







Hadoop一般都部署在linux平台上,想让Hadoop执行我们写好的程序,首先需要在本地写好程序打包,然后上传到liunx,最后通过指定命令执行打包好的程序;一次两次还可以,如果进行频繁的调试是很不方便的,所有最好是能直接通过IDE直接连接Hadoop;下面总结了三种方式连接Hadoop执行分析:
1.利用Hadoop的本地模式,在Eclipse中执行本地数据计算
2.Eclipse连接远程Hadoop,利用Hadoop的本地模式,在Eclipse中分析hdfs中的数据
3.Eclipse连接远程Hadoop,提交本地程序到远程的Hadoop分析hdfs中的数据软件版本
操作系统:win7 64位
Eclipse:Indigo Service Release 2
Java:1.7
Hadoop:2.5.1
Linux:Centos7
一、利用Hadoop的本地模式,在Eclipse中执行本地数据计算
写好的程序在本地测试完之前再提交到远程服务器上进行数据分析还是很有必要的,这就需要利用Hadoop提供的本地模式了
1.解压hadoop-2.5.1.tar.gz到本地,如:D:\software\hadoop-2.5.1
2.配置环境变量 HADOOP_PATH=D:\software\hadoop-2.5.1
3.下载windows64位平台的hadoop2.6插件包(hadoop.dll,winutils.exe)
在hadoop2.5.1源码的hadoop-common-project\hadoop-common\src\main\winutils下,有一个vs.net工程,编译这个工程可以得到这一堆文件,输出的文件中有hadoop.dll和winutils.exe
或者直接下载编译好的:http://pan.baidu.com/s/1nuP6CGT
将winutils.exe复制到%HADOOP_PATH%/bin目录下,将hadoop.dll复制到C:\Windows\System32目录下
4.新建maven项目
pomx.xml文件:
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>2.0.2</version>
<configuration>
<source>1.7</source>
<target>1.7</target>
</configuration>
</plugin>
</plugins>
</build>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.5.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.5.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.5.1</version>
</dependency>
<dependency>
<groupId>jdk.tools</groupId>
<artifactId>jdk.tools</artifactId>
<version>1.7</version>
<scope>system</scope>
<systemPath>${JAVA_HOME}/lib/tools.jar</systemPath>
</dependency>
</dependencies>右击->Maven->Update Project…
5.为了显示消息的输出日志,提供log4j.properties文件在classpath路径下
6.添加测试类,直接将%HADOOP_HOME%\share\hadoop\mapreduce\sources\hadoop-mapreduce-examples-2.5.1-sources.jar 中的WordCount.java拷贝到项目中
代码整体结构:

7.Run As->Run Configurations…指定输入和输出
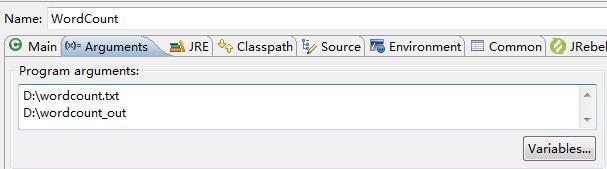
这里的wordcount.txt随便写几个单词在里面就行了
8.执行程序
D:\wordcount_out中生成了分析结果

打开part-r-00000:
hello 3
world 3
二、Eclipse连接远程Hadoop,利用Hadoop的本地模式,在Eclipse中分析hdfs中的数据
1.保证远程Hadoop启动正常
参考:Hadoop的伪分布式模式
以下两种方式需要远程连接Hadoop,需要用到Hadoop的Eclipse插件
2.下载hadoop-eclipse-plugin插件
hadoop-eclipse-plugin是一个专门用于eclipse的hadoop插件,可以直接在IDE环境中查看hdfs的目录和文件内容
源码: https://github.com/winghc/hadoop2x-eclipse-plugin
或者直接下载:http://pan.baidu.com/s/1bI149g
将hadoop-eclipse-plugin-2.5.1.jar下载复制到eclipse/plugins目录下,然后重启eclipse
3.配置hadoop-eclipse-plugin插件
window->preferences->Hadoop Map/Reduce 指定win7上的hadoop根目录
windows->show view->other
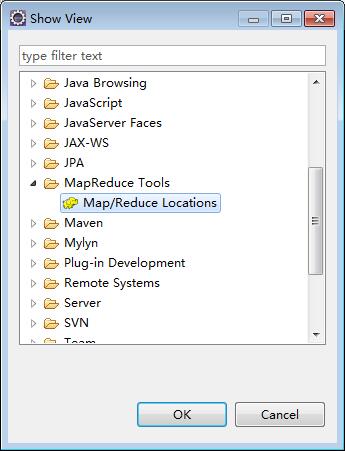
打开Map/Reduce Locations

