






master存活的状态下切换
masterha_master_switch --conf=/etc/masterha/app1.cnf --master_state=alive --new_master_host=192.168.0.101 --orig_master_is_new_slave --running_updates_limit=1000
不出意外的情况下,会报下面的错误:

查看源代码:

在新master上获取正在执行的进程,也就是show processlist操作。并且将获取到的processlist信息进行分析判断,如果新master当前还存在binlog dump或binlog dump gtid进程等,则无法切换。
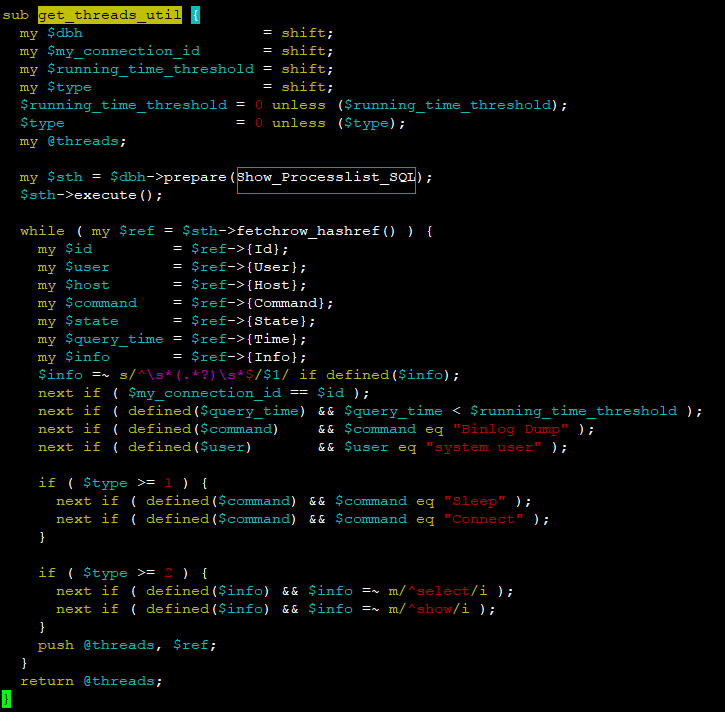
源码 DBHelper.pm片段

报错的原因是切换成功后,原master变成了slave,而新slave上的binlog dump gtid线程并没有没停掉,理论上切换成功后,由于角色的转换,原master变成slave,binlog dump gtid进程应该停止运行的,为什么没有被停止掉呢?

查看新master上的报错日志。

连接丢失,原来是连接丢失导致slave没接收到信号,所以进程没有被停掉。
该问题可以通过配置主从同步心跳检测时间来提前触发主从检测,从而达到slave上的binlog dump gtid进程提前停止。系统默认主从检测时间是3600S。
配置如下,在可能会成为master的slave上执行
stop slave;
change master to master_heartbeat_period = 10;
set global slave_net_timeout = 25;
start slave;
在当前主上执行
change master to master_heartbeat_period = 10;
set global slave_net_timeout = 25;
可以直接配置在配置文件中
slave_net_timeout = 25
再次手动切主的时候就发现binlog dump gtid进程很快就被清理了,也不会报错了。

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









