







ZeroMQ无锁队列分析
1. 概述
ZeroMQ使用了一个无锁队列,用于线程间的高性能数据交换。这个无锁队列由两个对象组成:
- yqueue_t: 一个普通的队列,实现内存块链表,以及内存块的回收和重复利用。
- ypipe_t: 基于yqueue_t实现的无锁管道队列,实现一读一写的无锁操作。
2. yqueue_t类
yqueue_t类实现了一个普通的队列(多线程不安全),但为了提高性能,使用了内存块链的方式,每个内存块可支持多个数据元素节点。
- begin_chunk: 队列第一个内存块。
- end_chunk: 队列最后一个内存块。
- begin_pos: 队列中第一个元素在第一个内存块中的位置。
- end_pos: 对垒中最后一个元素在最后一个内存块的位置。
同时为了减少内存的分配、释放操作,yqueue_t中包含了一个spare_chunk,存放一个空闲的内存块。该spare_chunk的首节点指针使用atomic变量存放,实现spare_chunk中存取的线程安全。
2.1 push操作
push操作实现向队列中增加一个空元素,此后可使用back方法获取新增元素的引用,然后将数据填入。简要操作过程:
// end pos后移, 如果达到当前chunk末尾,就新增一个chunk.
// 获取新chunk,可以从spare_chunk获取,也可能是重新内存分配。
if ( ++end_pos = N )
create new_chunk;
end_chunk = move_next;
end_pos = 0;
endif
2.2 pop操作
pop操作实现队列前端的后移,最前元素被移出队列。
if ( ++begin_pos = N )
delete begin_chunk; // begin chunk取空后,被删除。
begin_chunk move next;
begin_pos = 0;
endif
2.3 问题
-
根据ZeroMQ的源代码,在pop一个元素后,并没有对该元素执行析构操作,也没有在释放chunk时 取去析构每个元素,因此,该队列不适用于需要显式析构的元素对象(如数据对象中包含需要释放 的指针成员)。
-
pop和push操作的是不同的位置变量,两个操作本身不存在多线程冲突。但由于没有空队列的检测机制,对空队列进行pop操作会导致队列异常。而 空队列检查需要同时访问写入位置和读取位置,因此如果pop/posh放弃空队列检查,目的在于确保pop/push在一读一写并发时的线程安全。而空队 列时的操作检测,则交给了ypipe_t类实现。
3. ypipe_t类
ypipe_t类在yqueue_t的基础上,主要在读数据前,增加了空队列的检查机制。同时为了实现性能最大化,使用了基于atomic指针和一种预取机制的方案。
在ypipt_t类中,除了用于存储数据的yqueue_t对象外(q), 增加了如下几个成员:
- c: atomic原子量指针,指向下一次的写入位置,也是最后一个可读元素的后一个位置,作为元素写入和读取域的边界,是空队列检查在一读一写并发时的线程安全的关键。
- *w: 指向队列中最近写入且尚未flush提交的元素。ypipe_t
- r: 指向第一个没有预取的元素,该指针仅由读取操作访问。
- f: 指向将被flush的元素。
3.1 初始化状态图解

- 链表为空,front地址指向第一个元素,即下次的写入位置
- 上述r/w/f/c同时指向front,即下次写入位置。
3.2 写入元素
写入过程逻辑(不考虑批量写入的flush机会,假设写入一个元素后立即flush):
q.back() = value; // 向back位置写入数据
q.push(); // back位置后移
f = q.back(); // f指向新的back位置

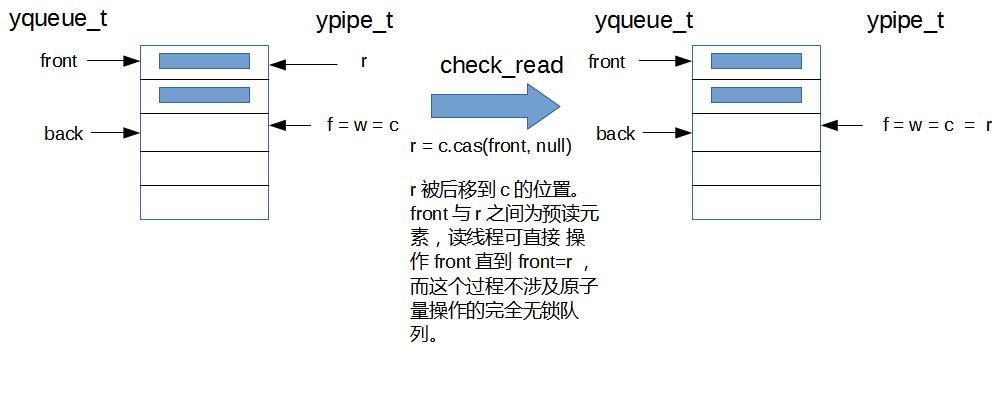
3.3 队列可读检查(check_read)和数据读取
在读出数据前,首先执行了空队列检查逻辑,只有队列有可读数据时,才执行读取操作。
检查可读操作包含了一个预取操作,即在queue.front()与指针r之间的元素称之为“已预取元素”,在取这段区域的元素时,无需对原子量c访问即可直接获取,实现真正的无锁操作。
4. 结论
- 一个队列纯粹的数据写入和读取,由于操作的是队列两端不同的数据指针,因此对于一读一写两个线程并发来说,无需加锁操作。
- 纯粹的数据写入和读取,如果没有对空队列状态的状态进行判断,读取过程可能会越界。
- 为了读取过程不越界,需要给为其设置一个边界值,供读取线程在读取前访问判断是否越界。为了保证写入的数据都能被读取,写入线程在写入数据后,需要向后设置这个边界。
- 由于这个边界值时读取线程和写入线程的共享变量,由于编译器优化、CPU乱序执行等原因,该共享变量的读写需要原子化。
- 原子变量的读写同样会带来较大的性能损耗,为避免每次访问队列都访问这个原子变量边界值,对队列的读取过程采用“预取”逻辑,对写入过程采用“flush”逻辑,即:
- 读取线程将原子变量边界值一次性移动到最后一个可读元素(并用本地指针暂存),此后的读取过程不再访问原子变量边界,直到原子变量边界之前的元素读完后,再将原子变量批量后移。
- 写入过程使用逐个写入多个数据,直到最后调用flush将原子变量边界设置到队列尾部。















 929
929

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









