







服务器压力较大时,如何判断压力来源?如何进行优化?什么是IO密集型?啥是计算密集型?通过这篇了解一下架构设计时会遇到的性能分析的基础知识吧。
基础知识
首先说明,IO密集 与 计算密集 为两个相对概念,这个得从冯·诺依曼计算机结构体系说起。

运算器与控制器 又被称为中央处理器,即 CPU ( Center Process Unit )
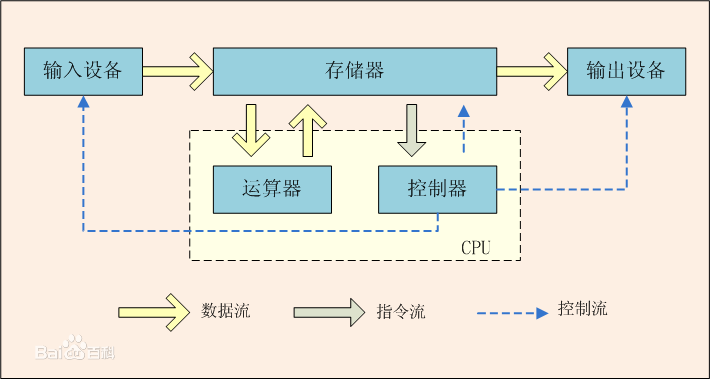
存储器又可分为 内存与外存
CPU, 存储器, 输入(I)、输出(O)设备等接口设备均通过 系统总线 连接在一起。
啥是系统总线?大学学习的时候,都会提到这个名词,仿佛它就是个概念而已,其实,系统总线(Bus),就可以粗略地理解为总线就是主板好了。
在总线上一般有两个独立的单元不常在计算机原理中提及到,就是南、北桥芯片(即DIY时常提及的芯片组),具体的内容可以百科一下。
北桥芯片,离CPU最近,一般都贴有散热片,也称为主桥芯片(Host Bridge),一般来说,芯片组的命名就是以北桥芯片的名称来命名的。主要负责总线上的高速设备比如AGP、PCI-e、内存等与CPU的数据高速交换。
南桥芯片,相对北桥芯片,离CPU较远,一般不会贴散热片。主要负责中低速外部设备比如USB、PCI、IDE、Sata、网卡等,芯片中集成了中断控制器、DMA控制器。
由此可见,负责给CPU提供数据的在总线上,还有两个管家,一个大内总管(北桥),一个外掌柜(南桥)。
好的,弯子绕回来,说正题
如何判定
待完成…
I/O bound (I/O 读写密集型) 指的是系统的CPU效能相对硬盘/内存的效能要好很多,此时,系统运作,大部分的状况是 CPU 在等 I/O (硬盘/内存) 的读/写,此时 CPU Loading 不高。
CPU bound (CPU 计算密集型) 指的是系统的 硬盘/内存 效能 相对 CPU 的效能 要好很多,此时,系统运作,大部分的状况是 CPU Loading 100%,CPU 要读/写 I/O (硬盘/内存),I/O在很短的时间就可以完成,而 CPU 还有许多运算要处理,CPU Loading 很高。
在多重程序系统中,大部份时间用来做计算、逻辑判断等CPU动作的程序称之CPU bound。例如一个计算圆周率至小数点一千位以下的程序,在执行的过程当中。绝大部份时间用在三角函数和开根号的计算,便是属于CPU bound的程序。It is because the performance characteristic of most protocol codec implementations is CPU-bound, which is the same with I/O processor threads.
根据以上分析,可以认为通常情况下,大部分程序针对某个特定的性能metric而言,都可分为CPU bound 和 I/O bound两类。CPU bound的程序一般而言CPU占用率相当高。这可能是因为任务本身不太需要访问I/O设备,也可能是因为程序是多线程实现因此屏蔽掉了等待I/O的时间。而I/O bound的程序一般在达到性能极限时,CPU占用率仍然较低。这可能是因为任务本身需要大量I/O操作,而pipeline做得不是很好,没有充分利用处理器能力。
如何优化
话说,网卡、硬盘都由南桥芯片控制,并属于中、低速设备,所以,在服务器上进行网络通讯、网络传输、磁盘读写均受南桥控制,此类即为IO操作。IO密集型服务/业务即是以网络请求压力大、磁盘读写频繁的操作类型,当进行这些IO密集型操作时,CPU的负载相对较低(现代计算机均集成了对硬件访问控制的操作逻辑,使得CPU从这些操作中解放出来,提高核心资源的利用率)。
