







参考官方文档:http://www.groovy-lang.org/metaprogramming.html
运行时及编译时元编程
Groovy 支持两种元编程:运行时元编程和编译时元编程。第一种方式允许在运行时改变类模式和程序行为,第二种方式则只发生在编译时。两种方式都有一定的优缺点,下面就来详细介绍一下它们。
1. 运行时元编程
运行时元编程,可以将一些决策(诸如解析、注入甚至合成类和接口的方法)推迟到运行时来完成。为了深入了解 Groovy 的 MOP,我们需要理解 Groovy 的对象以及 Groovy 处理方法。在 Groovy 中,我们主要与三类对象打交道:POJO、POGO,还有 Groovy 拦截器。Groovy 的元编程支持所有类型的对象,但是它们采用的方式却各不相同。
- POJO —— 普通的 Java 对象,它的类可以用 Java 或其他任何 JVM 上的语言来编写。
- POGO —— Groovy 对象,它的类使用 Groovy 编写而成,继承自
java.lang.Object且默认实现了groovy.lang.GroovyObject接口。 - Groovy 拦截器 —— 实现了 groovy.lang.GroovyInterceptable 接口的 Groovy 对象,并具有方法拦截功能。稍后将在 GroovyInterceptable 一节中详细介绍。
每当调用一个方法时,Groovy 会判断该方法是 POJO 还是 POGO。对于 POJO 对象,Groovy 会从 groovy.lang.MetaClassRegistry 读取它的 MetaClass,并委托方法调用;对于 POGO 对象,Groovy 将要采取更多的执行步骤,如下图所示:
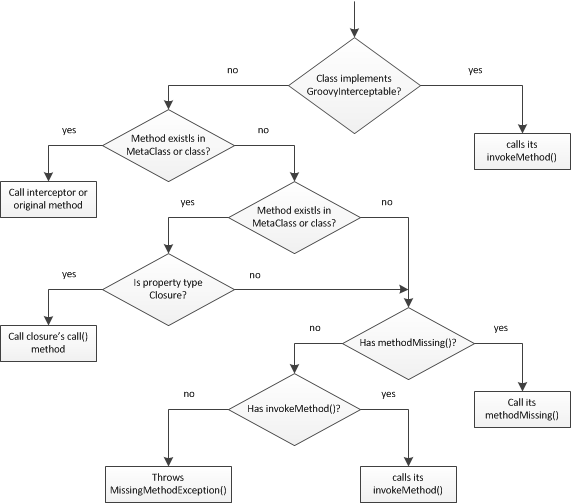
图 1 Groovy 拦截机制
1.1 GroovyObject 接口
groovy.lang.GroovyObject 是 Groovy 中的关键接口,地位类似于 Java 中的 Object 类。在 groovy.lang.GroovyObjectSupport 类中有一个 GroovyObject 的默认实现,负责将调用传输给 groovy.lang.MetaClass 对象。GroovyObject 源看起来如下所示:
package groovy.lang;
public interface GroovyObject {
Object invokeMethod(String name, Object args);
Object getProperty(String propertyName);
void setProperty(String propertyName, Object newValue);
MetaClass getMetaClass();
void setMetaClass(MetaClass metaClass);
}
1.1.1 invokeMethod
根据运行时元编程的Schema,当你所调用的方法没有在 Groovy 对象中提供的时候,调用该方法。下面这个例子中,使用了一个重写的 invokeMethod() 方法:
class SomeGroovyClass {
def invokeMethod(String name, Object args) {
return "called invokeMethod $name $args"
}
def test() {
return 'method exists'
}
}
def someGroovyClass = new SomeGroovyClass()
assert someGroovyClass.test() == 'method exists'
assert someGroovyClass.someMethod() == 'called invokeMethod someMethod []'
1.1.2 getProperty 与 setProperty
每次对属性的读取都可以通过重写当前对象的 getProperty() 来拦截,下面是一个简单的例子:
class SomeGroovyClass {
def property1 = 'ha'
def field2 = 'ho'
def field4 = 'hu'
def getField1() {
return 'getHa'
}
def getProperty(String name) {
if (name != 'field3')
return metaClass.getProperty(this, name) // 1⃣️
else
return 'field3'
}
}
def someGroovyClass = new SomeGroovyClass()
assert someGroovyClass.field1 == 'getHa'
assert someGroovyClass.field2 == 'ho'
assert someGroovyClass.field3 == 'field3'
assert someGroovyClass.field4 == 'hu'
1.1.3 getMetaClass 和 setMetaClass
可以访问一个对象 metaClass ,或者自定义 MetaClass 实现来改变默认的拦截机制。比如,你可以自己编写 MetaClass接口的实现,并将它赋予对象,从而改变拦截机制。
// getMetaclass
someObject.metaClass
// setMetaClass
someObject.metaClass = new OwnMetaClassImplementation()
你可以在下文的 GroovyInterceptable 主题中看到更多的范例。
1.2 get/setAttribute
该功能与 MetaClass 实现有关。在默认的实现中,可以不用调用 getter 与 setter 而访问字段。下列例子就反映了这种方法。
class SomeGroovyClass {
def field1 = 'ha'
def field2 = 'ho'
def getField1() {
return 'getHa'
}
}
def someGroovyClass = new SomeGroovyClass()
assert someGroovyClass.metaClass.getAttribute(someGroovyClass, 'field1') == 'ha'
assert someGroovyClass.metaClass.getAttribute(someGroovyClass, 'field2') == 'ho'
class POGO {
private String field
String property1
void setProperty1(String property1) {
this.property1 = "setProperty1"
}
}
def pogo = new POGO()
pogo.metaClass.setAttribute(pogo, 'field', 'ha')
pogo.metaClass.setAttribute(pogo, 'property1', 'ho')
assert pogo.field == 'ha'
assert pogo.property1 == 'ho'
1.3 methodMissing
Groovy 支持 methodMissing 这一概念。该方法与 invokeMethod 的不同之处在于:只有当方法分派失败,找不到指定名称或带有指定实参的方法时,才会调用该方法。
class Foo {
def methodMissing(String name, def args) {
return "this is me"
}
}
assert new Foo().someUnknownMethod(42l) == 'this is me'
通常,在使用 methodMissing 时,可能会将结果缓存起来,以备下次调用同样方法时使用。
比如像下面这样在 GORM 类中的动态查找器。它们是根据 methodMissing 来实现的:
class GORM {
def dynamicMethods = [...] // 一些利用正则表达式的动态方法
def methodMissing(String name, args) {
def method = dynamicMethods.find { it.match(name) }
if(method) {
GORM.metaClass."$name" = { Object[] varArgs ->
method.invoke(delegate, name, varArgs)
}
return method.invoke(delegate,name, args)
}
else throw new MissingMethodException(name, delegate, args)
}
}
注意,假如找到一个调用的方法,就会立刻使用 ExpandoMetaClass 动态地注册一个新方法。这样当下次调用同一方法时就会更方便。使用 methodMissing,并不会产生像调用 invokeMethod 那么大的开销,第二次调用代价也并不昂贵。
1.4 propertyMissing
Groovy 支持 propertyMissing 的概念,用来拦截失败的属性解析尝试。对 getter 方法而言,propertyMissing 接受一个包含属性名的 String 参数:
class Foo {
def propertyMissing(String name) { name }
}
assert new Foo().boo == 'boo'
当 Groovy 运行时无法找到指定属性的 getter 方法时,才会调用 propertyMissing(String) 方法。
对于 setter 方法,可以添加第二个 propertyMissing 定义来接收一个附加值参数。
class Foo {
def storage = [:]
def propertyMissing(String name, value) { storage[name] = value }
def propertyMissing(String name) { storage[name] }
}
def f = new Foo()
f.foo = "bar"
assert f.foo == "bar"
对于 methodMissing 来说,最佳实践应该是在运行时动态注册新属性,从而改善总体的查找性能。
另外,处理静态方法和属性的 methodMissing 和 propertyMissing 方法可以通过 ExpandoMetaClass 来添加。
1.5 GroovyInterceptable
groovy.lang.GroovyInterceptable 接口是一种标记接口,继承自超接口 GroovyObject,用于通知 Groovy 运行时通过方法分派器机制时应拦截的方法。
package groovy.lang;
public interface GroovyInterceptable extends GroovyObject {
}
当 Groovy 对象实现了 GroovyInterceptable 接口时,它的 invokeMethod() 方法就会在任何方法调用时调用。
下面就列举一个这种类型的方法:
class Interception implements GroovyInterceptable {
def definedMethod() { }
def invokeMethod(String name, Object args) {
'invokedMethod'
}
}
下面这段代码测试显示,无论方法是否存在,调用方法都将返回同样的值。
class InterceptableTest extends GroovyTestCase {
void testCheckInterception() {
def interception = new Interception()
assert interception.definedMethod() == 'invokedMethod'
assert interception.someMethod() == 'invokedMethod'
}
}
我们不能使用默认的 Groovy 方法(比如 println),因为这些方法已经被注入到了 Groovy 所有的对象中,自然会被拦截。
如果想要拦截所有的方法调用,但又不想实现 GroovyInterceptable 这个接口,那么我们可以在一个对象的 MetaClass上实现 invokeMethod()。该方法同时适于 POGO 与 POJO 对象,如下所示:
class InterceptionThroughMetaClassTest extends GroovyTestCase {
void testPOJOMetaClassInterception() {
String invoking = 'ha'
invoking.metaClass.invokeMethod = { String name, Object args ->
'invoked'
}
assert invoking.length() == 'invoked'
assert invoking.someMethod() == 'invoked'
}
void testPOGOMetaClassInterception() {
Entity entity = new Entity('Hello')
entity.metaClass.invokeMethod = { String name, Object args ->
'invoked'
}
assert entity.build(new Object()) == 'invoked'
assert entity.someMethod() == 'invoked'
}
}
参看MetaClasses 一节内容了解 MetaClass 的更多内容。
1.6 类别(Categories)
如果一个不受控制的类有额外的方法,在某些情况下反而是有用的。为了实现这种功能,Groovy 从 Objective-C 那里借用并实现了一个概念,叫做:类别(Categories)。
类别功能是利用类别类(category classes)来实现的。类别类的特殊之处在于,需要遵循特定的预定义规则才能定义扩展方法。
系统已经包括了一些类别,可以为类添加相应功能,从而使它们在 Groovy 环境中更为实用。
类别类默认是不能启用的。要想使用定义在类别类中的方法,必须要使用 GDK 所提供的 use 范围方法,并且可用于每一个 Groovy 对象实例内部。
use(TimeCategory) {
println 1.minute.from.now //1⃣️
println 10.hours.ago
def someDate = new Date() //2⃣️
println someDate - 3.months
}
1⃣️ TimeCategory 为 Integer 添加了方法
2⃣️ TimeCategory 为 Date 添加了方法
use 方法将类别类作为第一个形式参数,将一个闭包代码段作为第二个形式参数。在 Category 中,可以访问类别的任何方法。如上述代码所示,甚至 JDK 的 java.lang.Integer 或 java.util.Date 类都可以通过用户定义方法来丰富与增强。
类别不需要直接暴露给用户代码,如下所示:
class JPACategory{
// 下面让我们无需通过 JSR 委员会的支持来增强JPA EntityManager
static void persistAll(EntityManager em , Object[] entities) { //添加一个接口保存所有
entities?.each { em.persist(it) }
}
}
def transactionContext = {
EntityManager em, Closure c ->
def tx = em.transaction
try {
tx.begin()
use(JPACategory) {
c()
}
tx.commit()
} catch (e) {
tx.rollback()
} finally {
//清除所有资源
}
}
// 用户代码。他们经常会在出现异常时忘记关闭资源,有些甚至会忘记提交,所以不能指望他们。
EntityManager em; //probably injected
transactionContext (em) {
em.persistAll(obj1, obj2, obj3)
// 在这里制定一些逻辑代码,使范例更合理。
em.persistAll(obj2, obj4, obj6)
}
通过查看 groovy.time.TimeCategory 类,我们就会发现,扩展方法都声明为 static 方法。实际上,要想使类别类的方法能成功地添加到 use 代码段内的类中,这是类别类必须满足的条件之一。
public class TimeCategory {
public static Date plus(final Date date, final BaseDuration duration) {
return duration.plus(date);
}
public static Date minus(final Date date, final BaseDuration duration) {
final Calendar cal = Calendar.getInstance();
cal.setTime(date);
cal.add(Calendar.YEAR, -duration.getYears());
cal.add(Calendar.MONTH, -duration.getMonths());
cal.add(Calendar.DAY_OF_YEAR, -duration.getDays());
cal.add(Calendar.HOUR_OF_DAY, -duration.getHours());
cal.add(Calendar.MINUTE, -duration.getMinutes());
cal.add(Calendar.SECOND, -duration.getSeconds());
cal.add(Calendar.MILLISECOND, -duration.getMillis());
return cal.getTime();
}
// ...
