







一.关于HTTP数据传输中的内容长度
在HTTP传输过程中,Content-Length用来表示响应消息体的大小,通常带有Content-Length的数据是图片,媒体资源,静态文本,网页,还有些文档。通常Content-Length可以被Client,Server都能利用。
1.使用Content-Length在Client端时,配合POST,PUT,DELETE等向Server发送数据,报告数据长度给Server。
2.使用Content-Length在Server端时,配合除HEAD,HTTP 304等,向Client报告数据长度。
3.当然,问题有些数据是动态变化的,并没有固定长度,比如动态页面处理数据,Server本身不确定数据总长度,只知道数据中每个片段长度。因此,无法使用Content-Length通知客户端。这时候Transfer-Encoding:Chunked走上了舞台,这种方式会会按照一边传递数据片段的长度一边发送数据片段规则向Client传递数据。
4.同样综上可知,Content-Length永远不能和chunked一起使用。
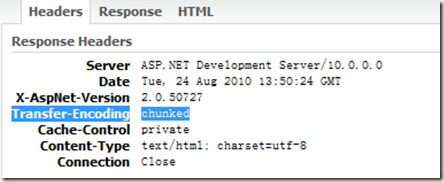
二.Transfer-Encoding:Chunked编码的数据格式。
HTTP/1.1 200 OK\r\n
Content-Type: text/plain\r\n
Transfer-Encoding: chunked\r\n
Connection:keep-Alive\r\n\r\n
25\r\n;
This is the data in the first chunk\r\n
\r\n1A\r\n
and this is the second one
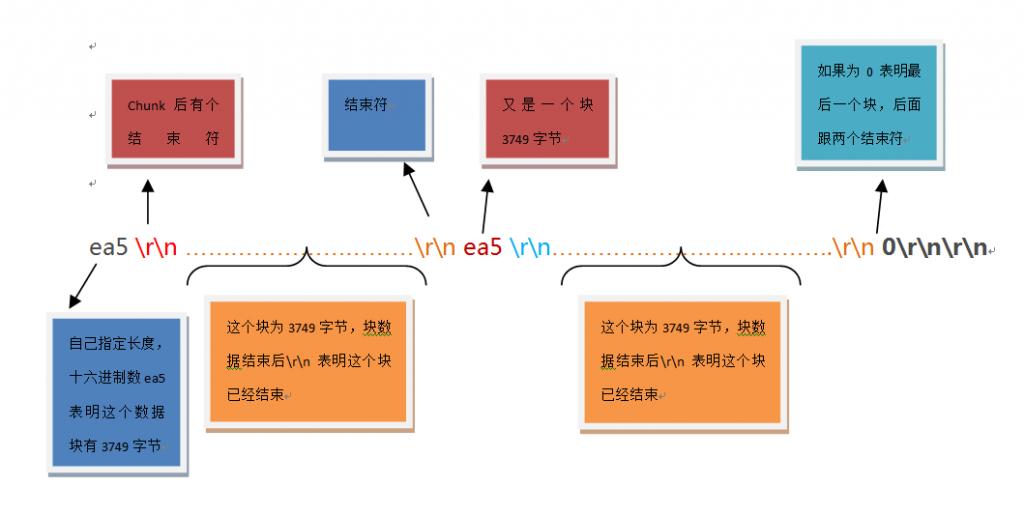
\r\n0\r\n\r\n看着很普通,其实我们重点关注第三,五,七,九行:
第三行说明了他的传输编码是chunked,第五,七,九是chunked编码下一片段Content-Length指示,用16进制数据表示的。
比如第五行,去掉\r\n,0x25转10进制正好是37,而“This is the data in the first chunk\r\n”的长度整好是37
同样第七行,0x1A=26,“and this is the second one”的长度是26
第九行有些特殊,因为他标志的0x0=0,那么意味着以下再也没有数据了,告诉Client停止读取,否则遭遇线程阻塞而不会返回-1
\r\n0\r\n\r\n使用一张示例图来说明这之间的关系
三.Transfer-Encoding:Chunked编码解析
标准解析伪代码
length := 0//用来记录解码后的数据体长度
read chunk-size, chunk-extension (if any) and CRLF//第一次读取块大小
while (chunk-size > 0) {//一直循环,直到读取的块大小为0
read chunk-data and CRLF//读取块数据体,以回车结束
append chunk-data to entity-body//添加块数据体到解码后实体数据
length := length + chunk-size//更新解码后的实体长度
read chunk-size and CRLF//读取新的块大小
}
read entity-header//以下代码读取全部的头标记
while (entity-header not empty) {
append entity-header to existing header fields
read entity-header
}
Content-Length := length//头标记中添加内容长度
Remove "chunked" from Transfer-Encoding//头标记中移除Transfer-Encoding
1.chunked常规的解析
我们可以直接看下面代码
URL url=new URL("http://localhost:8080/test/ios.php");
EchoURLConnection connection=(EchoURLConnection)url.openConnection();
connection.setDoOutput(true);
connection.setDoInput(true);
PrintWriter pw = new PrintWriter(new OutputStreamWriter(connection.getOutputStream()));
pw.write("name=zhangsan&password=123456");
pw.flush();
InputStream stream = connection.getInputStream();
int len = -1;
byte[] buf = new byte[1];
byte[] outBuf = new byte[]{0x3A}; //默认给一个“冒号”,便于解析http Response响应头第一行
int count = 0;
//进行Header提取
while((len=stream.read(buf, 0, buf.length))>-1)
{
int outLength = outBuf.length+len;
byte[] tempBuf = outBuf;
outBuf = new byte[outLength];
System.arraycopy(tempBuf, 0, outBuf,0, tempBuf.length);
System.arraycopy(buf, 0, outBuf,outBuf.length-1, len);
if(buf[0]==0x0D || buf[0]==0x0A)
{
count++;
if(count==4)
{
break;
}
}else{
count = 0;
}
}
String headerString = new String(outBuf, 0, outBuf.length);
String[] splitLine = headerString.trim().split("\r\n");
//将header载入Map
Map<String, String> headerMap = new HashMap<String, String>();
boolean isCkunked = false;
for (String statusLine : splitLine) {
String[] nameValue = statusLine.split(":");
if(nameValue[0].equals(""))
{
headerMap.put("", nameValue[1]);
}else{
headerMap.put(nameValue[0], nameValue[1]);
}
if("Transfer-Encoding".equalsIgnoreCase(nameValue[0]))
{
String value = nameValue[1].trim();
isCkunked = value.equalsIgnoreCase("chunked"); //判断是否是chunked编码数据
}
}
System.out.println(headerMap);
