






VLAN间多层路由
CISCO提供多种解决方案来获得VLAN间路由选择的功能。
VLAN是一种端口的逻辑组合,这些端口通常属于用于控制广播域的大小的单个IP子网,因为VLAN能将流量隔离到确定的广播域和子网中,所以不同VLAN中的设备之间是不能互访的。
交换机二层接口类型:
接入接口:承载单个VLAN流量。
干道接口:通过使用ISL或802.1Q标记,承载多个VLAN流量。
3550和4500交换机默认使用2层接口,6500交换机默认使用3层接口。
交换机三层接口类型:
路由端口:类似普通路由器的端口
SVI(Switch Virtual interface):VLAN间路由选择的虚拟VLAN接口,SVI即虚拟路由的VLAN接口
BVI(Bridge virtual interface):第三层虚拟网桥接口
1.路由端口:是交换机上的一种物理端口,类似于传统路由器上配置了第三层地质的接口,与二层接入端口的区别是,路由端口不与特定VLAN相互关联,此种端口与真正的路由端口的区别是不支持子接口。
2.SVI(交换机虚拟接口):是一种第三层接口,为了在多层交换机上完成VLAN间路由选择而配置的接口。SVI是一种与VLAN-ID相关联的虚拟VLAN接口。
三层交换机VLAN间路由方式:
1.SVI:
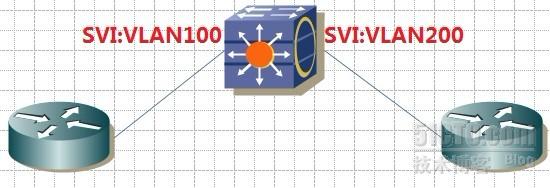
两台设备分属不同的VLAN,网关设置为SVI接口。
2.路由接口:
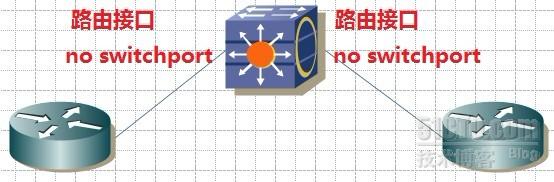
3.单臂路由:
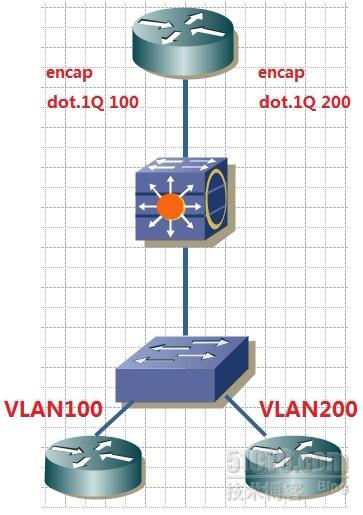
MLS:
普通的MLS是基于flow做的,称之为一次转发,多次交换,基于cache的
CISCO的MLS是基于CEF的,基于拓扑式的驱动。
路由表,不能被硬件所调用,
FIB可以被硬件所调用
普通MLS和CEF的区别
show ip cef 查看FIB表
show adjacency detail 查看邻接关系表
实际上adj表中的MAC地址,指的是源目MAC地址加上TYPE字段0800
当使用SVI口 网关的时候,MAC地址实际上是BASE的MAC地址加上端口号所形成的端口MAC地址。
多层交换的好处:能够让IP包的转发速度达到接近二层交换的速度。
SW要执行多层硬件交换,路由处理器(第3层引擎)必须将有关路由选择、交换、ACL和QOS等信息下载到硬件中。
硬件组件通常包括下列的东东:
ASIC(Application-Specific Integrated Circuit应用专用集成电路):是专为实现某种特殊应用而开发的集成电路芯片,其功能固定,不可更改。用来实现其专门的应用时,性能绝对牛得一B。
CAM(Content Addressable Memory)内容可寻址存储器
SW使用CAM表来存储2层的交换表。查找时是完全匹配,如果找不到,就从其他所有端口转发。
对于需要精确查找的表最有用。CAM表包括了vlan号,mac地址,port号。
TCAM(Ternary CAM)三重内容可寻址存储器,只存在于三层交换机中
TCAM以线速处理ACL查找。
完全匹配区域/最长匹配区域/第一个匹配区域
对于需要最长匹配查找的表最有用。
三种三层(IP包)的转发方式:
进程交换:
也叫软件转发,最原始的转发方式。在进程转发方式中,每一个IP包的转发都需要CPU来处理,没有额外的硬件组件来负责。
对于接收到的每一个IP包,都要按以下步骤来转发:
1、找出IP包中的目标IP地址
2、按照目标IP地址在路由表中进行最长匹配查找,找到匹配的路由。
