







1、介绍
AC自动机实现的是多模式串匹配算法
1、借助于字典树存储
2、通过失败指针快速,实现查找失败后,快速跳到下一个起始点,而不是root点开始查找 失败指针确保:失败指针节点反向到root的路径,已经包含在匹配传中了。
3、如果失败指针的节点是叶子节点,则它的值会被加载到指向它的节点set<>中,正因为如此, 才会有多模式匹配功能
2、图型介绍
例子:给出5个单词,say,she,shr,he,her。给定字符串为yasherhs。问多少个单词在字符串中出现过
组成的字典树trid
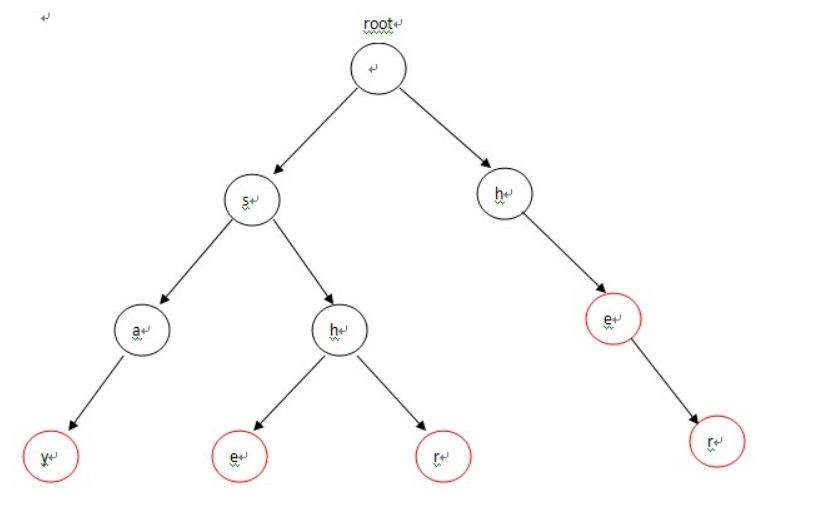
查找每一个节点的失败指针
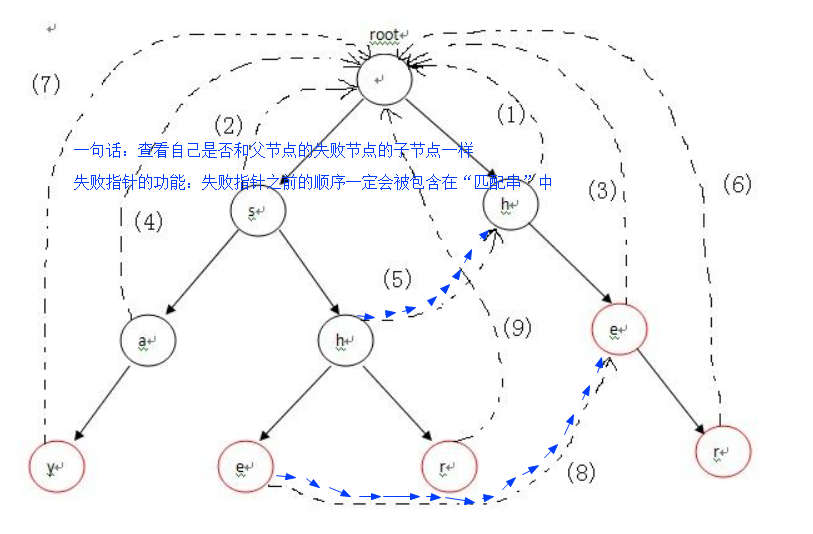
she包含her中的h,she包含her中的he
3、代码实现
-
1、字典树节点TridNode
import java.util.List; /** * 字典树节点 * * [@Author](https://my.oschina.net/arthor) liufu * [@E-mail](https://my.oschina.net/rosolio): 1151224929@qq.com * @CreateTime 2019/3/1 14:39 */ public class TridNode<T> { private byte value; //这个value是key的一个个byte值 private TridNode prearentPoint; //父节点,是为了找到失败指针 private TridNode failPoint; //这是失败指针,父节点失败指针节点的子节点是否一样 private List<TridNode> childList; //所有的孩子节点 private List<T> resultSet; //结果集合,用于保存 public TridNode() { } public TridNode(byte value) { this.value = value; } public byte getValue() { return value; } public void setValue(byte value) { this.value = value; } public TridNode getPrearentPoint() { return prearentPoint; } public void setPrearentPoint(TridNode prearentPoint) { this.prearentPoint = prearentPoint; } public TridNode getFailPoint() { return failPoint; } public void setFailPoint(TridNode failPoint) { this.failPoint = failPoint; } public List<TridNode> getChildList() { return childList; } public void setChildList(List<TridNode> childList) { this.childList = childList; } public List<T> getResultSet() { return resultSet; } public void setResultSet(List<T> resultSet) { this.resultSet = resultSet; } } -
2、包含AC自动机功能的字典树实现
package com.java.project.acmatchmyself; import java.time.Instant; import java.util.LinkedList; import java.util.List; import java.util.concurrent.BlockingQueue; import java.util.concurrent.LinkedBlockingQueue; /** * 借助字典树和失败指针实现AC自动机算法,进行多模式串匹配功能 * 同时实现了全匹配,以及左前缀匹配,构不构建失败指针都可以 * * [@Author](https://my.oschina.net/arthor) liufu * @E-mail: 1151224929@qq.com * @CreateTime 2019/3/1 14:39 */ public class TridForAc<T> { private TridNode<T> root; private int deep; public TridForAc() { //根节点没有failPoint,也没有preaentPoint root = new TridNode<T>(); } public int getDeep() { return deep; } /** * 给定byte[]和value,将key构建在树中 * 同时把结果保存在叶子节点的resultSet中 * <p> * 注意点:在需要用到pareatNode的childList时才需要判空创建 * * @param key * @param value * @return * @throws Throwable */ public boolean addNode(byte[] key, T value) { int i = 0; int length = key.length; TridNode parentNode = root; /** * 在树中顺序层级匹配key的byte * 如果树中包含整个key,则parentNode就是最后的那个叶子节点 */ while (i < length) { TridNode temp = findChildNode(parentNode.getChildList(), key[i]); if (temp == null) { break; } parentNode = temp; i++; } /** * i < length说明树只包含了key的一部分,需要将剩下的一部分构建到树中 * 构建后,parentNode肯定就是最后的那个数据叶子节点 * 