if(isCkunked)
{
int chunkedNumber = 0; //计数器,用于记录经过了了多少个CRLF(回车换行)
byte[] readBuf = null; //用于缓存chunked片段的Content-Length行
byte[] contentBuf = new byte[0]; //用于缓存实际内容
long currentLength = 0;
while((len=stream.read(buf, 0,buf.length))>=0)
{
if(readBuf==null)
{
readBuf = new byte[]{buf[0]};
}
else
{
int outLength = readBuf.length+len;
byte[] tempBuf = readBuf;
readBuf = new byte[outLength];
System.arraycopy(tempBuf, 0, readBuf,0, tempBuf.length);
System.arraycopy(buf, 0, readBuf,readBuf.length-1, len);
}
if(buf[0]==0x0D|| buf[0]==0x0A) //判断回车换行
{
chunkedNumber++;
//readBuf.length>currentLength判断读取的字节流长度超过没超过chunked的片段Content-Length
if(chunkedNumber==2&&readBuf.length>currentLength)
{
byte[] tmpContentBuf = contentBuf;
contentBuf = new byte[(int) (tmpContentBuf.length+currentLength)];
System.arraycopy(tmpContentBuf, 0, contentBuf,0, tmpContentBuf.length);
System.arraycopy(readBuf, 0, contentBuf,tmpContentBuf.length, (int) currentLength);
String lineNo = "0x"+ (new String(readBuf,(int)currentLength, readBuf.length-(int)currentLength)).trim();
if(lineNo.equals("0x"))
{
currentLength = 0; //表示还没有读取到chunked片段Content-Length
}else{
currentLength = Long.decode(lineNo); //解析chunked片段Content-Length
if(currentLength==0) //如果解析出currentLength为0,那么应该停止读取
{
System.out.println(new String(contentBuf, 0,contentBuf.length));
break;
}
}
System.out.println(currentLength+"--"+lineNo);
chunkedNumber = 0;
readBuf = null;
}
}else{
chunkedNumber = 0; //遇到非CRLF,置为0
}
}
}else{
//解析非chunked编码数据
StringBuilder sb = new StringBuilder();
while((len=stream.read(buf, 0,buf.length))>-1)
{
sb.append(new String(buf, 0, len));
}
System.out.println(sb.toString());
}
pw.close();
stream.close();2.封装为解析类
当然,上面的解析方式可移植性不好,我们因此需要改进,我们通过代理方式,解析InputStream
public class HttpInputStream extends InputStream {
private InputStream hostStream; //要解析的input流
private boolean isCkunked = false;
private int readMetaSize = 0; //读取的实际总长度
private long contentLength = 0; //读取到的内容长度
private long chunkedNextLength = -1L; //指示要读取得字节流长度
private long chunkedCurrentLength = 0L; //指示当前已经读取的字节流长度
private final Map<String, Object> httpHeaders = new HashMap<String, Object>();
public HttpInputStream(InputStream inputStream) throws IOException
{
this.hostStream = inputStream;
parseHeader();
}
public int getReadMetaSize() {
return readMetaSize;
}
public long getContentLength()
{
return contentLength;
}
/**
* 解析响应头
* @throws IOException
*/
private void parseHeader() throws IOException
{
if(this.hostStream!=null)
{
int len = -1;
byte[] buf = new byte[1];
byte[] outBuf = new byte[]{0x3A};
int count = 0;
while((len=read(buf, 0, buf.length))>-1)
{
int outLength = outBuf.length+len;
byte[] tempBuf = outBuf;
outBuf = new byte[outLength];
System.arraycopy(tempBuf, 0, outBuf,0, tempBuf.length);
System.arraycopy(buf, 0, outBuf,outBuf.length-1, len);
if(buf[0]==0x0D || buf[0]==0x0A)
{
count++;
if(count==4)
{
break;
}
}else{
count = 0;
}
}
String headerString = new String(outBuf, 0, outBuf.length);
String[] splitLine = headerString.trim().split("\r\n");
for (String statusLine : splitLine) {
String[] nameValue = statusLine.split(":");
if(nameValue[0].equals(""))
{
httpHeaders.put("", nameValue[1]);
}else{
httpHeaders.put(nameValue[0], nameValue[1]);
