







课程来自Coursera上的国立台湾大学《机器学习基石》(Machine Learning Foundations),由林轩田老师讲授。
如何设定目标函数集
首先回顾下机器学习的一般性定义:
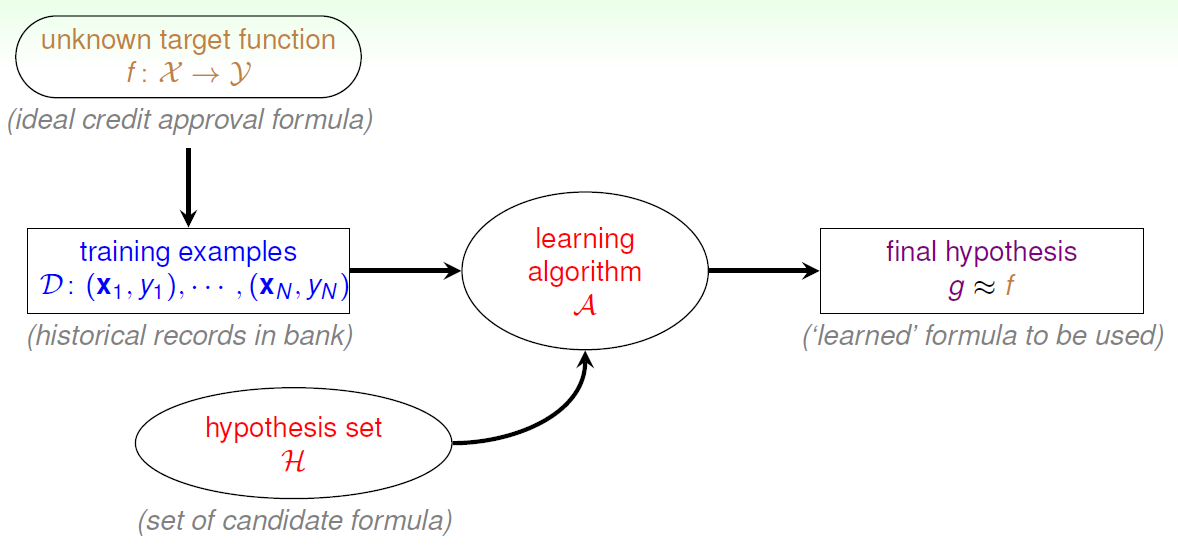
集合{χ}是所有可能的输入,集合{η}是所有可能的输出,函数f是{χ}到{η}的一个映射,这个函数利用输入得到正确的输出。问题是我们不知道f的形式,我们手头有的只是一些经验数据D,是不是可以通过一个学习算法A从备选函数集H中找到一个函数g,使它在训练数据D的范围内保证得到正确的结果,此时我们认为g是对f的一个可接受的近似。
以信用卡问题为例解释如何设定备选函数集:
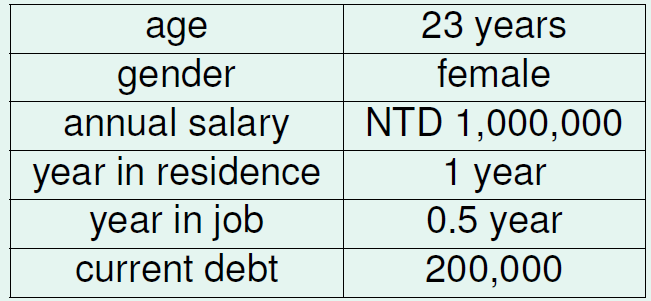
一个客户,他的数据可用一个特征向量表示:

备选函数集H以权向量w作为变量,取不同的权重组合,就得到不同的备选函数。
感知器学习算法(Perceptron Learning Algorithm , PLA)
用图形的方式表示备选函数集:


为了简化,这里假设用户特征向量只有2维,即影响发卡的因素只有两个(x1,x2),因此每个特征向量都能表示成平面上的一个点。将历史数据一一绘制出来就得到上面的图,图中蓝色圆圈代表发卡的用户,红色的叉代表不发卡的用户,一个正确的权向量应当构成一条直线,在平面上将圈和叉划分开来。
因为是在实数域取值,理论上权向量w有无穷多个,H(w)随着w的变化也有无穷多个备选函数,该如何选取近似目标函数g?
教程给出的方法是,首先给定一个初始函数g0(或一个初始权向量w0),如果该直线对样本的划分出现错误,我们就纠正它(纠正w0)并重复这个过程直到正确的划分出现。