另外一个必备条件是静态方法的第一个实参必须定义方法一旦被启用时,该方法所连接的类型;而另一个实参则是常见的方法用于形参的实参。
由于形参和静态方法的规范,类别方法定义可能会比普通方法定义稍微不太直观。因此,作为替代方案,Groovy 引入了 @Category 标记,利用这一标记,可在编译时将标注的类转化为类别类。
class Distance {
def number
String toString() { "${number}m" }
}
@Category(Number)
class NumberCategory {
Distance getMeters() {
new Distance(number: this)
}
}
use (NumberCategory) {
assert 42.meters.toString() == '42m'
}
使用 @Category 标记的优点在于,在使用实例方法时,可以不需要把目标类别当做第一个形参。目标类别类作为实参提供给标记使用。
1.7 MetaClasses
(待定)
1.7.1 自定义 metaclass 类
(待定)
授权 metaclass
(待定)
魔法包(Magic package)
(待定)
1.7.2 每个实例的 metaclass
(待定)
1.7.3 ExpandoMetaClass
Groovy 提供了一种叫做 ExpandoMetaClass 的特殊 MetaClass。其特殊之处在于,它允许可以使用灵活的闭包语法来动态添加或改变方法、构造函数、属性,甚至静态方法。
对于测试向导中所展示的模拟或存根情况,使用这些修改会特别有用。
每一个 Groovy 所提供的 java.lang.Class 都带有一个特殊的 metaClass 属性,它将提供一个 ExpandoMetaClass 实例的引用。该实例可用于添加方法或改变已有方法的行为。
默认情况下,ExpandoMetaClass 不支持继承。为了启用继承,必须在应用程序开始运作前(比如在 main 方法或 servlet bootstrap 中)就调用 ExpandoMetaClass#enableGlobally()。
下面这些内容详细介绍了 ExpandoMetaClass 在不同情况下的应用。
方法
一旦通过调用 metaClass 属性访问了 ExpandoMetaClass,就可以通过左移(<<)或等于号(=)操作符来添加方法。
注意,左移操作符是用于追加(append)一个新的方法。如果方法已经存在,则会抛出一个异常。如果需要替代(replace)一个方法,则需要使用 = 操作符。
下例展示了操作符是如何应用于 metaClass 的一个不存在的属性上,从而传入 Closure 代码块的一个实例的。
class Book {
String title
}
Book.metaClass.titleInUpperCase << {-> title.toUpperCase() }
def b = new Book(title:"The Stand")
assert "THE STAND" == b.titleInUpperCase()
上例显示,通过访问 metaClass 属性,可将一个新方法添加到一个类上,并可使用 << 或 = 操作符来指定一个 Closure 代码块。Closure 形参被解析为方法形参。形参方法可以通过 {→ …} 格式来添加。
属性
ExpandoMetaClass 支持两种方式来添加或重写属性。
首先,只需通过为 metaClass 赋予一个值,就可以声明一个可变属性(mutable property):
class Book {
String title
}
Book.metaClass.author = "Stephen King"
def b = new Book()
assert "Stephen King" == b.author
另一个方式是,通过使用添加实例方法的标准机制来添加 getter 和(或)setter 方法:
class Book {
String title
}
Book.metaClass.getAuthor << {-> "Stephen King" }
def b = new Book()
assert "Stephen King" == b.author
在上述源代码实例中,属性由闭包所指定,并且是一个只读属性。添加一个相等的 setter 方法也是可行的,但属性值需要存储起来以备后续使用。这种做法可以参照下面的例子:
class Book {
String title
}
def properties = Collections.synchronizedMap([:])
Book.metaClass.setAuthor = { String value ->
properties[System.identityHashCode(delegate) + "author"] = value
}
Book.metaClass.getAuthor = {->
properties[System.identityHashCode(delegate) + "author"]
}
但这并不是唯一的办法。比如在一个 servlet 容器中,将当前执行请求中的值当作请求属性保存起来(就像 Grails 中的某些情况一样)。
构造函数
构造函数可以通过特殊的 constructor 属性来添加。<< 或 = 操作符都可以用于指定 Closure 代码段。当代码在运行时执行时,Closure 实参会成为构造函数的实参。
class Book {
String title
}
Book.metaClass.constructor << { String title -> new Book(title:title) }
def book = new Book('Groovy in Action - 2nd Edition')
assert book.title == 'Groovy in Action - 2nd Edition'
但在添加构造函数时要格外注意,因为这极易造成栈溢出。
静态方法
添加静态方法的方法与添加实例方法基本一样,只不过要在方法名前加上 static 修饰符。
class Book {
String title
}
Book.metaClass.static.create << { String title -> new Book(title:title) }
def b = Book.create("The Stand")
借用方法
利用 ExpandoMetaClass,可以使用 Groovy 方法点标记法从其他类中借用方法。
class Person {
String name
}
class MortgageLender {
def borrowMoney() {
"buy house"
}
}
def lender = new MortgageLender()
Person.metaClass.buyHouse = lender.&borrowMoney
def p = new Person()
assert "buy house" == p.buyHouse()
动态方法名
在 Groovy 中,既然可以使用字符串作为属性名,那么反过来,也可以在运行时动态创建方法与属性名。要想创建具有动态名称的方法,只需使用将字符串引用为属性名的语言特性。
class Person {
String name = "Fred"
}
def methodName = "Bob"
Person.metaClass."changeNameTo${methodName}" = {-> delegate.name = "Bob" }
def p = new Person()
assert "Fred" == p.name
p.changeNameToBob()
assert "Bob" == p.name
同样的概念可以应用于静态方法与属性。
Grails Web 应用框架可以算是动态方法名的一个应用范例。“动态编解码器”的概念正是通过动态方法名来实现的。
HTMLCodec 类
class HTMLCodec {
static encode = { theTarget ->
HtmlUtils.htmlEscape(theTarget.toString())
}
static decode = { theTarget ->
HtmlUtils.htmlUnescape(theTarget.toString())
}
}
上例实现了一个编解码器。Grails 提供了多种编解码器实现,每种实现都定义在一个类中。在运行时,会在应用类路径上出现多个编解码器类。在应用启动时,框架会将 encodeXXX 和 decodeXXX 方法添加到特定的元类中,这里的 XXX 是指编解码器类名的前面部分(如 encodeHTML)。下面采用了一些 Groovy 伪码来表示这种机制:
def codecs = classes.findAll { it.name.endsWith('Codec') }
codecs.each { codec ->
Object.metaClass."encodeAs${codec.name-'Codec'}" = { codec.newInstance().encode(delegate) }
Object.metaClass."decodeFrom${codec.name-'Codec'}" = { codec.newInstance().decode(delegate) }
}
def html = '<html><body>hello</body></html>'
assert '<html><body>hello</body></html>' == html.encodeAsHTML()
运行时发现
在运行时阶段执行某个方法时,还有其他什么方法或属性存在?这个问题往往是非常有用的。ExpandoMetaClass 提供了下列方法(截止目前):
getMetaMethodhasMetaMethodgetMetaPropertyhasMetaProperty
为什么不能单纯使用反射呢?因为 Groovy 的独特性——它包含两种方法,一种是“真正”的方法,而另一种则是只在运行时才能获取并使用的方法。后者有时(但也并不总是被)称为元方法(MetaMethods)。元方法告诉我们在运行时究竟能够使用何种方法,从而使代码能够适应。
这一点特别适用于重写 invokeMethod、getProperty 和/或 setProperty 时。
GroovyObject 方法
ExpandoMetaClass 的另一个特性是能够允许重写 invokeMethod、getProperty 和 setProperty。groovy.lang.GroovyObject 类中能找到这三个方法。
下面范例展示了如何重写 invokeMethod:
class Stuff {
def invokeMe() { "foo" }
}
Stuff.metaClass.invokeMethod = { String name, args ->
def metaMethod = Stuff.metaClass.getMetaMethod(name, args)
def result
if(metaMethod) result = metaMethod.invoke(delegate,args)
else {
result = "bar"
}
result
}
def stf = new Stuff()
assert "foo" == stf.invokeMe()
assert "bar" == stf.doStuff()
重写静态方法的逻辑跟之前我们见过的重写实例方法的逻辑基本相同,唯一不同之处在于对 metaClass.static 属性的访问,以及为了获取静态 MetaMethod 实例而对 getStaticMethodName 的调用。
重写静态 invokeMethod
ExpandoMetaClass 甚至可以允许利用一种特殊的 invokeMethod 格式重写静态方法。
class Stuff {
static invokeMe() { "foo" }
}
Stuff.metaClass.'static'.invokeMethod = { String name, args ->
def metaMethod = Stuff.metaClass.getStaticMetaMethod(name, args)
def result
if(metaMethod) result = metaMethod.invoke(delegate,args)
else {
result = "bar"
}
result
}
assert "foo" == Stuff.invokeMe()
assert "bar" == Stuff.doStuff()
扩展接口
可以利用 ExpandoMetaClass 为接口添加方法,但要想这样做,必须在应用启动前使用 ExpandoMetaClass.enableGlobally() 方法实施全局启用。
List.metaClass.sizeDoubled = {-> delegate.size() * 2 }
def list = []
list << 1
list << 2
assert 4 == list.sizeDoubled()
1.8 扩展模块
1.8.1 扩展现有类
利用扩展模块,可以为现有类添加新方法,这些类中可以包括 JDK 中那样的预编译类。这些新方法与通过元类或类别定义的方法不同,它们是全局可用的。比如当你编写:
标准扩展方法
def file = new File(...)
def contents = file.getText('utf-8')
File 类中并不存在 getText 方法,但 Groovy 知道它的定义是在一个特殊类中 ResourceGroovyMethods:
ResourceGroovyMethods.java
public static String getText(File file, String charset) throws IOException {
return IOGroovyMethods.getText(newReader(file, charset));
}
你可能还注意到扩展方法是在“辅助”类(定义了多种扩展方法)中通过一个静态方法来定义的。getText 的第一个实参对应着接受者,而另一个形参则对应着扩展方法的实参。因此,我们才在 File 类(因为第一个实参是 File 类型)中定义了一个名为 getText 的方法,它只传递了一个实参(String类型的编码)。
创建扩展模块的过程非常简单:
- 如上例般编写扩展类;
- 编写模块描述符文件。
然后,还必须让 Groovy 能找到该扩展模块,这只需将扩展模块类和描述符放入类路径即可。这意味着有以下两种方法:
- 直接在类路径上提供类和模块描述符。
- 将扩展模块打包为 jar 文件,便于重用。
扩展模块可以为类添加两种方法:
- 实例方法(类实例上调用)
- 静态方法(仅供类自身调用)
1.8.2 实例方法
为现有类添加实例方法,需要创建一个扩展类。比如想在 Integer 上加一个 maxRetries 方法,可以采取下面的方式:
MaxRetriesExtension.groovy
class MaxRetriesExtension { //1⃣️
static void maxRetries(Integer self, Closure code) { //2⃣️
int retries = 0
Throwable e
while (retries<self) {
try {
code.call()
break
} catch (Throwable err) {
e = err
retries++
}
}
if (retries==0 && e) {
throw e
}
}
}
1⃣️ 扩展类
2⃣️ 静态方法的第一个实际参数对应着消息的接受者,也就是扩展实例。
然后,在已经声明了扩展类之后,你可以这样调用它:
int i=0
5.maxRetries {
i++
}
assert i == 1
i=0
try {
5.maxRetries {
throw new RuntimeException("oops")
}
} catch (RuntimeException e) {
assert i == 5
}
1.8.3 静态方法
也可以为类添加静态方法。这种情况下,静态方法需要在自己的文件中定义。
StaticStringExtension.groovy
class StaticStringExtension { // 1⃣️
static String greeting(String self) { // 2⃣️
'Hello, world!'
}
}
1⃣️ 静态扩展类 2⃣️ 静态方法的第一个实参对应着将要扩展并且还未使用的类
在这种情况下,可以直接在 String 类中调用它:
assert String.greeting() == 'Hello, world!'