3、有必要的话,再进行路由的递归查找,找到相应的出接口。
4、再查找ARP表,找到去往下一跳的MAC地址。
5、重写二层的源、目MAC地址,再从相应出接口转发出去。
这是最传统的转发方式,使用这种转发方式的路由器在做负载均衡时是基于包的负载均衡
R1(config-if)#no ip route-cache 在每个接口下关闭cache就启用了进程交换
基于NetFlow的MLS:也叫传统的MLS
基于网流的交换和负载均衡
MLS使用ASIC能够对被路由的数据包执行2层重写(S/D MAC、CRC)。
第三层引擎(路由处理器)和交换ASIC协同工作,在cache中建立第3层条目。第三层条目可以有如下三种方式:
1、只包括目的IP地址
2、包括源和目地IP地址
3、包含第四层协议信息的完整流信息
传统MLS的工作原理:
交换机将收到的数据流中的第一个包交给三层引擎处理,后者以进程交换的方式处理(软交换)。在对第一个包处理完毕后,在硬件交换组件中生成一个MLS条目,这个条目包含了二层的重写信息。对于后续的数据流就可以使用硬件转发组件直接进行转发了。
所以这种方式被称为“一次路由,多次交换”,即流的第一个分组被路由器软件路由,后续分组则被硬件转发。
基于CEF的MLS:(Cisco Express Forwarding)
控制平面:路由处理器(第3层引擎)
数据平面:用来进行数据转发的硬件组件
CEF是一种基于拓扑的转发模型,它预先将所有路由信息加入FIB(Forwarding Information Base),使SW能快速查找路由信息。
CEF中包括两个重要组件:
FIB:类似于路由表,包含了路由转发信息。
Adjacency:存储2层编址信息。就是ARP表的一个COPY。
第3层引擎和硬件交换组件维护一个FIB/Adjacency。
ARP Throttling(ARP抑制)必须开启CEF才能开启这一功能
ip routing //要开启CEF,首先要开启路由功能
ip cef //开启CEF
int f0/5
no ip router-cache cef //在接口下关闭CEF
show ip cef
show cef interface s0
show adjacency [detail]
ARP Throttling(抑制)--对于启用CEF的交换机,如果收到一组数据包,但是在自已的Adjacency表中没有对应表项。将通过第三层引擎发出三个ARP请求(广播包),并开始对后续的数据包进行抑制,只到收到ARP回应才解除抑制。如果两秒钟以后还没有回应,也将解除抑制,把后续的数据包转发给第三层引擎来重新发起ARP请求。
默认情况下CEF是基于流的负载均衡,但可以修改为基于包的负载均衡:
R1(config-if)#ip load-sharing per-packet 打开基于包的负载均衡
集中式交换和分布式交换:
Centralized Forwarding(集中式转发)
在一个专用ASIC上做出转发决策,是所有接口的枢纽。
Series:4000/6500
Distributed Forwarding(分布式转发)
在SW的接口或线路模块上独立地做出转发决策。
Series:3550/6500(带有分布卡)
转载于:https://blog.51cto.com/zhangchiccie/723813















 9060
9060











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