用数学语言描述这个过程:

以上就是一个完整的PLA算法,也就是那个从备选函数集合H中挑选函数g的算法,至于为什么叫“感知器”,我也不知道。。
PLA算法的可行性
这个算法正确与否关键在第2步,如果每次纠正都让w更加接近目标函数,那么迟早会得到g函数的。
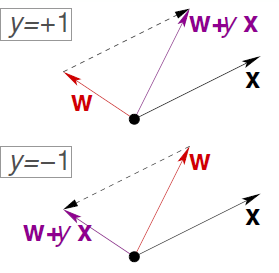
根据上图,由于权向量w是分割线的法向量,无论发生错误的点是正值还是负值,经过修正后的分割线调整了方向从而向错误点靠拢,就是说它更加接近那条完美的分割线。
补充,我认为教程中有个关键概念没解释清楚:
在构建备选函数集的时候扩充了客户的特征向量:

(因为没搞清这个概念,后来在做课后题的时候程序设计出现错误,在权向量中增加一个维度可以调整直线的截距,否则只能调整角度,可能导致迭代不收敛!)
看起来不错吧?逻辑进展到这一步还不能自圆其说,因为它引入了新的问题:
--- 修正一定会停止吗?修正的次数可预测吗?
--- 得到的g函数一定是对目标函数f的正确近似吗?在训练数据集D上也许是,那么在D之外呢?

容易推测,想让PLA算法可停止,必须能够找到至少一条直线将训练数据集D划分成正值和负值两个部分,即必须有无错的权向量存在。这样的D我们称它为“线性可分”的。
综上,D线性可分是PLA停止的必要条件,那么他是充分条件吗?即如果D线性可分,PLA一定会停止吗?
证明如下:

通俗的说就是,如果D里面的数据能划分,就一定能找到那条(其实有无数条)划分线;此时,在D里面随便选一个点,它一定处在划分线的某一侧(不是直线上),并且这一侧所有其他点的计算符号都与它相同,所以这些点到直线的距离大于零(不等式(1)的意义);根据这些条件得到不等式(2),它告诉我们权向量就像11点50的分针,近似目标向量就像同一时刻的时针,每一次修正,分针都离时针更近了!
但是还不够完美,数学好的童鞋讲,向量内积不仅反映了向量的角度还反映了其长度,两个向量就算夹角不变,只要长度变化,内积也可以增大!
不错,权向量的长度会怎么变化,推导如下:

可以看到,修正之后权向量的长度,相较于修正之前的增加有一个上限,或者说它的长度增长是较慢的。这个上限由D中距离坐标原点最远的那个点决定。
以零向量作为初始权向量,经过t次修正后,有:
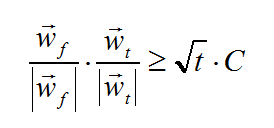
这个不等式说明在排除了长度因素后,随着修正次数的增加,权向量在角度上越来越接近近似目标向量。
(教程中直接给出了这个公式,本人尝试证明未果,mark一下)
如果D不是线性可分(包含干扰数据)?

非常有可能遇到这样的情况,无论怎么修正权向量,总有错误的点存在。
如果错误的点数量很少,就能找到一条直线,使得大部分点都处在正确的一侧,此时计算误差很小,得到的函数g是可接受的。
那么,能不能找到一条直线,它是所有可能直线当中犯错误最少的?很难,因为可能的直线太多了,你必须完整遍历一遍之后才能找到最优解,这是数学上的NP-hard问题。
妥协的结果:口袋算法(Pocket Algorithm)。

像不像狗熊掰棒子?在一块一望无垠的玉米地里,一只狗熊想掰到最大的那个。它先掰了一个拿在手里,然后随手掰了下一个,如果这个比上一个大,就把上一个扔了,把这个拿在手里,反之就把这个扔了,还拿着上一个。掰了一下午,熊妈妈喊它回家吃饭了,于是它带着目前为止最大的那个棒子高高兴兴回家了。















 1729
1729











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









