






ANTLR是什么鬼?引用官网的说明,
What is ANTLR?
ANTLR (ANother Tool for Language Recognition) is a powerful parser generator for reading, processing, executing, or translating structured text or binary files. It’s widely used to build languages, tools, and frameworks. From a grammar, ANTLR generates a parser that can build and walk parse trees.
从编译器的角度来看,ANTLR可以用来帮助我们完成编译器前端所要完成的一些工作,词法分析(Lexical Analysis),语法分析(Syntax Analysis),生成抽象语法树(Abstract Syntax Tree,AST)等。语义分析(Semantic Analysis),例如类型检查,需要我们自己完成。有一点要啰嗦一下,在ANTLR4中已经不再提供生成AST的功能(在ANTLR3中可以通过Options指定
output=AST来生成AST),而是生成了分析树(Parse Tree)。关于AST和PT的优劣,可以看看SO上面的这个回答。要使用ANTLR生成语言的词法分析器(Lexer)跟语法分析器(Parser),我们需要告诉ANTLR我们的语言的文法(Grammar)。ANTLR采用的是上下文无关文法(Context Free Grammar),使用类似BNF的符号集来描述。使用上下文无关文法的语言比较常用的Parser有两种,LL Parser和LR Parser,而ANTLR帮我们生成的是前者。
alright,上面啰嗦了这么多,接下来我们通过一个简单的栗子来小试牛刀,看看ANTLR是怎么玩的。
一个简单计算器的grammar,
grammar Cal; options { // antlr will generate java lexer and parser language = Java; } @lexer::header { package me.kisimple.just4fun.antlr; } @parser::header { package me.kisimple.just4fun.antlr; } lexer rules: PLUS : '+' ; MINUS : '-' ; MULTIPLY : '*' ; DIVIDE : '/' ; LPAREN : '(' ; RPAREN : ')' ; ZERO : '0' ; NUMBER : ZERO | [1-9][0-9]* ; WS : [ \t\r\n]+ -> skip ; parser rules: program : calExpr ; calExpr : multExpr ((PLUS|MINUS) multExpr)* ; multExpr : atom ((MULTIPLY|DIVIDE) atom)* ; atom: LPAREN calExpr RPAREN | NUMBER ;
使用 ANTLR提供的工具 来帮我们生成Lexer和Parser,
> java org.antlr.v4.Tool -visitor Cal.g4
-visitor用来告诉ANTLR帮我们生成PT的Visitor,我们可以通过Visitor来访问PT,另外也可以通过Listener来遍历PT,二者的区别如下,The biggest difference between the listener and visitor mechanisms is that listener methods are called independently by an ANTLR-provided walker object, whereas visitor methods must walk their children with explicit visit calls. Forgetting to invoke visitor methods on a node’s children, means those subtrees don’t get visited.
ANTLR还帮我们生成了token文件,
Cal.tokens,内容如下PLUS=1 MINUS=2 MULTIPLY=3 DIVIDE=4 LPAREN=5 RPAREN=6 ZERO=7 NUMBER=8 WS=9 '+'=1 '-'=2 '*'=3 '/'=4 '('=5 ')'=6 '0'=7
ANTLR给在我们的grammar文件中出现的token赋予了一个整数类型,这些类型在Parser中定义了常量,语法分析语义分析时不可避免的要用到它们。
接下来我们实现一个Visitor来访问PT,我们直接边访问边做计算,访问结束后我们的计算结果也就出来了(所以这里做的是一个解释器:)
package me.kisimple.just4fun.antlr; import org.antlr.v4.runtime.tree.ParseTree; import org.antlr.v4.runtime.tree.TerminalNode; import java.util.List; import java.util.Stack; public class CalVisitorImpl extends CalBaseVisitor<Long> { @Override public Long visitCalExpr(CalParser.CalExprContext ctx) { List<ParseTree> children = ctx.children; Stack<Long> atomStack = new Stack<Long>(); Stack<TerminalNode> opStack = new Stack<TerminalNode>(); for (ParseTree child : children) { if(child instanceof CalParser.MultExprContext) { Long current = visitMultExpr((CalParser.MultExprContext) child); if(!opStack.isEmpty()) { TerminalNode op = opStack.pop(); Long last = atomStack.pop(); switch (op.getSymbol().getType()) { case CalParser.PLUS: atomStack.push(last + current); break; case CalParser.MINUS: atomStack.push(last - current); break; } } else { atomStack.push(current); } } else { opStack.push((TerminalNode)child); } } return atomStack.pop(); } @Override public Long visitMultExpr(CalParser.MultExprContext ctx) { List<ParseTree> children = ctx.children; Stack<Long> atomStack = new Stack<Long>(); Stack<TerminalNode> opStack = new Stack<TerminalNode>(); for (ParseTree child : children) { if(child instanceof CalParser.AtomContext) { Long current = visitAtom((CalParser.AtomContext) child); if(!opStack.isEmpty()) { TerminalNode op = opStack.pop(); Long last = atomStack.pop(); switch (op.getSymbol().getType()) { case CalParser.MULTIPLY: atomStack.push(last * current); break; case CalParser.DIVIDE: atomStack.push(last / current); break; } } else { atomStack.push(current); } } else { opStack.push((TerminalNode)child); } } return atomStack.pop(); } @Override public Long visitAtom(CalParser.AtomContext ctx) { TerminalNode node = ctx.NUMBER(); if(node != null) { String text = ctx.getText(); return Long.valueOf(text); } // ignore '(' and ')' return visitCalExpr(ctx.calExpr()); } }
