






分布式系统之CAP理论杂记
http://www.cnblogs.com/highriver/archive/2011/09/15/2176833.html
分布式系统的CAP理论:
理论首先把分布式系统中的三个特性进行了如下归纳:
● 一致性(C):在分布式系统中的所有数据备份,在同一时刻是否同样的值。
● 可用性(A):在集群中一部分节点故障后,集群整体是否还能响应客户端的读写请求。(可用性不仅包括读,还有写)
● 分区容忍性(P):集群中的某些节点在无法联系后,集群整体是否还能继续进行服务。
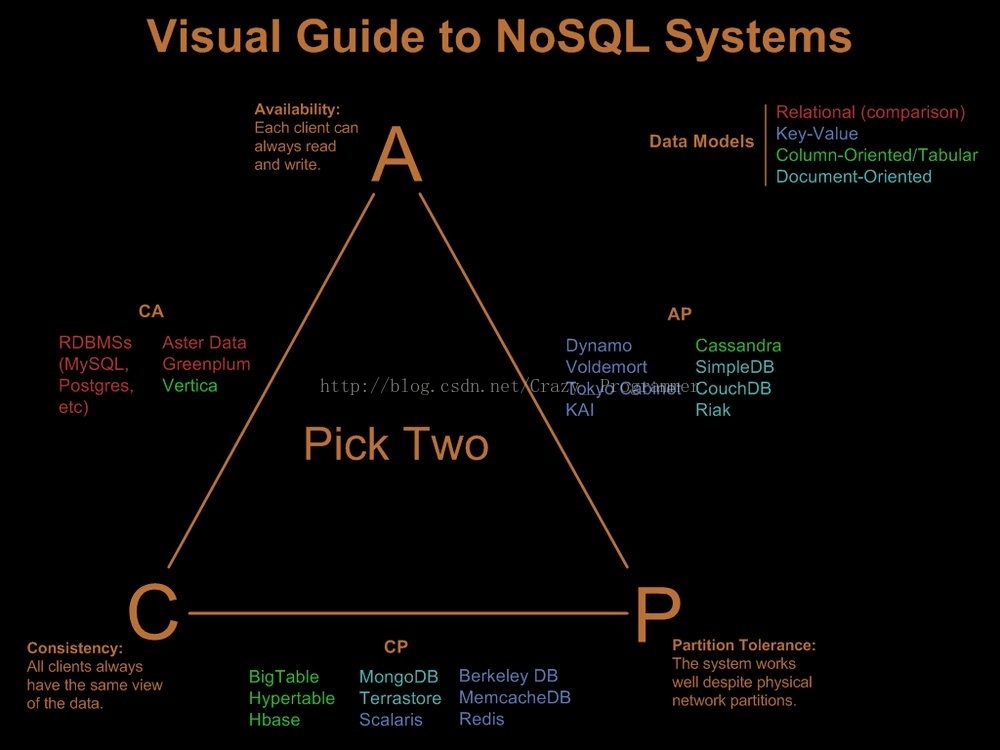
一致性与可用性的决择:
而CAP理论就是说在分布式存储系统中,最多只能实现上面的两点。而由于当前的网络硬件肯定
会出现延迟丢包等问题,所以分区容忍性是我们必须需要实现的。所以我们只能在一致性和可用
性之间进行权衡,没有NoSQL系统能同时保证这三点。
对于web2.0网站来说,关系数据库的很多主要特性却往往无用武之地
1.数据库事务一致性需求
很多web实时系统并不要求严格的数据库事务,对读一致性的要求很低,有些场合对写一致性要求并不高。允许实现最终一致性。
2、数据库的写实时性和读实时性需求
对关系数据库来说,插入一条数据之后立刻查询,是肯定可以读出来这条数据的,但是对于
很多web应用来说,并不要求这么高的实时性,比方说发一条消息之
后,过几秒乃至十几秒之后,我的订阅者才看到这条动态是完全可以接受的。
3、对复杂的SQL查询,特别是多表关联查询的需求
任何大数据量的web系统,都非常忌讳多个大表的关联查询,以及复杂的数据分析类型的复?
覵QL报表查询,特别是SNS类型的网站,从需求以及产品设计角
度,就避免了这种情况的产生。往往更多的只是单表的主键查询,以及单表的简单条件分页
查询,SQL的功能被极大的弱化了。
高可用性就是高性能。 BASE提供了基本可用性。BASE是碱,ACID是酸。
总结:
传统的关系型数据库在功能支持上通常很宽泛,从简单的键值查询,到复杂的多表联合查询再到
事务机制的支持。而与之不同的是,NoSQL系统通常注重性能和扩展性,而非事务机制(事务就是强一致性的体现。)。
传统的SQL数据库的事务通常都是支持ACID的强事务机制。A代表原子性,即在事务中执行多个
操作是原子性的,要么事务中的操作全部执行,要么一个都不执行;C代表一致性,即保证进行事
务的过程中整个数据加的状态是一致的,不会出现数据花掉的情况;I代表隔离性,即两个事务不
会相互影响,覆盖彼此数据等;D表示持久化,即事务一量完成,那么数据应该是被写到安全的,
持久化存储的设备上(比如磁盘)。
NoSQL系统仅提供对行级别的原子性保证,也就是说同时对同一个Key下的数据进行的两个操作,在实际执行的时候是会串
行的执行,保证了每一个Key-Value对不会被破坏。
Redis:BASE就是为了解决关系数据库强一致性引起的问题而引起的可用性降低而提出的解决方案。
1.目前最快的KV数据库,10W次/S, 满足了高可用性。
