







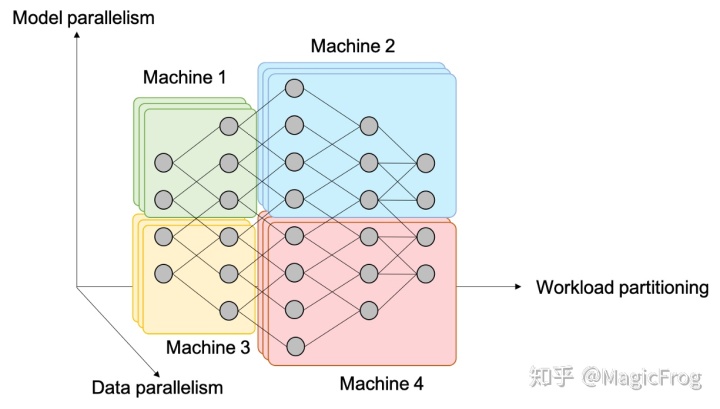
零. 概览
想要让你的PyTorch神经网络在多卡环境上跑得又快又好?那你definitely需要这一篇!
No one knows DDP better than I do!
– – magic_frog(手动狗头)
本文是DDP系列三篇(基本原理与入门,实现原理与源代码解析,实战)中的第三篇。本系列力求深入浅出,简单易懂,猴子都能看得懂(误)。
在过去的两篇文章里,我们已经对DDP的理论、代码进行了充分、详细的介绍,相信大家都已经了然在胸。但是,实践也是很重要的。正所谓理论联系实践,如果只掌握理论而不进行实践,无疑是纸上谈兵。
在这篇文章里,我们通过几个实战例子,来给大家介绍一下DDP在实际生产中的应用。希望能对大家有所帮助!
- 在DDP中引入SyncBN
- DDP下的Gradient Accumulation的进一步加速
- 多机多卡环境下的inference加速
- 保证DDP性能:确保数据的一致性
- 和DDP有关的小技巧
- 控制不同进程的执行顺序
- 避免DDP带来的冗余输出
请欢快地开始阅读吧!
依赖:pytorch(gpu)>=1.5,python>=3.6
一. 在DDP中引入SyncBN
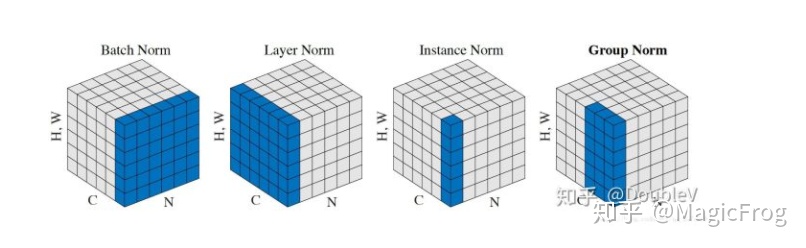
什么是Batch Normalization(BN)? 这里就不多加以介绍。附上BN文章。接下来,让我们来深入了解下BN在多级多卡环境上的完整实现:SyncBN。
什么是SyncBN?
SyncBN就是Batch Normalization(BN)。其跟一般所说的普通BN的不同在于工程实现方式:SyncBN能够完美支持多卡训练,而普通BN在多卡模式下实际上就是单卡模式。
我们知道,BN中有moving mean和moving variance这两个buffer,这两个buffer的更新依赖于当前训练轮次的batch数据的计算结果。但是在普通多卡DP模式下,各个模型只能拿到自己的那部分计算结果,所以在DP模式下的普通BN被设计为只利用主卡上的计算结果来计算moving mean和moving variance,之后再广播给其他卡。这样,实际上BN的batch size就只是主卡上的batch size那么大。当模型很大、batch size很小时,这样的BN无疑会限制模型的性能。
为了解决这个问题,PyTorch新引入了一个叫SyncBN的结构,利用DDP的分布式计算接口来实现真正的多卡BN。
SyncBN的原理
SyncBN的原理很简单:SyncBN利用分布式通讯接口在各卡间进行通讯,从而能利用所有数据进行BN计算。为了尽可能地减少跨卡传输量,SyncBN做了一个关键的优化,即只传输各自进程的各自的 小batch mean和 小batch variance,而不是所有数据。具体流程请见下面:
- 前向传播
- 在各进程上计算各自的
小batch mean和小batch variance - 各自的进程对各自的
小batch mean和小batch variance进行all_gather操作,每个进程都得到s的全局量。- 注释:只传递mean和variance,而不是整体数据,可以大大减少通讯量,提高速度。
- 每个进程分别计算总体mean和总体variance,得到一样的结果
- 注释:在数学上是可行的,有兴趣的同学可以自己推导一下。
- 接下来,延续正常的BN计算。
- 注释:因为从前向传播的计算数据中得到的
batch mean和batch variance在各卡间保持一致,所以,running_mean和running_variance就能保持一致,不需要显式地同步了!
- 注释:因为从前向传播的计算数据中得到的
- 在各进程上计算各自的
- 后向传播:和正常的一样
贴一下关键代码,有兴趣的同学可以研究下:pytorch源码
SyncBN与DDP的关系
一句话总结,当前PyTorch SyncBN只在DDP单进程单卡模式中支持。SyncBN用到 all_gather这个分布式计算接口,而使用这个接口需要先初始化DDP环境。
复习一下DDP的伪代码中的准备阶段中的DDP初始化阶段
d. 创建管理器reducer,给每个parameter注册梯度平均的hook。
i. 注释:这一步的具体实现是在C++代码里面的,即reducer.h文件。
e. (可能)为可能的SyncBN层做准备
这里有三个点需要注意:
- 这里的为可能的SyncBN层做准备,实际上就是检测当前是否是DDP单进程单卡模式,如果不是,会直接停止。
- 这告诉我们,SyncBN需要在DDP环境初始化后初始化,但是要在DDP模型前就准备好。
- 为什么当前PyTorch SyncBN只支持DDP单进程单卡模式?
- 从SyncBN原理中我们可以看到,其强依赖了all_gather计算,而这个分布式接口当前是不支持单进程多卡或者DP模式的。当然,不排除未来也是有可能支持的。
怎么用SyncBN?
怎么样才能在我们的代码引入SyncBN呢?很简单:
# DDP init
dist.init_process_group(backend='nccl')
# 按照原来的方式定义模型,这里的BN都使用普通BN就行了。
model = MyModel()
# 引入SyncBN,这句代码,会将普通BN替换成SyncBN。
model = torch.nn.SyncBatchNo 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