使用方式如下,
public static void main(String[] args) throws Throwable { System.out.println(((7 + 7) * (7 + 7) - 7) * 7 - 77 / 7); String expr = "((7 + 7) * (7 + 7) - 7) * 7 - 77 / 7"; ANTLRInputStream input = new ANTLRInputStream(expr); CalLexer lexer = new CalLexer(input); CommonTokenStream tokens = new CommonTokenStream(lexer); tokens.fill(); CalParser parser = new CalParser(tokens); ParserRuleContext tree = parser.program(); CalVisitorImpl visitor = new CalVisitorImpl(); System.out.println(visitor.visit(tree)); }
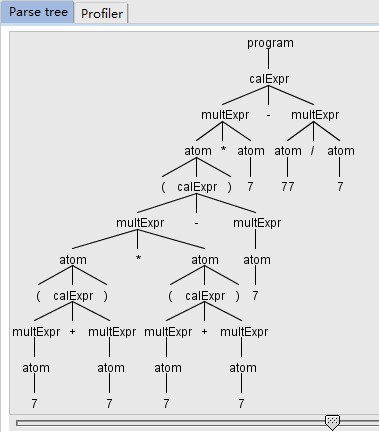
可以通过ANTLR提供的IDEA插件来看看这颗分析树,
Error Handling
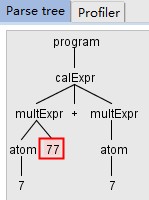
还有一点要说明下,默认情况下,ANTLR生成的Parser在做语法分析时,如果遇到错误会直接略过出错的token,例如
String expr = "7 77 + 7";分析树如下图,
输出是这样子的,
line 1:2 extraneous input '77' expecting {<EOF>, '+', '-', '*', '/'} 14
77直接被忽略,执行了7 + 7得到上面的结果。但是可以看到,其实Parser是知道有错误了才会报extraneous input。因此我们可以参考默认的ANTLRErrorStrategy,也就是DefaultErrorStrategy来重新实现错误处理的逻辑,
public class IErrorStrategy extends BailErrorStrategy { @Override public Token recoverInline(Parser recognizer) throws RecognitionException { // SINGLE TOKEN DELETION Token matchedSymbol = singleTokenDeletion(recognizer); if (matchedSymbol != null) return super.recoverInline(recognizer); // SINGLE TOKEN INSERTION singleTokenInsertion(recognizer); return super.recoverInline(recognizer); } @Override public void sync(Parser recognizer) throws RecognitionException { ATNState s = recognizer.getInterpreter().atn.states.get(recognizer.getState()); if (inErrorRecoveryMode(recognizer)) return; TokenStream tokens = recognizer.getInputStream(); int la = tokens.LA(1); // try cheaper subset first; might get lucky. seems to shave a wee bit off if ( recognizer.getATN().nextTokens(s).contains(la) || la==Token.EOF ) return; // Return but don't end recovery. only do that upon valid token match if (recognizer.isExpectedToken(la)) return; singleTokenDeletion(recognizer); throw new ParseCancellationException( new InputMismatchException(recognizer)); } }
使用Parser的时候需要设置一下,parser.setErrorHandler(new IErrorStrategy());然后就可以看到成功报错并且提示了:)
line 1:2 extraneous input '77' expecting {<EOF>, '+', '-', '*', '/'} Exception in thread "main" org.antlr.v4.runtime.misc.ParseCancellationException at me.kisimple.just4fun.antlr.IErrorStrategy.sync(IErrorStrategy.java:44) at me.kisimple.just4fun.antlr.CalParser.multExpr(CalParser.java:251) at me.kisimple.just4fun.antlr.CalParser.calExpr(CalParser.java:172) at me.kisimple.just4fun.antlr.CalParser.program(CalParser.java:116) at me.kisimple.just4fun.Main.main(Main.java:33) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:606) at com.intellij.rt.execution.application.AppMain.main(AppMain.java:134) Caused by: org.antlr.v4.runtime.InputMismatchException ... 10 more
参考资料
- ANTLR 4 Documentation
- What is the difference between ANTLR 3 and 4?
- https://theantlrguy.atlassian.net/wiki/display/ANTLR4/Lexer+Rules
- https://theantlrguy.atlassian.net/wiki/display/ANTLR4/Parser+Rules
- https://theantlrguy.atlassian.net/wiki/display/ANTLR4/Parse+Tree+Listeners
- http://www.ibm.com/developerworks/cn/java/j-lo-antlr/index.html
- http://meri-stuff.blogspot.com/2011/08/antlr-tutorial-hello-word.html















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