}
if("Transfer-Encoding".equalsIgnoreCase(nameValue[0]))
{
String value = nameValue[1].trim();
isCkunked = value.equalsIgnoreCase("chunked");
}
}
}
}
public Map<String, Object> getHttpHeaders() {
return httpHeaders;
}
/**
* 字节流读取
*/
@Override
public int read() throws IOException {
if(!isCkunked)
{
/**
* 非chunked编码字节流解析
*/
return hostStream.read();
}
/**
* chunked编码字节流解析
*/
return readChunked();
}
private int readChunked() throws IOException {
byte[] chunkedFlagBuf = new byte[0]; //用于缓冲chunked编码数据的length标志行
int crlf_nums = 0;
int byteCode = -1;
if(chunkedNextLength==-1L) // -1表示需要获取 chunkedNextLength大小,也就是chunked数据length标志
{
byteCode = hostStream.read();
readMetaSize++;
while(byteCode!=-1)
{
int outLength = chunkedFlagBuf.length+1;
byte[] tempBuf = chunkedFlagBuf;
chunkedFlagBuf = new byte[outLength];
System.arraycopy(tempBuf, 0, chunkedFlagBuf,0, tempBuf.length);
System.arraycopy(new byte[]{(byte) byteCode}, 0, chunkedFlagBuf,chunkedFlagBuf.length-1, 1);
if(byteCode==0x0D || byteCode==0x0A) //记录回车换行
{
crlf_nums++;
if(crlf_nums==2) //如果回车换行计数为2,进行检测
{
String lineNo = "0x"+ (new String(chunkedFlagBuf,0,chunkedFlagBuf.length)).trim();
chunkedNextLength = Long.decode(lineNo);
contentLength+=chunkedNextLength;
if(chunkedNextLength>0)
{
byteCode = hostStream.read();
readMetaSize++;
}
break;
}
}else{
crlf_nums=0;
}
byteCode = hostStream.read();
readMetaSize++;
}
}
else if(chunkedNextLength>0) //表示要读取得片段长度
{
if(chunkedCurrentLength<chunkedNextLength)
{
byteCode = hostStream.read();
readMetaSize++;
chunkedCurrentLength++; //读取时加一,记录长度
}
if(chunkedCurrentLength==chunkedNextLength){ //内容长度和标志长度相同,说明长度为chunkedCurrentLength的数据已经被读取到了
chunkedNextLength = -1L;
chunkedCurrentLength = 0L;
}
}else{
//读取结束,此时更新内容总长度到header中
getHttpHeaders().put("Content-Length", ""+contentLength);
return -1;//chunked流不会返回-1,这里针对chunkedLength=0强制返回-1
}
return byteCode;
}
@Override
public long skip(long n) throws IOException {
return hostStream.skip(n);
}
@Override
public boolean markSupported() {
return hostStream.markSupported();
}
@Override
public int available() throws IOException {
return hostStream.available();
}
@Override
public synchronized void mark(int readlimit) {
hostStream.mark(readlimit);
}
@Override
public void close() throws IOException {
hostStream.close();
}
@Override
public synchronized void reset() throws IOException {
hostStream.reset();
}是不是很简单,做到这一步,我们其实已经完成了HttpResponse最70%的功能,剩下的30%是缓存,重定向,httpCookie之类的组件。
四.使用方式
URL url=new URL("http://localhost:8080/test/ios.php");
EchoURLConnection connection=(EchoURLConnection)url.openConnection();
connection.setDoOutput(true);
connection.setDoInput(true);
PrintWriter pw = new PrintWriter(new OutputStreamWriter(connection.getOutputStream()));
pw.write("name=zhangsan&password=123456");
pw.flush();
InputStream stream = connection.getInputStream();
HttpInputStream his = new HttpInputStream(stream);
System.out.println(his.getHttpHeaders());
int len = 0;
byte[] buf = new byte[127];
StringBuilder sb = new StringBuilder();
while((len=his.read(buf, 0, buf.length))!=-1)
{
sb.append(new String(buf, 0, len));
}
System.out.println(sb.toString());















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