注意:如果上面包含所有key,则i == length,此代码不跑 */ while (i < length) { TridNode<T> node = new TridNode<>(key[i]); //如果父节点没有childList,new 一下 List childList = parentNode.getChildList(); if (childList == null) { childList = new LinkedList<>(); parentNode.setChildList(childList); } childList.add(node); node.setPrearentPoint(parentNode); parentNode = node; i++; } //到这里了,parentNode必须是那个最终的叶子节点 List resultSet = parentNode.getResultSet(); if (resultSet == null) { resultSet = new LinkedList(); parentNode.setResultSet(resultSet); } resultSet.add(value); return true; } /** * 构建失败指针 * 失败指针的作用是确保:root到失败指针这的部分key一定会在匹配串中 * * @return */ public boolean buildFailPoint() { BlockingQueue<TridNode> queue = new LinkedBlockingQueue<>(); //从第二排开始遍历即可,不需要处理root //因为root节点特殊,没有父节点,也没有失败指针 //如果不排除这个root节点,下面会引起死循环 List<TridNode> nodeList = root.getChildList(); if (nodeList != null && nodeList.size() > 0) { queue.addAll(nodeList); } while (!queue.isEmpty()) { TridNode node = queue.poll(); TridNode failPoint = node.getPrearentPoint().getFailPoint(); //判断父节点的失败指针的子节点是否存在此节点 while (failPoint != null) { TridNode failPointTemp = findChildNode(failPoint.getChildList(), node.getValue()); //找到自己的失败指针 if (failPointTemp != null) { node.setFailPoint(failPointTemp); break; } else { //否则继续找失败指针的失败指针,直到root为止(root的failPoint == null) failPoint = failPoint.getFailPoint(); } } if (node.getFailPoint() == null) { //说明一直到root都没有找到失败指针 node.setFailPoint(root); } List childList = node.getChildList(); if (childList != null && childList.size() > 0) { queue.addAll(childList); } } return true; } /** * ac多模式串匹配,前提是要进行失败指针构建 * * @param key * @return */ public List<T> acSearch(byte[] key) { List<T> result = new LinkedList<>(); int length = key.length; TridNode temp = root; for (int i = 0; temp != null && i < length; i++) { List childList = temp.getChildList(); if (childList != null) { TridNode childNode = findChildNode(childList, key[i]); if (childNode != null) { //当前查找路线能够找到,继续往下找 // 匹配上的节点结果加入到result中 List resultSet = childNode.getResultSet(); if (resultSet != null) { result.addAll(resultSet); } // 将所有失败指针节点的值拿过来 result.addAll(findFailPointResult(childNode.getFailPoint())); temp = childNode; } else { //当前查找路线找不到,则跳到失败指针,继续找 temp = temp.getFailPoint(); } } } return result; } /** * 全匹配,就是输入abcdef,那么字典树中就必须要要有abcdef这个key才能匹配出来 * 不要构建失败指针 * * @param key * @return */ public List<T> fullSearch(byte[] key) { List<T> result = new LinkedList<>(); int length = key.length; boolean matchFlag = true; TridNode temp = root; for (int i = 0; temp != null && i < length; i++) { List childList = temp.getChildList(); if (childList != null) { TridNode childNode = findChildNode(childList, key[i]); if (childNode != null) { //子节点能够找到,继续往下找 temp = childNode; } else { matchFlag = false; break; } } } /** * 能够全部匹配上,说明字典树中有一个key包含这个匹配key * 如果字段数的key是完整key,那么在最后那个节点上会有结果 * 比如:匹配key ==> abcd , 字典树key ==> abcd 的d节点的resultset会包含结果 * 如果字段数key ==> abcde,那么e节点保存结果,而不是d结果,这个时候也是没有结果出来。 */ if (matchFlag) { List set = temp.getResultSet(); if (set != null) { result.addAll(set); } } return result; } /** * 前缀匹配,比如输入abcdef,那么字典树中有abc, abcd, abcde, abcdef这样的关键字可以匹配出来 * 不要构建失败指针 * * @param key * @return */ public List<T> preSearch(byte[] key) { LinkedList<T> result = new LinkedList<>(); int length = key.length; TridNode temp = root; for (int i = 0; temp != null && i < length; i++) { List childList = temp.getChildList(); if (childList != null) { TridNode childNode = findChildNode(childList, key[i]); if (childNode != null) { //子节点能够找到,继续往下找 List set = childNode.getResultSet(); if (set != null) { result.addAll(set); } temp = childNode; } } } return result; } /** * 判断孩子节点中是否存在这个节点 * * @param childNodes * @param nodeValue * @return */ public TridNode findChildNode(List<TridNode> childNodes, byte nodeValue) { if (childNodes != null) { for (TridNode next : childNodes) { if (nodeValue == next.getValue()) { return next; } } } return null; } /** * 沿着失败指针找到失败指针节点的值 * 其实可以在构建失败指针的时候就把这些节点拿过来,储存在一起 * 但是会影响前缀匹配和全匹配,而且损耗空间 * * @param failPointNode * @return */ private List<T> findFailPointResult(TridNode failPointNode) { LinkedList<T> result = new LinkedList<>(); while (failPointNode != null) { List<T> temp = failPointNode.getResultSet(); if (temp != null && temp.size() > 0) { result.addAll(temp); } failPointNode = failPointNode.getFailPoint(); } return result; } public static void main(String[] args) { TridForAc<String> ac = new TridForAc<>(); ac.addNode("a-b-c-d".getBytes(), "abc1"); ac.addNode("b-c-d".getBytes(), "abc2"); ac.addNode("c-d".getBytes(), "abc3"); /** * 构建失败指针,即使全匹配和最左前缀匹配也没又问题 * 因为没有把失败指针的结果拿过来 */ ac.buildFailPoint(); // 全匹配和前缀匹配都不需要构建失败指针,纯粹是多叉树操作 List<String> fullSearch1 = ac.fullSearch("a-b-c-d".getBytes()); List<String> fullSearch2 = ac.fullSearch("a-b-c-f".getBytes()); List<String> preResult = ac.preSearch("b-c-d-xx-xx-xx".getBytes()); // 查找100W次,耗时386ms,性能强大 int i = 0; long start = Instant.now().toEpochMilli(); while (i < 1000000) { List<String> search = ac.acSearch("a-b-c-d".getBytes()); i++; } System.out.println(Instant.now().toEpochMilli() - start); } }
4、总结
1、构建字典树。只需要注意root节点不要设置preaentPoint 和 failPoint,否则会在构建FailPoint的时候导致死循环。
2、查找失败指针。父节点的失败指针的子节点中值相等的节点,如果没有,继续找失败指针的失败指针,知道root为止,此时root就是失败指针 叶子节点需要记录resultSet,同时指向失败指针的节点 也要记录失败指针的resultSet。
3、多模式匹配。只需要走一次,累计每一层的匹配的节点resultSet,如果子节点找不到,则跳转到失败指针节点继续查找。
字典树的优点:利用字符串的公共前缀来减少查询时间,最大限度地减少无谓的字符串比较,查询效率比哈希树高。















 239
239











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