2.Redis 的k-v上的v可以是普通的值(基本操作:get/set/del) v可以是数值(除了基本操作之外还可以支持数值的计算) v可以是数据结构比如基于链表存储的双向循环list(除了基本操作之外还可以支持数值的计算,可以实现list的二头pop,push)。
如果v是list,可以使用redis实现一个消息队列。如果v是set,可以基于redis实现一个tag系统。与mongodb不同的地方是后者的v可以支持文档,比如按照json的结构存储。redis也可以对存入的Key-Value设置expire时间。
3.Redis的v的最大远远超过memcache。这也是实现消息队列的一个前提。
在NoSQL中,通常有两个层次的一致性:第 一种是强一致性,既集群中的所有机器状态同步保持一致。第二种是最终一致性,既可以允
许短 暂的数据不一致,但数据最终会保持一致。我们先来讲一下,在分布式集群中,为什么最终一致 性通常是更合理的选择
一致性(Consistency):
对于分布式的存储系统,一个数据往往会存在多份。简单的说,一致性会让客户对数据的修改操作(增/删/改)要么在所有的数据副本(在英文文献中常称为Replica)全部成功,要么全部失败。即,修改操作对于一份数据的所有副本而言,是原子(Atomic)的操作。
如果一个存储系统可以保证一致性,那么则客户读写的数据完全可以保证是最新的。不会发生两个不同的客户端在不同的存储节点中读取到不同副本的情况。
可用性(Availability):
可用性很简单,顾名思义,就是指在客户端想要访问数据的时候,可以得到响应。但是注意,系统可用(Available)并不代表存储系统所有节点提供的数据是一致的。比如客户端想要读取文章评论,存储系统可以返回客户端数据,但是评论缺少最新的一条。这种情况,我们仍然说系统是可用的。
往往我们会对不同的应用设定一个最长响应时间,超过这个响应时间的服务我们仍然称之为不可用的。
分区容忍性(Partition Tolerance):
如果你的存储系统只运行在一个节点上,要么系统整个崩溃,要么全部运行良好。一旦针对同一服务的存储系统分布到了多个节点后,整个存储系统就存在分区的可能性。比如,两个存储节点之间联通的网络断开(无论长时间或者短暂的),就形成了分区。
对当前的互联网公司(例如Google)来说,为了提高服务质量,同一份数据放置在不同城市乃至不同国家是非常正常的。因此节点之间形成分区也很正常
Gilbert 和Lynch
将分区容忍性定义如下:
No set of failures less than total network failure is allowed to cause the system to respond incorrectly
除全部网络节点全部故障以外,所有子节点集合的故障都不允许导致整个系统不正确响应。















 463
463

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









