







<?xml version="1.0" encoding="UTF-8" ?>
</列车时刻表>
要讨论的是下面两个XPath路径表达式:
第一个:/列车时刻表/列车/始发站[position()=1]
第二个: (/列车时刻表/列车/始发站)[position()=1]
两者的区别是第二个是第二个多了个括号。
先来看看API解析的结果:
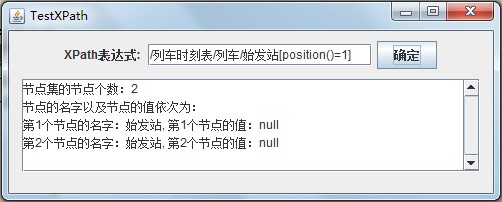
第一个表达式的解析结果:
第二个表达式的解析结果:

两者的解析结果的区别在于,第一个表达式所返回的节点集中含有2个节点(名字都为“始发站”,其中一个的内容是"北京“,而另一个的内容是沈阳);第二个表达式所返回的节点集中仅含有1个节点集(名字为“始发站”,内容是"北京“)。
下面来分析一下这两个表达式的差异。
先来说第二个表达式,因为它比较容易理解:(/列车时刻表/列车/始发站)[position()=1],首先解析的是括号中的路径 (/列车时刻表/列车/始发站) 解析结果中得到了2个节点(名字都为“始发站”,其中一个的内容是"北京“,而另一个的内容是沈阳),然后再处理谓词[position()=1],筛选得出上述结果中的第一个节点,即内容为“北京”的名字为“始发站”的节点。所以整个表达式结果中仅包含1个节点(名字为“始发站”,内容是"北京“)。
现在再回头看第一个表达式/列车时刻表/列车/始发站[position()=1],如果不看它的谓词[position()=1]的话,/列车时刻表/列车/始发站 返回一个包含2个节点的节点集(名字都为“始发站”,其中一个的内容是"北京“,而另一个的内容是沈阳),如果加上它的谓词[position()=1],需要单独地看这2个“始发站”节点中的每一个,筛选的条件是,其中的每一个都必须分别是相对于其所在的父元素“列车”元素下的,名为“始发站”的子元素集合中的第1个。如图所示:

由于每个“列车”元素下都有且仅有一个“始发站”元素,所以如果把表达式改为
/列车时刻表/列车/始发站[position()=2]
的话,结果将返回0个节点,如下图所示,因为在一个“列车”元素中不存在第二个“始发站”的元素。
















 302
302











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