添加一个Location
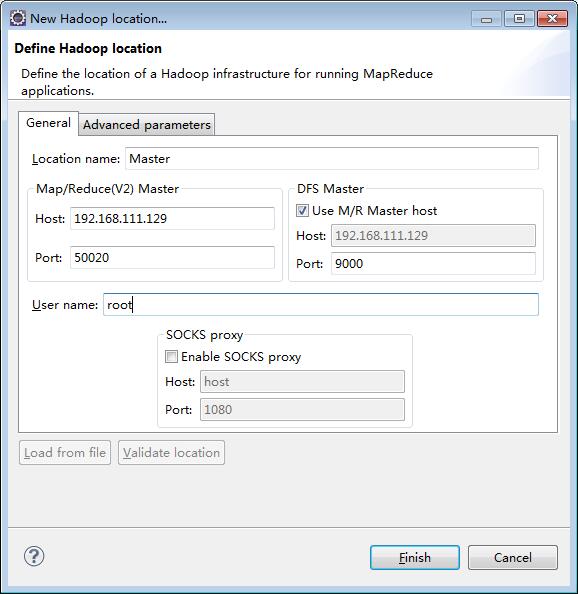
Location name:随便起个名字
Map/Reduce(V2) Master Host:这里就是远程里hadoop master对应的IP地址,端口对应 hdfs-site.xml里dfs.datanode.ipc.address属性所指定的端口
DFS Master Port: 对应core-site.xml里fs.defaultFS所指定的端口
User name:运行远程hadoop的用户名,比如root
4.一切顺利的话,在Project Explorer面板中,就能看到hdfs里的目录和文件了

问题一:如果不能看到hdfs中的文件,先本地尝试telnet 192.168.111.129 9000,如果无法连接尝试修改配置core-site.xml(服务器端):
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.111.129:9000</value>
</property>
</configuration>问题二:在Eclipse中删除hdfs中的文件,会出现权限不足的问题
在hdfs-site.xml(服务器端)里设置dfs.permissions.enabled:
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>如果还是不行可以直接服务器端做如下设置,为了更加方便的测试(正式环境下肯定是不允许的)
hadoop dfsadmin -safemode leave
hadoop fs -chmod 777 /5.创建Map/Reduce Project

创建完直接将%HADOOP_HOME%\share\hadoop\mapreduce\sources\hadoop-mapreduce-examples-2.5.1-sources.jar 中的WordCount.java拷贝到项目中;
同样添加log4j.properties文件,方便查错
6.Run As->Run Configurations…指定输入和输出
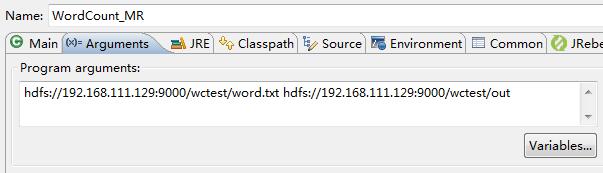
7.执行程序

打开part-r-00000
hadoop 1
hello 3
java 1
world 1问题三:user=Administrator没有权限
Exception in thread "main" org.apache.hadoop.security.AccessControlException: Permission denied: user=Administrator, access=EXECUTE, inode="/tmp":hadoop:supergroup:drwx------
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.check(FSPermissionChecker.java:234)
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkTraverse(FSPermissionChecker.java:187)
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkPermission(FSPermissionChecker.java:150)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.checkPermission(FSNamesystem.java:5433)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.checkPermission(FSNamesystem.java:5415)因为本地电脑的用户是Administrator,而hdfs需要相关的用户才能操作,比如root,有两种方式来修改:
1.可以把计算机名改为root用户的用户名
2.hadoop fs -chown -R Administrator:Administrator /tmp
三、Eclipse连接远程Hadoop,提交本地程序到远程的Hadoop分析hdfs中的数据
这种方式配置基本和第二种方式一致,只不过我们需要在classpath路径下添加一个hadoop-remote.xml文件
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>192.168.111.129</value>
</property>
<property>
<name>mapreduce.app-submission.cross-platform</name>
<value>true</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>192.168.111.129:10020</value>
</property>
</configuration>同时在代码里面设置Configuration
conf.addResource("hadoop-remote.xml");注一:配置的mapreduce.jobhistory.address需要在服务器端启动historyserver
mr-jobhistory-daemon.sh start historyserver
mr-jobhistory-daemon.sh stop historyserver注二:mapreduce.app-submission.cross-platform,map reduce默认没有开启跨平台(win到linux)任务提交导致的,不设置为true会出现如下错误
ExitCodeException exitCode=1: /bin/bash: line 0: fg: no job control
at org.apache.hadoop.util.Shell.runCommand(Shell.java:538)
at org.apache.hadoop.util.Shell.run(Shell.java:455)
at org.apache.hadoop.util.Shell$ShellCommandExecutor.execute(Shell.java:702)
at org.apache.hadoop.yarn.server.nodemanager.DefaultContainerExecutor.launchContainer(DefaultContainerExecutor.java:195)
at org.apache.hadoop.yarn.server.nodemanager.containermanager.launcher.ContainerLaunch.call(ContainerLaunch.java:300)
at org.apache.hadoop.yarn.server.nodemanager.containermanager.launcher.ContainerLaunch.call(ContainerLaunch.java:81)
at java.util.concurrent.FutureTask.run(FutureTask.java:262)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:745)注三:yarn.resourcemanager.hostname,如果不设置具体的ip地址,会出现如下问题:
Retrying connect to server: 0.0.0.0/0.0.0.0:8032. Already tried 0 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000 MILLISECONDS)
这样就可以将本地的MapReduce程序发送到远程Hadoop上进行执行,经测试获得同第二种方式相同的结果
总结
以上总结的三种方式一般都需要使用,并且有一定的顺序性:
1.先用测试数据在本地Hadoop上执行,如果没有问题,进入第二步
2.使用正式数据的副本在本地执行,如果没有问题,进入第三步
3.提交程序到远程Hadoop上执行















 279
279

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









