一位仍然为 "0" 的概率是:
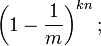
因而该位为 "1"的概率是:

现在检测某一元素是否在该集合中。标明某个元素是否在集合中所需的 k 个位置都按照如上的方法设置为 "1",但是该方法可能会使算法错误的认为某一原本不在集合中的元素却被检测为在该集合中(False Positive),该概率由以下公式确定:

其实上述结果是在假定由每个 Hash 计算出需要设置的位(bit) 的位置是相互独立为前提计算出来的,不难看出,随着 m (比特数组大小)的增加,False Positive的概率会下降,同时随着插入元素个数 n 的增加,False Positive的概率又会上升,对于给定的m,n,如何选择Hash函数个数 k 由以下公式确定:

此时False Positive的概率为:

而对于给定的False Positive概率 p,如何选择最优的位数组大小 m 呢,

上式表明,比特数组的大小最好与插入元素的个数成线性关系。
对于布隆过滤器不会漏报,但可能误报这个情况,我们当然希望准确度越高越好。

从上图可以看出,数据冗余量越大,哈希函数越多,错误率越低。但是总体来看,错误率控制在1%以内。
确定了正确率的问题后,接下来就是关键的容错了,怎么容错才算完美,既能解决问题,又能照顾容错成本呢?一方面由于布隆过滤器使用多个哈希函数进行处理,所以生成的值正常会均匀分布,数据不均衡从而造成数据稀疏时成本较高的问题就不存在了;另一方面,虽然说数据量增大超过预先设计的最大值也会对布隆过滤器造成影响,但是影响并不是很严重,除非差别过于巨大。因为实际数据量增大后,只会影响到上图m/n的值,带来的影响只是略微影响到布隆过滤器的正确率。
6.优点
- 增加和查询元素的时间复杂度为:O(K), (K为哈希函数的个数,一般比较小),与数据量大小无关
- 哈希函数相互之间没有关系,方便硬件并行运算
- 布隆过滤器不需要存储元素本身,在某些对保密要求比较严格的场合有很大优势
- 在能够承受一定的误判时,布隆过滤器比其他数据结构有这很大的空间优势
- 数据量很大时,布隆过滤器可以表示全集,其他数据结构不能
- 使用同一组散列函数的布隆过滤器可以进行交、并、差运算
7.使用场景
布隆过滤器被广泛用于数据量庞大的情况下的查询、去重等业务,比如:
- 黑名单过滤
- 垃圾邮件过滤
- 爬虫判重系统
- 推荐系统去重
- 缓存穿透
- 区块链的SPV支付
- Web拦截器
- ……
8.缺点
- 有误判率,即存在假正率,即不能准确判断元素是否在集合中
- 不能获取元素本身
- 一般情况下不能从布隆过滤器中删除元素
- 随着使用的时间越来越长,因为不能删除,存进里面的元素越来越多,占用内存越来越多,误判率越来越高,最后不得不重置。
- 如果采用计数方式删除,可能会存在计数回绕问题
- 数据量过于庞大时,计算机内存也会进行频繁的页面置换(这个其实不独属于布隆过滤器的缺点)
9.总结
总体来说,布隆过滤器是一个很有意思的数据结构,空间效率和查询时间都远远超过一般的算法。目前已经在业务中广泛使用,比如常用的redis里已经集成了布隆过滤器。本篇只是就最基本的布隆过滤器做了介绍,在具体应用中,布隆过滤器还有更多的有趣的功能和进一步改进的数据结构。朋友们可以亲自coding一下,比如尝试一下redis的布隆过滤器,或者尝试给布隆过滤器实现删除数据的功能等等。
9.Reference
布隆过滤器 - 维基百科,自由的百科全书 (wikipedia.org)
详解布隆过滤器的原理、优缺点_一只快乐的野指针吼的博客-CSDN博客_布隆过滤器原理
布隆过滤器,这一篇给你讲的明明白白-阿里云开发者社区 (aliyun.com)
布隆过滤器及其使用场景 - Master HaKu - 博客园 (cnblogs.com)
Redis布隆过滤器(原理+图解) (biancheng.net)
布隆过滤器(Bloom Filter)详解 - 李玉龙 - 博客园 (cnblogs.com)
Merkle Tree、Merkle Proof、SPV安全性分析、Bloom过滤器_真·skysys的博客-CSDN博客















 1419
1419











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