计算密集型,可以理解为在北桥芯片与CPU之间的通讯较高的服务/业务,往往这类操作常见的都是以计算为主的,而计算又是CPU/GPU的专长,没听说过哪个硬盘可以进行计算(当然,声卡或硬解压卡应该属于例外了,在南桥将媒体的数据流通过总线传递给声卡或是硬解压卡,而声卡和硬解压卡通过烧录在卡上的解码器进行硬件级别的编码处理,最终总处理后的数据流通过卡上的接口传给输出设备,比如声卡传递给音箱)。
对于服务器,通过开发的服务或是业务,可以在项目之初就根据需求来对资源进行预先估算,大致属于IO密集型还是计算密集型的业务,并进行项目前期的资源预算等工作的开展,也包括前期的设计和后期的优化。
1. 项目立项过程中,根据需求对应的资源负载类型,提出对服务资源的需求配置
IO密集型的需求,一般来说,如果是磁盘读写频繁,通过对磁盘进行升级,提高磁盘的响应速度和传输效率或通过负载技术,将文件读写分散到多台服务器中;如果是网络请求负载较高,可以通过负载均衡技术,水平扩展服务,提高负载能力;或使用代理缓存服务器,降低核心服务的负载压力。
计算密集型的需求,首先可以考虑使用计算能力更好的CPU,然后考虑通过消息队列或其它降维算法,将计算分散的不同的计算结点,进行处理。
2. 项目开发时,进行合理的规划和业务开发
对于IO密集型的需求,在开发过程中,就要考虑尽可能减少IO开销,对磁盘读写频繁的业务,可以考虑通过内存缓存将热数据缓存起来,减少磁盘的请求。
对于计算密集型的需求,在开发过程中,需要注意计算算法的优化及结果重用,并尽可能进行降维处理,比如通过某种算法将原业务需求的计算分散成可拆分的逻辑,并分散计算进行结果求解,最后进行组合(很像现在大数据处理里的一些模式,可以参考),或通过消息队列将大量的计算请求分发到其它的计算结点上去。
3. 项目上线后,对服务资源调配进得合理的优化
上线后对服务资源需要持续监控并根据业务推广和实际情况进行优化处理。
思路上致上也同上述情况。
总结
待处理的数据离CPU越近,处理越快。
启动线程数 = [ 任务执行时间 / ( 任务执行时间 - IO等待时间 ) ] x CPU内核数 最佳启动线程数 和 CPU内核数量 成正比,和IO阻塞时间成反比。 如果CPU计算型任务,那么线程数最多不超过CPU内核数,因为启动再多线程,CPU也来不及调度; 相反如果是任务需要等待磁盘操作(即IO密集型),网络响应,那么多启动线程有助于提高任务并发度,提高系统吞吐能力,改善系统性能。
引用参考
参考文档
- 《 计算机的组成及结构 》
- 《 南北桥芯片的作用 》
- 《 南北桥芯片 》
- 《 南北桥 》
- 《 电脑主板的南北桥芯片,为什么要分南北桥? 》
- 《 哈佛结构和冯·诺依曼结构的区别 》
扩展阅读
- 《 冯诺依曼体系和哈佛体系 》
- 《 哈佛&冯诺依曼及其他区别 》
- 《 人工智能的突破需要颠覆图灵机吗? 》
- 《 图灵机与现代计算机的关系 》
- 《 一个能够让你明白图灵机的例子 》
- 《 图灵机 》
- 《 数据密集、计算密集、IO密集,hadoop如何应对? 》
- 《 TPS、并发用户数、吞吐量关系 》
参考链接: http://ju.outofmemory.cn/entry/214931















 2987
2987











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