1.8.4 模块描述符
为了使 Groovy 能够加载扩展方法,你必须声明扩展辅助类。必须在 META-INF/services 目录中创建一个名为 org.codehaus.groovy.runtime.ExtensionModule 的文件。
org.codehaus.groovy.runtime.ExtensionModule
moduleName=Test module for specifications
moduleVersion=1.0-test
extensionClasses=support.MaxRetriesExtension
staticExtensionClasses=support.StaticStringExtension
该模块描述符需要 4 个键:
- moduleName:模块名称
- moduleVersion:模块版本。注意,版本号只能用于检查是否将同一个模块加载了两种不同的版本。
- extensionClasses:实例方法的扩展辅助类列表。可以提供几个类,但要用逗号分隔它们。
- staticExtensionClasses:静态方法的扩展辅助类列表。可以提供几个类,也要用逗号分隔它们。
注意,模块并不一定要既能定义静态辅助类,又能定义实例辅助类。你可以在一个模块中添加几个类,也可以在单一模块中扩展不同的类,甚至还可以在单一的扩展类中使用不同的类,但强烈建议将扩展方法按功能集分入不同的类。
1.8.5 扩展模块和类路径
值得注意的是,不能在代码使用已编译扩展模块的时候,你无法使用它。这意味着,要想使用扩展模块,在将要使用它的代码被编译前,它就必须以已编译类的形式出现在类路径上。这其实就是说,与扩展类同一源单位中不能出现测试类(test class),然而,测试源通常在实际中与常规源是分开的,在构建的另一个步骤中执行,所以这根本不会造成任何不良影响。
1.8.6 类型检查的兼容性
与类别不同的是,扩展模块与类型检查是兼容的:如果在类路径上存在这些模块,类检查器就会知道扩展方法,并不会说明调用的时间。它们与静态编译也是兼容的。
2 编译时元编程
在 Groovy 中,编译时元编程能够容许编译时生成代码。这种转换会影响程序的抽象语法树(AST,Abstract Syntax Tree),这也就是我们在 Groovy 中把它成为 AST 转换的原因。AST 转换能使我们实时了解编译过程,继而修改 AST,从而继续编译过程,生成常规的字节码。与运行时元编程相比,在类文件自身中(也就是说,在字节码内)就可以看到变化。这一点是非常重要的,比如说当你想让转换成为类抽象一部分时(实现接口,继承抽象类,等等),或者甚至当需要让类可从 Java (或其他的 JVM 语言)中调用时。例如,AST 转换可以为一个类添加一些方法。如果用运行时元编程来实现的话,新方法只能可见于 Groovy;而用编译时元编程来实现,新方法也可以在 Java 中显现出来。最后一点也同样重要,编译时元编程的性能要好过运行时元编程(因为不再需要初始化过程)。
本节中,我们将要探讨与 Groovy 分发版所绑定的各种编译时转换,而在随后的一节中,再来介绍如何实现自定义的 AST 转换,以及这一技术的优点。
2.1 可用的 AST 转换
Groovy 有很多可用的 AST 转换,它们可满足不同的需求:减少样板文件(代码生成),实现设计模式(委托等模式),记录日志,声明并发,克隆,更安全地记录脚本,编译微调,实现 Swing 模式,测试并最终管理各种依赖。如果发现没有任何一个转换能够满足特定需求,还可以自定义转换,详情请看:开发自定义 AST 转换。
AST 转换可分为两大类:
- 全局 AST 转换。它们的应用是透明的,具有全局性,只要能在类路径上找到它们,就可以使用它们。
- 本地 AST 转换。利用标记来注解源代码。与全局 AST 转换不同,本地 AST 转换可能支持形式参数。
Groovy 并不带有任何的全局 AST 转换,但你可以在这里找到一些可用的本地 AST 转换:
2.1.1 代码生成转换
这一类转换包含能够去除样板文件代码的 AST 转换。样板文件代码通常是一种必须编写然而又没有任何有用信息的代码。通过自动生成这种样板文件代码,剩下必须要写的代码就变得清晰而简洁起来,从而就减少了因为样板文件代码不正确而引入的错误。
@groovy.transform.ToString
@ToString AST 转换能够生成人类可读的类的 toString 形式。比如,像下面这样注解 Person 类会自动为你生成 toString 方法。
import groovy.transform.ToString
@ToString
class Person {
String firstName
String lastName
}
根据这种定义,下列断言就得以通过,意味着已经生成了一个 toString 方法,它会从类中获取字段值,并将它们打印出来。
def p = new Person(firstName: 'Jack', lastName: 'Nicholson')
assert p.toString() == 'Person(Jack, Nicholson)'
@ToString 标注接受以下列表中显示的几个参数。
| 属性 | 默认值 | 描述 | 范例 |
|---|---|---|---|
| includeNames | false | 是否在生成的 toString 中包含属性名 | @ToString(includeNames=true)
class Person {
String firstName
String lastName
}
def p = new Person(firstName: 'Jack', lastName: 'Nicholson')
assert p.toString() == 'Person(firstName:Jack, lastName:Nicholson)' |
| excludes | 空列表 | 从 toString 中排除的属性列表 | @ToString(excludes=['firstName'])
class Person {
String firstName
String lastName
}
def p = new Person(firstName: 'Jack', lastName: 'Nicholson')
assert p.toString() == 'Person(Nicholson)' |
| includes | 空列表 | toString 中包含的字段列表 | @ToString(includes=['lastName'])
class Person {
String firstName
String lastName
}
def p = new Person(firstName: 'Jack', lastName: 'Nicholson')
assert p.toString() == 'Person(Nicholson)' |
| includeSuper | False | 超类是否应在 toString 中 | @ToString
class Id { long id }
@ToString(includeSuper=true)
class Person extends Id {
String firstName
String lastName
}
def p = new Person(id:1, firstName: 'Jack', lastName: 'Nicholson')
assert p.toString() == 'Person(Jack, Nicholson, Id(1))' |
| includeSuperProperties | False | 超属性是否应包含在 toString 中 | class Person {
String name
}
@ToString(includeSuperProperties = true, includeNames = true)
class BandMember extends Person {
String bandName
}
def bono = new BandMember(name:'Bono', bandName: 'U2').toString()
assert bono.toString() == 'BandMember(bandName:U2, name:Bono)' |
| includeFields | False | 除了属性之外,字段是否应包括在 toString 中 | @ToString(includeFields=true)
class Person {
String firstName
String lastName
private int age
void test() {
age = 42
}
}
def p = new Person(firstName: 'Jack', lastName: 'Nicholson')
p.test()
assert p.toString() == 'Person(Jack, Nicholson, 42)' |
| ignoreNulls | False | 是否应显示带有 null 值的属性/字段 | @ToString(ignoreNulls=true)
class Person {
String firstName
String lastName
}
def p = new Person(firstName: 'Jack')
assert p.toString() == 'Person(Jack)' |
| includePackage | False | 在 toString 中使用完全限定的类名,而非简单类名 | @ToString(includePackage=true)
class Person {
String firstName
String lastName
}
def p = new Person(firstName: 'Jack', lastName:'Nicholson')
assert p.toString() == 'acme.Person(Jack, Nicholson)' |
| cache | False | 缓存 toString 字符串。如果类不可变,是否应只设为 true | @ToString(cache=true)
class Person {
String firstName
String lastName
}
def p = new Person(firstName: 'Jack', lastName:'Nicholson')
def s1 = p.toString()
def s2 = p.toString()
assert s1 == s2
assert s1 == 'Person(Jack, Nicholson)'
assert s1.is(s2) // 同一实例 |
@groovy.transform.EqualsAndHashCode
@EqualsAndHashCode AST 转换主要目的是为了生成 equals 和 hashCode 方法。生成的散列码遵循 Josh Bloch 所著的 Effective Java 中所介绍的最佳实践:
import groovy.transform.EqualsAndHashCode
@EqualsAndHashCode
class Person {
String firstName
String lastName
}
def p1 = new Person(firstName: 'Jack', lastName: 'Nicholson')
def p2 = new Person(firstName: 'Jack', lastName: 'Nicholson')
assert p1==p2
assert p1.hashCode() == p2.hashCode()
下面是一些用来调整 @EqualsAndHashCode 行为的选项:
| 属性 | 默认值 | 描述 | 范例 |
| | |||
| excludes | 空列表 | 从 equals / hashCode 中需要排除的属性列表 | import groovy.transform.EqualsAndHashCode
@EqualsAndHashCode(excludes=['firstName'])
class Person {
String firstName
String lastName
}
def p1 = new Person(firstName: 'Jack', lastName: 'Nicholson')
def p2 = new Person(firstName: 'Bob', lastName: 'Nicholson')
assert p1==p2
assert p1.hashCode() == p2.hashCode() |
| includes | 空列表 | equals/hashCode 所包括的字段列表 | import groovy.transform.EqualsAndHashCode
@EqualsAndHashCode(includes=['lastName'])
class Person {
String firstName
String lastName
}
def p1 = new Person(firstName: 'Jack', lastName: 'Nicholson')
def p2 = new Person(firstName: 'Bob', lastName: 'Nicholson')
assert p1==p2
assert p1.hashCode() == p2.hashCode() |
| callSuper | False | 在 equals 或 hashcode 计算中是否包含 super | import groovy.transform.EqualsAndHashCode
@EqualsAndHashCode
class Living {
String race
}
@EqualsAndHashCode(callSuper=true)
class Person extends Living {
String firstName
String lastName
}
def p1 = new Person(race:'Human', firstName: 'Jack', lastName: 'Nicholson')
def p2 = new Person(race: 'Human beeing', firstName: 'Jack', lastName: 'Nicholson')
assert p1!=p2
assert p1.hashCode() != p2.hashCode() |
| includeFields | False | 除了属性之外,是否应将字段包含在 equals / hashCode 之中 | @ToString(includeFields=true)
class Person {
String firstName
String lastName
private int age
void test() {
age = 42
}
}
def p = new Person(firstName: 'Jack', lastName: 'Nicholson')
p.test()
assert p.toString() == 'Person(Jack, Nicholson, 42)' |
| cache | False | 缓存 hashCode 计算。如果类不可改变,是否只应将其设为 true。 | @ToString(cache=true)
class Person {
String firstName
String lastName
}
def p = new Person(firstName: 'Jack', lastName:'Nicholson')
def s1 = p.toString()
def s2 = p.toString()
assert s1 == s2
assert s1 == 'Person(Jack, Nicholson)'
assert s1.is(s2) // 同一实例 |
| useCanEqual | True | equals 是否应调用 canEqual 辅助方法 | 参看 http://www.artima.com/lejava/articles/equality.html |
@groovy.transform.TupleConstructor
@TupleConstructor 标注主要用处在于,通过生成构造函数消除样板文件代码。为每个属性创建一个元组构造函数,并配置默认值(使用的是 Java 默认值)。比如,下面的代码就会生成 3 个构造函数:
import groovy.transform.TupleConstructor
@TupleConstructor
class Person {
String firstName
String lastName
}
// 传统的映射样式的构造函数
def p1 = new Person(firstName: 'Jack', lastName: 'Nicholson')
// 生成的元组构造函数
def p2 = new Person('Jack', 'Nicholson')
// 生成的元组构造函数,带有第二个属性的默认值
def p3 = new Person('Jack')
第一个构造函数是一个不带实际参数的构造函数,能够实现传统的映射样式的构造。值得一提的是,如果第一个属性(或字段)类型为 LinkedHashMap,或者如果存在一个单一的 Map,AbstractMap 或 HashMap 类型的属性(或字段),则映射样式的变换不可用。
另一个构造函数则是按照属性定义顺序来获取属性从而生成的。Groovy 会生成与属性(或字段,具体是什么则取决于选项)相对应的构造函数。
@TupleConstructor AST 转换接受以下几种配置选项:
| 属性 | 默认值 | 描述 | 范例 |
| excludes | 空列表 | 元组构造函数生成过程中排除的属性列表 | import groovy.transform.TupleConstructor
@TupleConstructor(excludes=['lastName'])
class Person {
String firstName
String lastName
}
def p1 = new Person(firstName: 'Jack', lastName: 'Nicholson')
def p2 = new Person('Jack')
try {
// will fail because the second property is excluded
def p3 = new Person('Jack', 'Nicholson')
} catch (e) {
assert e.message.contains ('Could not find matching constructor')
} |
| includes | 空列表 | 元组构造函数生成过程中包括的字段列表 | import groovy.transform.TupleConstructor
@TupleConstructor(includes=['firstName'])
class Person {
String firstName
String lastName
}
def p1 = new Person(firstName: 'Jack', lastName: 'Nicholson')
def p2 = new Person('Jack')
try {
// will fail because the second property is not included
def p3 = new Person('Jack', 'Nicholson')
} catch (e) {
assert e.message.contains ('Could not find matching constructor')
} |
| includeFields | False | 除了属性之外,元组构造函数生成过程中应包含的字段 | import groovy.transform.TupleConstructor
@TupleConstructor(includeFields=true)
class Person {
String firstName
String lastName
private String occupation
public String toString() {
"$firstName $lastName: $occupation"
}
}
def p1 = new Person(firstName: 'Jack', lastName: 'Nicholson', occupation: 'Actor')
def p2 = new Person('Jack', 'Nicholson', 'Actor')
assert p1.firstName == p2.firstName
assert p1.lastName == p2.lastName
assert p1.toString() == 'Jack Nicholson: Actor'
assert p1.toString() == p2.toString() |
| includeProperties | True | 元组构造函数生成过程中应包括的属性 | import groovy.transform.TupleConstructor
@TupleConstructor(includeProperties=false)
class Person {
String firstName
String lastName
}
def p1 = new Person(firstName: 'Jack', lastName: 'Nicholson')
try {
def p2 = new Person('Jack', 'Nicholson')
} catch(e) {
// 因为没有包括进属性,所以将失败
} |
| includeSuperFields | False | 元组构造函数生成过程中应包括的超级类中的字段 | import groovy.transform.TupleConstructor
class Base {
protected String occupation
public String occupation() { this.occupation }
}
@TupleConstructor(includeSuperFields=true)
class Person extends Base {
String firstName
String lastName
public String toString() {
"$firstName $lastName: ${occupation()}"
}
}
def p1 = new Person(firstName: 'Jack', lastName: 'Nicholson', occupation: 'Actor')
def p2 = new Person('Actor', 'Jack', 'Nicholson')
assert p1.firstName == p2.firstName
assert p1.lastName == p2.lastName
assert p1.toString() == 'Jack Nicholson: Actor'
assert p2.toString() == p1.toString() |
| includeSuperProperties | True | 元组构造函数生成过程中应包含的超级类中的属性 | import groovy.transform.TupleConstructor
class Base {
String occupation
}
@TupleConstructor(includeSuperProperties=true)
class Person extends Base {
String firstName
String lastName
public String toString() {
"$firstName $lastName: $occupation"
}
}
def p1 = new Person(firstName: 'Jack', lastName: 'Nicholson')
def p2 = new Person('Actor', 'Jack', 'Nicholson')
assert p1.firstName == p2.firstName
assert p1.lastName == p2.lastName
assert p1.toString() == 'Jack Nicholson: null'
assert p2.toString() == 'Jack Nicholson: Actor' |
| callSuper | False | 在对父构造函数调用中,超级属性究竟是被调用,还是被设置为属性 | import groovy.transform.TupleConstructor
class Base {
String occupation
Base() {}
Base(String job) { occupation = job?.toLowerCase() }
}
@TupleConstructor(includeSuperProperties = true, callSuper=true)
class Person extends Base {
String firstName
String lastName
public String toString() {
"$firstName $lastName: $occupation"
}
}
def p1 = new Person(firstName: 'Jack', lastName: 'Nicholson')
def p2 = new Person('ACTOR', 'Jack', 'Nicholson')
assert p1.firstName == p2.firstName
assert p1.lastName == p2.lastName
assert p1.toString() == 'Jack Nicholson: null'
assert p2.toString() == 'Jack Nicholson: actor' |
| force | False | 默认,如果构造函数已经定义,转换将不起作用。将该属性设为 true,将生成构造函数,需要人工检查没有定义重复的构造函数 | 参见 java 文档 |
@groovy.transform.Canonical
@Canonical AST 转换结合了 @ToString、@EqualsAndHashCode 和 @TupleConstructor 这三个标记的效果。
import groovy.transform.Canonical
@Canonical
class Person {
String firstName
String lastName
}
def p1 = new Person(firstName: 'Jack', lastName: 'Nicholson')
assert p1.toString() == 'Person(Jack, Nicholson)' // @ToString 的效果
def p2 = new Person('Jack','Nicholson') // @TupleConstructor 的效果
assert p2.toString() == 'Person(Jack, Nicholson)'
assert p1==p2 // @EqualsAndHashCode 的效果
assert p1.hashCode()==p2.hashCode() // @EqualsAndHashCode 的效果
类似的不可变类可以通过 @Immutable AST 转换来生成。@Canonical AST 转换支持以下几种配置选项:
| 属性 | 默认值 | 描述 | 范例 |
| excludes | 空列表 | 元组构造函数生成过程中排除的属性列表 | import groovy.transform.Canonical
@Canonical(excludes=['lastName'])
class Person {
String firstName
String lastName
}
def p1 = new Person(firstName: 'Jack', lastName: 'Nicholson')
assert p1.toString() == 'Person(Jack)' // @ToString 的效果
def p2 = new Person('Jack') // @TupleConstructor 的效果
assert p2.toString() == 'Person(Jack)'
assert p1==p2 // @EqualsAndHashCode 的效果
assert p1.hashCode()==p2.hashCode() // @EqualsAndHashCode 的效果 |
| includes | 空列表 | 元组构造函数生成过程中应包括的字段列表 | import groovy.transform.Canonical
@Canonical(includes=['firstName'])
class Person {
String firstName
String lastName
}
def p1 = new Person(firstName: 'Jack', lastName: 'Nicholson')
assert p1.toString() == 'Person(Jack)' // @ToString 的效果
def p2 = new Person('Jack') // @TupleConstructor 的效果
assert p2.toString() == 'Person(Jack)'
assert p1==p2 // @EqualsAndHashCode 的效果
assert p1.hashCode()==p2.hashCode() // @EqualsAndHashCode 的效果 |
@groovy.transform.InheritConstructors
@InheritConstructor AST 转换意在生成匹配超级构造函数的构造函数。在重写异常类时,这种标记非常有用。
import groovy.transform.InheritConstructors
@InheritConstructors
class CustomException extends Exception {}
// 所有这些都生成构造函数
new CustomException()
new CustomException("A custom message")
new CustomException("A custom message", new RuntimeException())
new CustomException(new RuntimeException())
// Java 7 only
// new CustomException("A custom message", new RuntimeException(), false, true)
@InheritConstructor AST 转换支持以下几种配置选项:
| 属性 | 默认值 | 描述 | 范例 |
| constructorAnnotations | False | 是否在拷贝时携带构造函数的标记 | @Retention(RetentionPolicy.RUNTIME)
@Target([ElementType.CONSTRUCTOR])
public @interface ConsAnno {}
class Base {
@ConsAnno Base() {}
}
@InheritConstructors(constructorAnnotations=true)
class Child extends Base {}
assert Child.constructors[0].annotations[0].annotationType().name == 'ConsAnno' |
| parameterAnnotations | False | 在复制构造函数时,是否携带构造函数参数中的标记 | @Retention(RetentionPolicy.RUNTIME)
@Target([ElementType.PARAMETER])
public @interface ParamAnno {}
class Base {
Base(@ParamAnno String name) {}
}
@InheritConstructors(parameterAnnotations=true)
class Child extends Base {}
assert Child.constructors[0].parameterAnnotations[0][0].annotationType().name == 'ParamAnno' |
@groovy.lang.Category
@Category AST 转换简化了 Groovy 类别的创建工作。过去,Groovy 创建类别的方法如下所示:
class TripleCategory {
public static Integer triple(Integer self) {
3*self
}
}
use (TripleCategory) {
assert 9 == 3.triple()
}
通过 @Category 转换,我们能通过实例样式(而不必采用静态样式类)的类来实现。从而不必让每个方法的第一个参数是接收者。类型可以写成下面这样:
@Category(Integer)
class TripleCategory {
public Integer triple() { 3*this }
}
use (TripleCategory) {
assert 9 == 3.triple()
}
注意,在类中可以通过 this 引用。值得一提的是,在类别类中使用实例字段这一做法本身并不安全:类并不具有状态性(与特征不同)。
@groovy.transform.IndexedProperty
@IndexedProperty 标记用于为列表或数组类型的属性生成索引化的 getter/setter 方法。如果像利用 Java 来使用一个 Groovy 类,这就显得特别有用。Groovy 支持利用 Gpath 去访问属性,而这一点不适用于 Java。@IndexedProperty 标记生成索引化属性的方式如下:
class SomeBean {
@IndexedProperty String[] someArray = new String[2]
@IndexedProperty List someList = []
}
def bean = new SomeBean()
bean.setSomeArray(0, 'value')
bean.setSomeList(0, 123)
assert bean.someArray[0] == 'value'
assert bean.someList == [123]
@groovy.lang.Lazy
@Lazy AST 转换实现了字段的惰性初始化。例如下列代码:
class SomeBean {
@Lazy LinkedList myField
}
它将产生如下代码:
List $myField
List getMyField() {
if ($myField!=null) { return $myField }
else {
$myField = new LinkedList()
return $myField
}
}
用于初始化字段的默认值是具有声明类型的默认构造函数。使用定义一个默认值,
class SomeBean {
@Lazy LinkedList myField = { ['a','b','c']}()
}
在这种情况下,生成的代码如下所示:
List $myField
List getMyField() {
if ($myField!=null) { return $myField }
else {
$myField = { ['a','b','c']}()
return $myField
}
}
如果字段声明多变,初始化可以通过双重检查锁定模式来同步。
使用 soft=true 参数,辅助字段将转而使用 SoftReference,从而较为简单地实现了缓存。在这种情况下,如果垃圾回收器决定收集引用,会在下次访问字段之时进行初始化。
@groovy.lang.Newify
@Newify AST 转换用于为构造对象提供替代语法:
- 使用
Python风格的语法:
@Newify([Tree,Leaf])
class TreeBuilder {
Tree tree = Tree(Leaf('A'),Leaf('B'),Tree(Leaf('C')))
}
- 使用
Ruby风格的语法:
@Newify([Tree,Leaf])
class TreeBuilder {
Tree tree = Tree.new(Leaf.new('A'),Leaf.new('B'),Tree.new(Leaf.new('C')))
}
将 auto 标志设为 false,可禁用 Ruby 风格的语法表达形式。
@groovy.transform.Sortable
@Sortable AST 转换被用于帮助编写能够实现 Comparable 接口并可按照多种属性快速进行排序的类。下面的范例展示了它的易用性,其中,我们注释了 Person 类:
import groovy.transform.Sortable
@Sortable class Person {
String first
String last
Integer born
}
所产生的类具有下列属性:
- 实现了
Comparable接口。 - 包含一个
compareTo方法,以及根据first、last、born属性自然排序的一个实现。 - 拥有返回比较器的三个方法:
comparatorByFirst、comparatorByLast和comparatorByBorn。
生成的 compareTo 方法如下所示:
public int compareTo(java.lang.Object obj) {
if (this.is(obj)) {
return 0
}
if (!(obj instanceof Person)) {
return -1
}
java.lang.Integer value = this.first <=> obj.first
if (value != 0) {
return value
}
value = this.last <=> obj.last
if (value != 0) {
return value
}
value = this.born <=> obj.born
if (value != 0) {
return value
}
return 0
}
作为生成的比较器之一,comparatorByFirst 拥有的 compare 方法应如下所示:
public int compare(java.lang.Object arg0, java.lang.Object arg1) {
if (arg0 == arg1) {
return 0
}
if (arg0 != null && arg1 == null) {
return -1
}
if (arg0 == null && arg1 != null) {
return 1
}
return arg0.first <=> arg1.first
}
Person 类可以用在希望出现 Comparable 的地方,生成的比较器则出现在希望出现 Comparator 的任何地方,如下所示:
def people = [
new Person(first: 'Johnny', last: 'Depp', born: 1963),
new Person(first: 'Keira', last: 'Knightley', born: 1985),
new Person(first: 'Geoffrey', last: 'Rush', born: 1951),
new Person(first: 'Orlando', last: 'Bloom', born: 1977)
]
assert people[0] > people[2]
assert people.sort()*.last == ['Rush', 'Depp', 'Knightley', 'Bloom']
assert people.sort(false, Person.comparatorByFirst())*.first == ['Geoffrey', 'Johnny', 'Keira', 'Orlando']
assert people.sort(false, Person.comparatorByLast())*.last == ['Bloom', 'Depp', 'Knightley', 'Rush']
assert people.sort(false, Person.comparatorByBorn())*.last == ['Rush', 'Depp', 'Bloom', 'Knightley']
通常,所有的属性(properties)都会按照它们在定义时的优先顺序应用于生成的 compareTo 方法中。通过提供在 includes 或 excludes 注释的属性(attribute)中的一列属性(property)名,可以从生成的 compareTo 方法中包括或排除某些特定的属性(property)。如果使用 include,在对比时,属性(property)名的顺序将决定属性的优先级别。为了说明这一点,请看下列这个 Person 类定义:
@Sortable(includes='first,born') class Person {
String last
int born
String first
}
其中包含两个对比方法:comparatorByFirst 和 comparatorByBorn。生成的 compareTo 方法如下所示:
public int compareTo(java.lang.Object obj) {
if (this.is(obj)) {
return 0
}
if (!(obj instanceof Person)) {
return -1
}
java.lang.Integer value = this.first <=> obj.first
if (value != 0) {
return value
}
value = this.born <=> obj.born
if (value != 0) {
return value
}
return 0
}
Person 类可以这样用:
def people = [
new Person(first: 'Ben', last: 'Affleck', born: 1972),
new Person(first: 'Ben', last: 'Stiller', born: 1965)
]
assert people.sort()*.last == ['Stiller', 'Affleck']
@groovy.transform.builder.Builder
@Builder AST 转换用来辅助编写能够使用 fluent API 调用所创建的类。该转换支持多种构建策略,以期涵盖多种用例,而且还可以采用一些配置选项来自定义构建过程。如果你非常擅长 AST,也可以定义自己的策略类。下面这张表列出了所有可能用到的与 Groovy 捆绑的策略,以及每个策略支持的配置选项。
| 策略 | 描述 | 构建类名 | 构建器方法名 | 构建方法名 | 前缀 | 包含与排除 |
|---|---|---|---|---|---|---|
SimpleStrategy | 链接的 setter | n/a | n/a | n/a | 有,默认是'set' | 有 |
ExternalStrategy | 显式构建器类 | n/a | n/a | 默认是 'build' | 有,默认是 "" | 有 |
DefaultStrategy | 创建内嵌辅助类 | 存在,默认是<类型名>Builder | 有,默认是 'builder' | 有,默认是 'build' | 有,默认是 'default' | 有 |
InitializerStrategy | 创建提供类型安全 fluent 创建的内嵌辅助类 | 存在,默认是<类型名>Initializer | 有,默认是 'createInitializer' | 有,默认 'create',但往往只用于内部。 | 有,默认是 "" | 有 |
SimpleStrategy
为了使用 SimpleStrategy,可以使用 @Builder 注释 Groovy 类,并指定策略。如下所示:
import groovy.transform.builder.*
@Builder(builderStrategy=SimpleStrategy)
class Person {
String first
String last
Integer born
}
用链接的方式来调用 setter 方法,如下所示:
def p1 = new Person().setFirst('Johnny').setLast('Depp').setBorn(1963)
assert "$p1.first $p1.last" == 'Johnny Depp' 对于每个属性(property)将会创建一个 setter 方法:
public Person setFirst(java.lang.String first) {
this.first = first
return this
}
然后指定一个前缀:
import groovy.transform.builder.*
@Builder(builderStrategy=SimpleStrategy, prefix="")
class Person {
String first
String last
Integer born
}
调用链接的 setter 方法:
def p = new Person().first('Johnny').last('Depp').born(1963)
assert "$p.first $p.last" == 'Johnny Depp' 可以联合使用 SimpleStrategy 与 @Canonical。如果 @Builder 注释并没有显式的 includes 或 excludes 注释属性,而 @Canonical 注释却有这样的属性,那么 @Canonical 的这些属性将会重用于 @Builder。
该策略并不支持注释属性 builderClassName、buildMethodName、builderMethodName 和 forClass。
Groovy 已经有了内建的构建机制,如果内建机制不能满足你的要求,不要急于使用 @Builder。以下是一些范例:
def p2 = new Person(first: 'Keira', last: 'Knightley', born: 1985)
def p3 = new Person().with {
first = 'Geoffrey'
last = 'Rush'
born = 1951
}ExternalStrategy
为了使用 ExternalStrategy,使用 @Builder 创建并注释一个 Groovy 构建器类,使用 forClass 指定构建器所针对的类,指定使用 ExternalStrategy。假设构建器应用于下列类:
class Person {
String first
String last
int born
}需要显式地创建并使用构建器类:
import groovy.transform.builder.*
@Builder(builderStrategy=ExternalStrategy, forClass=Person)
class PersonBuilder { }
def p = new PersonBuilder().first('Johnny').last('Depp').born(1963).build()
assert "$p.first $p.last" == 'Johnny Depp' 注意,你所提供的构建器类(通常为空)就会被传入正确的 setter 及一个构建方法。生成的构建方法如下所示:
public Person build() {
Person _thePerson = new Person()
_thePerson.first = first
_thePerson.last = last
_thePerson.born = born
return _thePerson
}构建器所应用的类可以是任何 Java 或 Groovy 类,只要它们满足通常的 JavaBean 语法规范即可,比如一个无参构造函数和用于属性的 setter 方法。下面是一个使用 Java 类的例子:
import groovy.transform.builder.*
@Builder(builderStrategy=ExternalStrategy, forClass=javax.swing.DefaultButtonModel)
class ButtonModelBuilder {}
def model = new ButtonModelBuilder().enabled(true).pressed(true).armed(true).rollover(true).selected(true).build()
assert model.isArmed()
assert model.isPressed()
assert model.isEnabled()
assert model.isSelected()
assert model.isRollover() 使用 prefix、includes、excludes 及 buildMethodName 注释属性可以自定义生成的构建器。下面是一个自定义设置的例子:
import groovy.transform.builder.*
import groovy.transform.Canonical
@Canonical
class Person {
String first
String last
int born
}
@Builder(builderStrategy=ExternalStrategy, forClass=Person, includes=['first', 'last'], buildMethodName='create', prefix='with')
class PersonBuilder { }
def p = new PersonBuilder().withFirst('Johnny').withLast('Depp').create()
assert "$p.first $p.last" == 'Johnny Depp'用于 @Builder 的注释方法 builderMethodName 和 builderClassName 并不适用于该策略。
可以联合使用 ExternalStrategy 与 @Canonical。如果 @Builder 注释并没有显式的 includes 或 excludes 注释属性,而 @Canonical 注释却有这样的属性,那么 @Canonical 的这些属性将会重用于 @Builder。
DefaultStrategy
要想使用 DefaultStrategy,就必须使用注释 @Builder 来注释 Groovy 类:
import groovy.transform.builder.Builder
@Builder
class Person {
String firstName
String lastName
int age
}
def person = Person.builder().firstName("Robert").lastName("Lewandowski").age(21).build()
assert person.firstName == "Robert"
assert person.lastName == "Lewandowski"
assert person.age == 21
如果愿意,可以使用 builderClassName、buildMethodName、builderMethodName、prefix、includes 和 excludes注释属性来自定义构建过程的各个环节。下例展示了其中的一些用法:
import groovy.transform.builder.Builder
@Builder(buildMethodName='make', builderMethodName='maker', prefix='with', excludes='age')
class Person {
String firstName
String lastName
int age
}
def p = Person.maker().withFirstName("Robert").withLastName("Lewandowski").make()
assert "$p.firstName $p.lastName" == "Robert Lewandowski"
这种策略还支持注释静态方法及构造函数。在这种情况下,静态方法或构造函数会成为用于构建的属性,而对于静态方法的情况而言,方法的返回类型会成为将要构建的目标类。如果在类中(可以位于类、方法或者构造函数内)用到了多个 @Builder 注释,那么就要由你来保证辅助类和工厂方法的名称唯一性(也就是使用默认名称值的不能多于一个)。下例展示了方法与构造函数的用法(还展示如何为了保证名称唯一性而所需进行的重命名)。
import groovy.transform.builder.*
import groovy.transform.*
@ToString
@Builder
class Person {
String first, last
int born
Person(){}
@Builder(builderClassName='MovieBuilder', builderMethodName='byRoleBuilder')
Person(String roleName) {
if (roleName == 'Jack Sparrow') {
this.first = 'Johnny'; this.last = 'Depp'; this.born = 1963
}
}
@Builder(builderClassName='NameBuilder', builderMethodName='nameBuilder', prefix='having', buildMethodName='fullName')
static String join(String first, String last) {
first + ' ' + last
}
@Builder(builderClassName='SplitBuilder', builderMethodName='splitBuilder')
static Person split(String name, int year) {
def parts = name.split(' ')
new Person(first: parts[0], last: parts[1], born: year)
}
}
assert Person.splitBuilder().name("Johnny Depp").year(1963).build().toString() == 'Person(Johnny, Depp, 1963)'
assert Person.byRoleBuilder().roleName("Jack Sparrow").build().toString() == 'Person(Johnny, Depp, 1963)'
assert Person.nameBuilder().havingFirst('Johnny').havingLast('Depp').fullName() == 'Johnny Depp'
assert Person.builder().first("Johnny").last('Depp').born(1963).build().toString() == 'Person(Johnny, Depp, 1963)' 该策略并不支持 forClass 注释属性。
InitializerStrategy
要想使用 InitializerStrategy,需要使用 @Builder 注释你的 Groovy 类,然后指定策略,如下所示:
import groovy.transform.builder.*
import groovy.transform.*
@ToString
@Builder(builderStrategy=InitializerStrategy)
class Person {
String firstName
String lastName
int age
}
你的类可能会被锁定为包含一个配置有完整初始化器的公开构造函数。还包含一个用来创建初始化器的工厂方法。如下所示:
@CompileStatic
def firstLastAge() {
assert new Person(Person.createInitializer().firstName("John").lastName("Smith").age(21)).toString() == 'Person(John, Smith, 21)'
}
firstLastAge()
如果初始化器并不会涉及设置所有的属性(虽然次序并不重要),那么一旦使用初始化器,就会编译失败。如果不需要这么严格,就不需要使用 @CompileStatic。
可以联合使用 InitializerStrategy、@Canonical 与 @Immutable。如果 @Builder 注释并没有明显的 includes 或 excludes 注释属性但 @Canonical 注释却存在这样的属性,则 @Canonical 的这些属性就会被重用于 @Builder。下面就是使用 @Builder 和 @Immutable 的范例:
import groovy.transform.builder.*
import groovy.transform.*
@Builder(builderStrategy=InitializerStrategy)
@Immutable
class Person {
String first
String last
int born
}
@CompileStatic
def createFirstLastBorn() {
def p = new Person(Person.createInitializer().first('Johnny').last('Depp').born(1963))
assert "$p.first $p.last $p.born" == 'Johnny Depp 1963'
}
createFirstLastBorn()
这一策略也支持注释静态方法与构造函数。在本例中,静态方法或构造函数参数成为构建过程所需的属性。对于静态方法而言,方法的返回类型正是正在构建的目标类。如果在类中有多个 @Builder 注释(可能位于类、方法或构造函数多个位置),那么要确保生成的辅助类及工厂方法的名称都具有唯一性(默认名称值只能使用一次,不能被多次使用)。关于使用 DefaultStrategy 的方法与构造函数的相关用法范例,可参见该策略的文档。
该策略并不支持注释属性 forClass。
2.1.2 类设计注释
这一类别的注释主要用于简化一些知名模式(委托、单例,等等)的实现,采用的是一种声明式的风格。
@groovy.lang.Delegate
@Delegate AST 转换主要用于实现委托设计模式。以下列类为例:
class Event {
@Delegate Date when
String title
}利用 @Delegate 注释 when 字段,意味着 Event 类将把对 Date 方法的所有调用都委托给 when 字段。该例中,生成的代码如下所示:
class Event {
Date when
String title
boolean before(Date other) {
when.before(other)
}
// ...
}
然后就可以直接在 Event 类中调用before 方法了:
def ev = new Event(title:'Groovy keynote', when: Date.parse('yyyy/MM/dd', '2013/09/10'))
def now = new Date()
assert ev.before(now)@Delegate AST 转换行为可以通过下列参数来修改:
| 属性 | 默认值 | 描述 | 范例 |
interfaces | True | 由字段所实现的接口是否也能由类来实现 | interface Greeter { void sayHello() }
class MyGreeter implements Greeter { void sayHello() { println 'Hello!'} }
class DelegatingGreeter { // 没有明显的接口
@Delegate MyGreeter greeter = new MyGreeter()
}
def greeter = new DelegatingGreeter()
assert greeter instanceof Greeter // 显式地添加接口 |
deprecated | false | 如果为真,也会对由 @Deprecated注释的方法进行委托 | class WithDeprecation {
@Deprecated
void foo() {}
}
class WithoutDeprecation {
@Deprecated
void bar() {}
}
class Delegating {
@Delegate(deprecated=true) WithDeprecation with = new WithDeprecation()
@Delegate WithoutDeprecation without = new WithoutDeprecation()
}
def d = new Delegating()
d.foo() // 成功的原因在于 deprecated=true
d.bar() // 由于 @Deprecated 而失败 |
methodAnnotations | False | 是否要将受托类的方法的所有注释都留给请托类的方法 | class WithAnnotations {
@Transactional
void method() {
}
}
class DelegatingWithoutAnnotations {
@Delegate WithAnnotations delegate
}
class DelegatingWithAnnotations {
@Delegate(methodAnnotations = true) WithAnnotations delegate
}
def d1 = new DelegatingWithoutAnnotations()
def d2 = new DelegatingWithAnnotations()
assert d1.class.getDeclaredMethod('method').annotations.length==0
assert d2.class.getDeclaredMethod('method').annotations.length==1 |
parameterAnnotations | False | 是否将受托类方法参数的所有注释都留给请托方法 | class WithAnnotations {
void method(@NotNull String str) {
}
}
class DelegatingWithoutAnnotations {
@Delegate WithAnnotations delegate
}
class DelegatingWithAnnotations {
@Delegate(parameterAnnotations = true) WithAnnotations delegate
}
def d1 = new DelegatingWithoutAnnotations()
def d2 = new DelegatingWithAnnotations()
assert d1.class.getDeclaredMethod('method',String).parameterAnnotations[0].length==0
assert d2.class.getDeclaredMethod('method',String).parameterAnnotations[0].length==1 |
excludes | 空数组 | 一列要从委托中去除的方法。要想实现细粒度更高的操控,可以试试excludeTypes | class Worker {
void task1() {}
void task2() {}
}
class Delegating {
@Delegate(excludes=['task2']) Worker worker = new Worker()
}
def d = new Delegating()
d.task1() // 通过
d.task2() // 失败,因为方法被排除 |
includes | 空数组 | 包含在委托内的一列方法,要想实现细粒度更高的操控,可以试试includeTypes | class Worker {
void task1() {}
void task2() {}
}
class Delegating {
@Delegate(includes=['task1']) Worker worker = new Worker()
}
def d = new Delegating()
d.task1() // 通过
d.task2() // 失败,是因为方法未被包含 |
excludeTypes | 空数组 | 含有将要排除出委托外的方法签名的接口 | interface AppendStringSelector {
StringBuilder append(String str)
}
class UpperStringBuilder {
@Delegate(excludeTypes=AppendStringSelector)
StringBuilder sb1 = new StringBuilder()
@Delegate(includeTypes=AppendStringSelector)
StringBuilder sb2 = new StringBuilder()
String toString() { sb1.toString() + sb2.toString().toUpperCase() }
}
def usb = new UpperStringBuilder()
usb.append(3.5d)
usb.append('hello')
usb.append(true)
assert usb.toString() == '3.5trueHELLO' |
includeTypes | 空数组 | 含有将要被委托包含的方法签名的接口 | interface AppendBooleanSelector {
StringBuilder append(boolean b)
}
interface AppendFloatSelector {
StringBuilder append(float b)
}
class NumberBooleanBuilder {
@Delegate(includeTypes=AppendBooleanSelector, interfaces=false)
StringBuilder nums = new StringBuilder()
@Delegate(includeTypes=[AppendFloatSelector], interfaces=false)
StringBuilder bools = new StringBuilder()
String result() { "${nums.toString()} |
@groovy.transform.Immutable
@Immutable AST 转换简化了不可变类(类的成员被认为是不可变的)的创建工作。为了实现这样的目的,只需像下面这样注释类即可:
import groovy.transform.Immutable
@Immutable
class Point {
int x
int y
}
利用 @Immutable 注释生成的不可变类都是 final 类型的类。要想使类不可变,必须确保属性的类型是不可变(原始类型或装箱类型),或某种知名的不可变类型,或者是其他用 @Immutable 注释过的类。 @Immutable 施加于类上的效果与应用 @Canonical AST 转换非常相似,但却带有一种不可变类:自动生成的 toString、equals 与 hashCode 方法,而且在该例中如果修改属性就会抛出 ReadOnlyPropertyException 异常。
既然 @Immutable 依赖一组预定义的已知不可变类(比如 java.net.URI 或 java.lang.String),而且如果使用一种不再该组内的类型,就会导致失败,那么一定要了解下面这些参数。
| 属性 | 默认值 | 描述 | 范例 |
|---|---|---|---|
knownImmutableClasses | 空列表 | 被认为不可变的一列类 | import groovy.transform.Immutable
import groovy.transform.TupleConstructor
@TupleConstructor
final class Point {
final int x
final int y
public String toString() { "($x,$y)" }
}
@Immutable(knownImmutableClasses=[Point])
class Triangle {
Point a,b,c
} |
knownImmutables | 空列表 | 被认为不可变的一列属性名 | import groovy.transform.Immutable
import groovy.transform.TupleConstructor
@TupleConstructor
final class Point {
final int x
final int y
public String toString() { "($x,$y)" }
}
@Immutable(knownImmutables=['a','b','c'])
class Triangle {
Point a,b,c
} |
copyWith | false | 用来确定是否生成 copyWith( Map )方法的一个布尔值 | import groovy.transform.Immutable
@Immutable( copyWith=true )
class User {
String name
Integer age
}
def bob = new User( 'bob', 43 )
def alice = bob.copyWith( name:'alice' )
assert alice.name == 'alice'
assert alice.age == 43 |
@groovy.transform.Memoized
@Memoized AST 转换简化了缓存实现,只需通过 @Memoized 注释方法,就使方法调用结果能够得到缓存。考虑下面这个方法:
long longComputation(int seed) {
// 延缓计算
Thread.sleep(1000*seed)
System.nanoTime()
}该例基于方法的实际参数,模拟了一个大型计算。如果没有 @Memoized,每个方法调用就将占去几秒钟的时间,返回一个随机结果:
def x = longComputation(1)
def y = longComputation(1)
assert x!=y 添加 @Memoized 后,由于加入了缓存,根据以下参数,改变了方法的语义:
@Memoized
long longComputation(int seed) {
// 延缓计算
Thread.sleep(1000*seed)
System.nanoTime()
}
def x = longComputation(1) // 1 秒后返回结果
def y = longComputation(1) // 立刻返回结果
def z = longComputation(2) // 2 秒后返回结果
assert x==y
assert x!=z
缓存的大小可以通过 2 个可选参数来配置:
- protectedCacheSize 结果数目,这些结果不会被垃圾回收。
- maxCacheSize 存入内存中的最大结果数目。
默认情况下,缓存数目并没有限制,并且没有缓存结果能够避免被垃圾回收。protectedCacheSize>0 将会创建一个无限制的缓存,其中一些结果能够避免被回收。若设置 maxCacheSize>0,则将创建一个受限的缓存,无法避免被垃圾回收。将两个参数都进行设置,则可以创建一种受限而又受保护的缓存。
@groovy.lang.Singleton
@Singleton 注释用于在一个类中实现单例模式。默认时,使用类初始化会马上定义单例实例,或者会延迟(字段通过双重检查锁定来初始化):
@Singleton
class GreetingService {
String greeting(String name) { "Hello, $name!" }
}
assert GreetingService.instance.greeting('Bob') == 'Hello, Bob!'
默认时,当类被初始化时,就会马上创建单例,并可通过 instance 属性被访问。通过 property 参数还可以改变单例的名称:
@Singleton(property='theOne')
class GreetingService {
String greeting(String name) { "Hello, $name!" }
}
assert GreetingService.theOne.greeting('Bob') == 'Hello, Bob!' 另外,还可以使用 lazy 参数来延迟初始化:
class Collaborator {
public static boolean init = false
}
@Singleton(lazy=true,strict=false)
class GreetingService {
static void init() {}
GreetingService() {
Collaborator.init = true
}
String greeting(String name) { "Hello, $name!" }
}
GreetingService.init() // 确保类被初始化
assert Collaborator.init == false
GreetingService.instance
assert Collaborator.init == true
assert GreetingService.instance.greeting('Bob') == 'Hello, Bob!'
在该例中,将 strict 参数设置为 false,从而能够定义我们自己的构造函数。
@groovy.transform.Mixin
废弃使用。可以考虑使用特性。
2.1.3 日志改进
Groovy 提供的 AST 转换可以帮助集成那些广泛使用的日志框架。值得一提的是,利用这些注释来注释类,并不会妨碍在类路径上添加合适的日志框架。
所有的转换的工作方式都差不多:
- 添加与日志记录器相关的静态 final
log字段。 - 根据底层框架,将所有的对
log.level()的调用封装为正确的log.isLevelEnabled防护(guard)。
这些转换支持两种参数:
- 与日志记录器字段名称相关的
value(默认为log)。 - 表示日志记录器类别名称的
category(默认为类名)。
@groovy.util.logging.Log
首先要介绍的日志 AST 转换是 @Log 注释,依赖的是 JDK 日志框架:
@groovy.util.logging.Log
class Greeter {
void greet() {
log.info 'Called greeter'
println 'Hello, world!'
}
}
上面这样写与下面这样写是等同的:
import java.util.logging.Level
import java.util.logging.Logger
class Greeter {
private static final Logger log = Logger.getLogger(Greeter.name)
void greet() {
if (log.isLoggable(Level.INFO)) {
log.info 'Called greeter'
}
println 'Hello, world!'
}
}
@groovy.util.logging.Commons
Groovy 支持 Apache Commons Logging 框架,用到了 @Commons 注释。
@groovy.util.logging.Commons
class Greeter {
void greet() {
log.debug 'Called greeter'
println 'Hello, world!'
}
} 上面这样写与下面这样写是等同的:
import org.apache.commons.logging.LogFactory
import org.apache.commons.logging.Log
class Greeter {
private static final Log log = LogFactory.getLog(Greeter)
void greet() {
if (log.isDebugEnabled()) {
log.debug 'Called greeter'
}
println 'Hello, world!'
}
}@groovy.util.logging.Log4j
Groovy 还支持 Apache Log4j 1.x 框架,使用的是 @Log4j 注释:
@groovy.util.logging.Log4j
class Greeter {
void greet() {
log.debug 'Called greeter'
println 'Hello, world!'
}
}
上面这样写与下面这样写是等同的:
import org.apache.log4j.Logger
class Greeter {
private static final Logger log = Logger.getLogger(Greeter)
void greet() {
if (log.isDebugEnabled()) {
log.debug 'Called greeter'
}
println 'Hello, world!'
}
}
@groovy.util.logging.Log4j2
Groovy 还支持 Apache Log4j 2.x 框架,用的是 @Log4j2 注释:
@groovy.util.logging.Log4j2
class Greeter {
void greet() {
log.debug 'Called greeter'
println 'Hello, world!'
}
}
上面这样写与下面这样写是等同的:
import org.apache.logging.log4j.LogManager
import org.apache.logging.log4j.Logger
class Greeter {
private static final Logger log = LogManager.getLogger(Greeter)
void greet() {
if (log.isDebugEnabled()) {
log.debug 'Called greeter'
}
println 'Hello, world!'
}
} @groovy.util.logging.Slf4j
Groovy 支持 Simple Logging Facade for Java (SLF4J) 框架,使用 @Slf4j 注释:
@groovy.util.logging.Slf4j
class Greeter {
void greet() {
log.debug 'Called greeter'
println 'Hello, world!'
}
} 上面这样写与下面这样写是等同的:
import org.slf4j.LoggerFactory
import org.slf4j.Logger
class Greeter {
private static final Logger log = LoggerFactory.getLogger(Greeter)
void greet() {
if (log.isDebugEnabled()) {
log.debug 'Called greeter'
}
println 'Hello, world!'
}
} 2.1.4 声明式并发
Groovy 提供一系列注释,以声明式的方式来简化常见的并发模式。
@groovy.transform.Synchronized
@Synchronized AST 转换与 synchronized 关键字运作方式相似,但为了更安全的并发,更关注不同对象。它可以用于任何方法或静态方法:
import groovy.transform.Synchronized
import java.util.concurrent.Executors
import java.util.concurrent.TimeUnit
class Counter {
int cpt
@Synchronized
int incrementAndGet() {
cpt++
}
int get() {
cpt
}
}上面这种写法等于创建一个锁定对象,然后将整个方法封装进一个同步块:
class Counter {
int cpt
private final Object $lock = new Object()
int incrementAndGet() {
synchronized($lock) {
cpt++
}
}
int get() {
cpt
}
}@Synchronized 默认创建一个名为 $lock(对于静态方法而言是 $LOCK),但是通过指定值属性,可以使用任何想用的字段,如下所示:
import groovy.transform.Synchronized
import java.util.concurrent.Executors
import java.util.concurrent.TimeUnit
class Counter {
int cpt
private final Object myLock = new Object()
@Synchronized('myLock')
int incrementAndGet() {
cpt++
}
int get() {
cpt
}
}@groovy.transform.WithReadLock and @groovy.transform.WithWriteLock
@WithReadLock AST 转换一般与 @WithWriteLock 转换协同使用,利用 JDK 提供的 ReentrantReadWriteLock 实现读/写同步功能。可以为方法或静态方法添加注释。显式创建一个 final 类型的 $reentrantLock 字段(对于静态方法来说是$REENTRANTLOCK)并且添加正确的同步代码。范例如下所示:
import groovy.transform.WithReadLock
import groovy.transform.WithWriteLock
class Counters {
public final Map<String,Integer> map = [:].withDefault { 0 }
@WithReadLock
int get(String id) {
map.get(id)
}
@WithWriteLock
void add(String id, int num) {
Thread.sleep(200) // emulate long computation
map.put(id, map.get(id)+num)
}
}
上面写法等同于下面这样:
import groovy.transform.WithReadLock as WithReadLock
import groovy.transform.WithWriteLock as WithWriteLock
public class Counters {
private final Map<String, Integer> map
private final java.util.concurrent.locks.ReentrantReadWriteLock $reentrantlock
public int get(java.lang.String id) {
$reentrantlock.readLock().lock()
try {
map.get(id)
}
finally {
$reentrantlock.readLock().unlock()
}
}
public void add(java.lang.String id, int num) {
$reentrantlock.writeLock().lock()
try {
java.lang.Thread.sleep(200)
map.put(id, map.get(id) + num )
}
finally {
$reentrantlock.writeLock().unlock()
}
}
}
@WithReadLock 和 @WithWriteLock 都支持指定一种替代性的锁定对象。在那种情况下,用户必须声明引用的字段,如下所示:
import groovy.transform.WithReadLock
import groovy.transform.WithWriteLock
import java.util.concurrent.locks.ReentrantReadWriteLock
class Counters {
public final Map<String,Integer> map = [:].withDefault { 0 }
private final ReentrantReadWriteLock customLock = new ReentrantReadWriteLock()
@WithReadLock('customLock')
int get(String id) {
map.get(id)
}
@WithWriteLock('customLock')
void add(String id, int num) {
Thread.sleep(200) // emulate long computation
map.put(id, map.get(id)+num)
}
}
详情查看:
- groovy.transform.WithReadLock 的 Javadoc 文档。
- groovy.transform.WithWriteLock 的 Javadoc 文档。
2.1.5 更简便的克隆(cloning)与具体化(externalizing)
Groovy 提供了两种注释来改善 Clonable 和 Externalizable 接口的实现,分别是 @AutoClone 和 @AutoExternalize。
@groovy.transform.AutoClone
@AutoClone 注释着重使用多种策略来实现 @java.lang.Cloneable 接口,其中 style 参数发挥了极大的作用:
- 默认的
AutoCloneStyle.CLONE策略,在每个可克隆的属性上,首先调用super.clone()然后是clone()。 AutoCloneStyle.SIMPLE策略使用正则构造函数,将源对象的属性调用并复制到克隆对象上。AutoCloneStyle.COPY_CONSTRUCTOR策略创建并使用一个复制构造函数。AutoCloneStyle.SERIALIZATION策略使用序列化(或具体化)来克隆对象。
关于每个策略的优缺点的论述可参考相关 Javadoc 文档:groovy.transform.AutoClone 和 groovy.transform.AutoCloneStyle。
下面是一个范例:
import groovy.transform.AutoClone
@AutoClone
class Book {
String isbn
String title
List<String> authors
Date publicationDate
}
它等同于下面这种写法:
class Book implements Cloneable {
String isbn
String title
List<String> authors
Date publicationDate
public Book clone() throws CloneNotSupportedException {
Book result = super.clone()
result.authors = authors instanceof Cloneable ? (List) authors.clone() : authors
result.publicationDate = publicationDate.clone()
result
}
}
注意字符串属性都没有被显式地处理,这时因为字符串是不可变的,而且 Object 的 clone() 方法会复制字符串的引用。同样也适用于原始字段以及 java.lang.Number 绝大多数的具体子类。
除了克隆方式,@AutoClone 还支持多种选项:
| 属性 | 默认值 | 描述 | 范例 |
|---|---|---|---|
excludes | 空列表 | 需要从克隆中排除的一列属性或字段名称。也允许使用包含由逗号分隔的字段/属性名的字符串。详情参看groovy.transform.AutoClone#excludes。 | import groovy.transform.AutoClone
import groovy.transform.AutoCloneStyle
@AutoClone(style=AutoCloneStyle.SIMPLE,excludes='authors')
class Book {
String isbn
String title
List authors
Date publicationDate
} |
includeFields | false | 默认只克隆属性。该表示为 true 时,也能克隆字段。 | import groovy.transform.AutoClone
import groovy.transform.AutoCloneStyle
@AutoClone(style=AutoCloneStyle.SIMPLE,includeFields=true)
class Book {
String isbn
String title
List authors
protected Date publicationDate
} |
@groovy.transform.AutoExternalize
@AutoExternalize AST 转换可帮助创建 java.io.Externalizable 类。自动为类添加接口,生成 writeExternal and readExternal 方法。比如下面这个范例:
import groovy.transform.AutoExternalize
@AutoExternalize
class Book {
String isbn
String title
float price
}可以转换为:
class Book implements java.io.Externalizable {
String isbn
String title
float price
void writeExternal(ObjectOutput out) throws IOException {
out.writeObject(isbn)
out.writeObject(title)
out.writeFloat( price )
}
public void readExternal(ObjectInput oin) {
isbn = (String) oin.readObject()
title = (String) oin.readObject()
price = oin.readFloat()
}
}@AutoExternalize 注释支持的两个参数能使我们稍微对它的行为进行自定义:
| 属性 | 默认值 | 描述 | 范例 |
|---|---|---|---|
excludes | 空列表 | 需要从具体化过程中排除的一列属性或字段名称。也允许使用包含由逗号分隔的字段/属性名的字符串。详情参看 groovy.transform.AutoExternalize#excludes。 | import groovy.transform.AutoExternalize
@AutoExternalize(excludes='price')
class Book {
String isbn
String title
float price
} |
includeFields | false | 默认只具体化属性。该表示为 true 时,也能克隆字段。 | import groovy.transform.AutoExternalize
@AutoExternalize(includeFields=true)
class Book {
String isbn
String title
protected float price
} |
2.1.6 更安全的脚本
利用 Groovy,在运行时可以更容易地执行用户的脚本(比如使用 groovy.lang.GroovyShell),但我们如何判定脚本不会耗光所有的 CPU 资源(无限循环)或者并发脚本不会逐渐消耗光线程池中的所有可用线程呢?为了打造更安全的脚本,Groovy 提供了几个注释,它们有多种功能,比如可以自动中断执行。
@groovy.transform.ThreadInterrupt
JVM 中经常遇到一种复杂情况:线程无法停止。虽然有一个 Thread#stop 方法,但它已经是不建议采用或者说弃用的(不可靠),所以唯一的机会就在于使用 Thread#interrupt。调用这个方法会在线程中设置 interrupt 标记,但却不会停止线程。这就会造成麻烦:需要由线程中执行的代码负责检查该标记并正确退出。只有当开发者确切地知道执行的代码要在一个独立的线程中执行,这才有意义,但一般来说开发者无从得知。更糟糕的是,用户的脚本甚至不知道用于执行代码的线程是哪一个(想想 DSL)。
@ThreadInterrupt 注释简化了这些操作,在下面这些关键结构中添加了线程中断检查:
- 循环结构(for、while)。
- 方法的首指令。
- 闭包体的首指令。
比如下面这个用户脚本:
while (true) {
i++
}
显然这是一个无限循环。如果这段代码在自己的线程中执行,中断就没有任何意义:如果在线程上使用 join,调用代码还能继续运行,但线程依然是活跃的,在后台运行,你根本没法终止它,慢慢地就会把资源用尽。
设置自己的 shell 是一种解决方法:
def config = new CompilerConfiguration()
config.addCompilationCustomizers(
new ASTTransformationCustomizer(ThreadInterrupt)
)
def binding = new Binding(i:0)
def shell = new GroovyShell(binding,config)
配置该 shell ,自动在所有脚本上使用 @ThreadInterrupt AST 转换。然后就可以这样执行用户脚本了:
def t = Thread.start {
shell.evaluate(userCode)
}
t.join(500) // 用来使脚本结束的时间最多不超过 500 毫秒
if (t.alive) {
t.interrupt()
}
转换会自动修改用户代码:
while (true) {
if (Thread.currentThread().interrupted) {
throw new InterruptedException('The current thread has been interrupted.')
}
i++
}
循环中引入的检查可以保证如果 interrupt 标记设置在当前线程中,就会抛出一个异常,打断线程执行。
@ThreadInterrupt 支持多种选项,能够进一步自定义转换的行为:
| 属性 | 默认值 | 描述 | 范例 |
|---|---|---|---|
thrown | java.lang.InterruptedException | 指定线程中断时应抛出的异常的类型 | class BadException extends Exception {
BadException(String message) { super(message) }
}
def config = new CompilerConfiguration()
config.addCompilationCustomizers(
new ASTTransformationCustomizer(thrown:BadException, ThreadInterrupt)
)
def binding = new Binding(i:0)
def shell = new GroovyShell(this.class.classLoader,binding,config)
def userCode = """
try {
while (true) {
i++
}
} catch (BadException e) {
i = -1
}
"""
def t = Thread.start {
shell.evaluate(userCode)
}
t.join(1000) // 结束脚本的时间最多为 1 秒
assert binding.i > 0
if (t.alive) {
t.interrupt()
}
Thread.sleep(500)
assert binding.i == -1''' |
checkOnMethodStart | true | 每个方法体开始处是否插入中断检查。详情参看:groovy.transform.ThreadInterrupt | @ThreadInterrupt(checkOnMethodStart=false) |
applyToAllClasses | true | 同一源单位(在同一源文件中)的所有类是否该应用这个转换。详情参看:groovy.transform.ThreadInterrupt | @ThreadInterrupt(applyToAllClasses=false)
class A { ... } // 添加的中断检查
class B { ... } // 没有中断检查 |
applyToAllMembers | true | 类的所有成员是否该应用同一转换。详情参见:groovy.transform.ThreadInterrupt | class A {
@ThreadInterrupt(applyToAllMembers=false)
void method1() { ... } // 添加的中断检查
void method2() { ... } // 没有中断检查
} |
@groovy.transform.TimedInterrupt
@TimedInterrupt AST 转换所要解决的问题与 @groovy.transform.ThreadInterrupt 稍微有所不同:不是检查线程的 interrupt 标记,而是当线程运行时间过长时,会自动抛出异常。
该注释并不产生监控线程。它的工作方式类似于 @ThreadInterrupt:在代码中合适的位置处放置检查。这意味着如果出现 I/O 导致的线程阻塞,线程就不会被中断。
考虑下面这样的代码:
def fib(int n) { n<2?n:fib(n-1)+fib(n-2) }
result = fib(600)
这种斐波那契数列计算的实现还远远称不上完美。如果以较高的 n 值调用,所需的响应时间就会长达几分钟。利用 @TimedInterrupt,你可以选择允许脚本运行的时间。下面的设置代码使用户代码最多只能运行 1 秒钟:
def config = new CompilerConfiguration()
config.addCompilationCustomizers(
new ASTTransformationCustomizer(value:1, TimedInterrupt)
)
def binding = new Binding(result:0)
def shell = new GroovyShell(this.class.classLoader, binding,config)
上面的代码相当于利用 @TimedInterrupt 来注释类:
@TimedInterrupt(value=1, unit=TimeUnit.SECONDS)
class MyClass {
def fib(int n) {
n<2?n:fib(n-1)+fib(n-2)
}
}
该转换的行为可以通过 @TimedInterrupt 的几个选项来进行自定义:
| 属性 | 默认值 | 描述 | 范例 |
|---|---|---|---|
value | Long.MAX_VALUE | 与 unit 一起使用,用来指定执行超时时间。 | @TimedInterrupt(value=500L, unit= TimeUnit.MILLISECONDS, applyToAllClasses = false)
class Slow {
def fib(n) { n |
unit | 与 value 一起使用,用来指定执行超时时间。 | @TimedInterrupt(value=500L, unit= TimeUnit.MILLISECONDS, applyToAllClasses = false)
class Slow {
def fib(n) { n | |
thrown | java.util.concurrent.TimeoutException | 指定如果超时后抛出的异常类型。 | @TimedInterrupt(thrown=TooLongException, applyToAllClasses = false, value=1L)
class Slow {
def fib(n) { Thread.sleep(100); n |
checkOnMethodStart | true | 中断检查是否应该在每个方法体开始处插入。详情参见:groovy.transform.TimedInterrupt。 | @TimedInterrupt(checkOnMethodStart=false) |
applyToAllClasses | true | 同源单位内的所有类是否应该使用同一转换。详情参见:groovy.transform.TimedInterrupt。 | @TimedInterrupt(applyToAllClasses=false)
class A { ... } // 添加中断检查
class B { ... } // 无中断检查 |
applyToAllMembers | true | 转换是否应该应用于类的所有成员。详情参见:groovy.transform.TimedInterrupt | class A {
@TimedInterrupt(applyToAllMembers=false)
void method1() { ... } // 添加中断检查
void method2() { ... } // 无中断检查
} |
注意:@TimedInterrupt 目前并不兼容静态方法!
@groovy.transform.ConditionalInterrupt
为了创建更安全的脚本,最后还有介绍一个基本注释,使用自定义策略中断脚本时会用到它,尤其是在使用资源管理(限制对 API 的调用次数)时,更是应该使用该注释。在下例中,虽然用户代码使用的是无限循环,但 @ConditionalInterrupt 还是能允许我们检查配额管理并自动打断脚本。
@ConditionalInterrupt({Quotas.disallow('user')})
class UserCode {
void doSomething() {
int i=0
while (true) {
println "Consuming resources ${++i}"
}
}
}
下面这个配额检查非常简单,但可以采用更复杂的逻辑来实现:
class Quotas {
static def quotas = [:].withDefault { 10 }
static boolean disallow(String userName) {
println "Checking quota for $userName"
(quotas[userName]--)<0
}
}
确保 @ConditionalInterrupt 能够正常运作于下面的代码:
assert Quotas.quotas['user'] == 10
def t = Thread.start {
new UserCode().doSomething()
}
t.join(5000)
assert !t.alive
assert Quotas.quotas['user'] < 0
当然,在实际运用中,@ConditionalInterrupt 不太可能自动添加到用户代码中。它的注入方式类似于ThreadInterrupt一节中范例所采用的那种方式,使用 org.codehaus.groovy.control.customizers.ASTTransformationCustomizer:
def config = new CompilerConfiguration()
def checkExpression = new ClosureExpression(
Parameter.EMPTY_ARRAY,
new ExpressionStatement(
new MethodCallExpression(new ClassExpression(ClassHelper.make(Quotas)), 'disallow', new ConstantExpression('user'))
)
)
config.addCompilationCustomizers(
new ASTTransformationCustomizer(value: checkExpression, ConditionalInterrupt)
)
def shell = new GroovyShell(this.class.classLoader,new Binding(),config)
def userCode = """
int i=0
while (true) {
println "Consuming resources \\${++i}"
}
"""
assert Quotas.quotas['user'] == 10
def t = Thread.start {
shell.evaluate(userCode)
}
t.join(5000)
assert !t.alive
assert Quotas.quotas['user'] < 0
@ConditionalInterrupt 支持的多种选项可以使我们深入自定义该转换的行为:
| 属性 | 默认值 | 描述 | 范例 |
|---|---|---|---|
value | --- | 调用的闭包会检查是否允许执行。如果闭包返回 false,允许执行,否则抛出异常。 | @ConditionalInterrupt({ ... }) |
thrown | java.lang.InterruptedException | 如果执行应被终止,指定抛出的异常类型。 | config.addCompilationCustomizers(
new ASTTransformationCustomizer(thrown: QuotaExceededException,value: checkExpression, ConditionalInterrupt)
)
assert Quotas.quotas['user'] == 10
def t = Thread.start {
try {
shell.evaluate(userCode)
} catch (QuotaExceededException) {
Quotas.quotas['user'] = 'Quota exceeded'
}
}
t.join(5000)
assert !t.alive
assert Quotas.quotas['user'] == 'Quota exceeded' |
checkOnMethodStart | true | 中断检查是否应该在每个方法体开始处插入。详情参见:groovy.transform.ConditionalInterrupt。 | @ConditionalInterrupt(checkOnMethodStart=false) |
applyToAllClasses | true | 同源单位内(位于同一源文件)的所有类是否应该使用同一转换。详情参见:groovy.transform.ConditionalInterrupt。 | @ConditionalInterrupt(applyToAllClasses=false)
class A { ... } // 添加中断检查
class B { ... } // 无中断检查 |
applyToAllMembers | true | 转换是否应该应用于类的所有成员。详情参见:groovy.transform.ConditionalInterrupt | class A {
@ConditionalInterrupt(applyToAllMembers=false)
void method1() { ... } // 添加中断检查
void method2() { ... } // 没有中断检查
} |
2.1.7 编译器指令
这一类 AST 转换所包含的注释主要对代码语义进行直接影响,而不是用于代码生成。因此,它们似乎更应被视为能够在编译时或运行时改变程序行为的编译器指令。
@groovy.transform.Field
@Field 注释只适用于脚本,目的在于解决脚本中的常见范围错误。比如下面的范例在运行时就会出错:
def x
String line() {
"="*x
}
x=3
assert "===" == line()
x=5
assert "=====" == line() 这里抛出的错误可能难以解释:groovy.lang.MissingPropertyException: No such property: x。其中的原因可能在于:脚本被编译为类,脚本体本身被编译为一个 run() 方法。脚本中定义的方法是独立的,所以上面的代码等同于:
class MyScript extends Script {
String line() {
"="*x
}
public def run() {
def x
x=3
assert "===" == line()
x=5
assert "=====" == line()
}
}
因此 def x 实际上被解析为一个本地变量,超出了 line 方法的作用范围。通过将变量的作用范围改为闭合脚本的字段,@Field AST 转换可以修复这个问题。
@Field def x
String line() {
"="*x
}
x=3
assert "===" == line()
x=5
assert "=====" == line()
最后等同的结果代码就会变成这样:
class MyScript extends Script {
def x
String line() {
"="*x
}
public def run() {
x=3
assert "===" == line()
x=5
assert "=====" == line()
}
}
@groovy.transform.PackageScope
Groovy 可见性规则默认规定,如果没有为创建的字段指定修饰符,那么该字段就会被解释为属性(property):
class Person {
String name // 这是一个属性
}如果你想创建一个包私有字段,而不是属性(私有字段+ getter/setter),那么利用 @PackageScope 来注释字段:
class Person {
@PackageScope String name // not a property anymore
}@PackageScope 注释也可以用于类、方法及构造函数。另外,假如在类级别上将一列 PackageScopeTarget 值指定为注释属性,那么对于该类中所有无明确修饰符并且匹配所提供的 PackageScopeTarget 的成员而言,它们依旧属于包保护类型。下例中对类中的一些字段应用一些注释:
import static groovy.transform.PackageScopeTarget.FIELDS
@PackageScope(FIELDS)
class Person {
String name // 不是属性,包保护
Date dob // 不是属性,包保护
private int age // 明确修饰符,所以不会被修改
}@PackageScope 注释几乎不属于 Groovy 的通常规范,但在有些情况下它也非常有用:需要在包内保持可见的工厂方法,或用于测试的方法或构造函数,再或者与需要这样的可见性规范的第三方库进行集成时。
@groovy.transform.AnnotationCollector
@AnnotationCollector 允许创建元注释(meta-annotation),这个概念曾在专有小节 中介绍过。
@groovy.transform.TypeChecked
@TypeChecked 能够启用 Groovy 代码上的编译时类型检查,详情参见:类型检查小节。
@groovy.transform.CompileStatic
@CompileStatic 能够启用 Groovy 代码上的静态编译。详情参见:类型检查小节。
@groovy.transform.CompileDynamic
@CompileDynamic 能够禁止在部分 Groovy 代码上的编译。详情参见:类型检查小节。
@groovy.lang.DelegatesTo
从技术角度上说,@DelegatesTo 并不属于 AST 转换。它着重于为代码建立文档,并且当你使用类型检查或静态编译时帮助编译器。该注释的详细说明参见本文档的 DSL 部分。
2.1.8 Swing 模式
@groovy.beans.Bindable
@Bindable 是一种能够将正则属性转换为绑定属性(根据 JavaBean 规范)的 AST 转换。@Bindable 注释可以放在属性或类上。假如想把类中的所有属性都转换为绑定属性,则可以像下例这样来注释类:
import groovy.beans.Bindable
@Bindable
class Person {
String name
int age
}它其实等同于:
import java.beans.PropertyChangeListener
import java.beans.PropertyChangeSupport
class Person {
final private PropertyChangeSupport this$propertyChangeSupport
String name
int age
public void addPropertyChangeListener(PropertyChangeListener listener) {
this$propertyChangeSupport.addPropertyChangeListener(listener)
}
public void addPropertyChangeListener(String name, PropertyChangeListener listener) {
this$propertyChangeSupport.addPropertyChangeListener(name, listener)
}
public void removePropertyChangeListener(PropertyChangeListener listener) {
this$propertyChangeSupport.removePropertyChangeListener(listener)
}
public void removePropertyChangeListener(String name, PropertyChangeListener listener) {
this$propertyChangeSupport.removePropertyChangeListener(name, listener)
}
public void firePropertyChange(String name, Object oldValue, Object newValue) {
this$propertyChangeSupport.firePropertyChange(name, oldValue, newValue)
}
public PropertyChangeListener[] getPropertyChangeListeners() {
return this$propertyChangeSupport.getPropertyChangeListeners()
}
public PropertyChangeListener[] getPropertyChangeListeners(String name) {
return this$propertyChangeSupport.getPropertyChangeListeners(name)
}
} 然而,@Bindable 会去掉类中的很多样本文件,极大提高可读性。如果注释放在一个属性上,那么只有这个属性才是绑定的:
import groovy.beans.Bindable
class Person {
String name
@Bindable int age
}@groovy.beans.ListenerList
@ListenerList AST 转换生成的代码用于添加、去除与获取与某类相关的一列侦听器,只需注释一个集合属性:
import java.awt.event.ActionListener
import groovy.beans.ListenerList
class Component {
@ListenerList
List<ActionListener> listeners;
}该转换会根据列表的基本属性,生成适当的添加/去除方法。另外,它还根据在该类中声明的公开方法,创建 fireXXX 方法。
import java.awt.event.ActionEvent
import java.awt.event.ActionListener as ActionListener
import groovy.beans.ListenerList as ListenerList
public class Component {
@ListenerList
private List<ActionListener> listeners
public void addActionListener(ActionListener listener) {
if ( listener == null) {
return
}
if ( listeners == null) {
listeners = []
}
listeners.add(listener)
}
public void removeActionListener(ActionListener listener) {
if ( listener == null) {
return
}
if ( listeners == null) {
listeners = []
}
listeners.remove(listener)
}
public ActionListener[] getActionListeners() {
Object __result = []
if ( listeners != null) {
__result.addAll(listeners)
}
return (( __result ) as ActionListener[])
}
public void fireActionPerformed(ActionEvent param0) {
if ( listeners != null) {
ArrayList<ActionListener> __list = new ArrayList<ActionListener>(listeners)
for (def listener : __list ) {
listener.actionPerformed(param0)
}
}
}
} 通过几个选项,可以进一步定制 @Bindable 的行为:
| 属性 | 默认值 | 描述 | 范例 |
|---|---|---|---|
name | 基本类型名称 | 默认,添加到添加/删除等方法中的后缀是列表基本类型的简单类名。 | class Component {
@ListenerList(name='item')
List listeners;
} |
synchronize | false | 如果设为 true,生成的方法将会同步 | class Component {
@ListenerList(synchronize = true)
List listeners;
} |
@groovy.beans.Vetoable
@Vetoable 注释的运作方式与 @Bindable 很像,根据 JavaBean 规范生成限制属性,而不是绑定属性。它可以放在属性上,也可以放在类上,放在类上时意味着所有属性就都转变成了受限属性。下例中,利用 @Vetoable 注释一个类:
import groovy.beans.Vetoable
import java.beans.PropertyVetoException
import java.beans.VetoableChangeListener
@Vetoable
class Person {
String name
int age
}
这等同于:
public class Person {
private String name
private int age
final private java.beans.VetoableChangeSupport this$vetoableChangeSupport
public void addVetoableChangeListener(VetoableChangeListener listener) {
this$vetoableChangeSupport.addVetoableChangeListener(listener)
}
public void addVetoableChangeListener(String name, VetoableChangeListener listener) {
this$vetoableChangeSupport.addVetoableChangeListener(name, listener)
}
public void removeVetoableChangeListener(VetoableChangeListener listener) {
this$vetoableChangeSupport.removeVetoableChangeListener(listener)
}
public void removeVetoableChangeListener(String name, VetoableChangeListener listener) {
this$vetoableChangeSupport.removeVetoableChangeListener(name, listener)
}
public void fireVetoableChange(String name, Object oldValue, Object newValue) throws PropertyVetoException {
this$vetoableChangeSupport.fireVetoableChange(name, oldValue, newValue)
}
public VetoableChangeListener[] getVetoableChangeListeners() {
return this$vetoableChangeSupport.getVetoableChangeListeners()
}
public VetoableChangeListener[] getVetoableChangeListeners(String name) {
return this$vetoableChangeSupport.getVetoableChangeListeners(name)
}
public void setName(String value) throws PropertyVetoException {
this.fireVetoableChange('name', name, value)
name = value
}
public void setAge(int value) throws PropertyVetoException {
this.fireVetoableChange('age', age, value)
age = value
}
}
如果该注释被加于一个属性上,那么只有该属性受限。
import groovy.beans.Vetoable
class Person {
String name
@Vetoable int age
}
2.1.9 测试辅助
@groovy.lang.NotYetImplemented
@NotYetImplemented 用于转换 JUnit 3/4 测试用例的结果。该注释非常适用于这样的情况:如果某个功能还未实现,但测试中实现了。在这种情况下,期望测试也会失败。@NotYetImplemented 注释可反转测试结果,如下例所示:
import groovy.transform.NotYetImplemented
class Maths {
static int fib(int n) {
// 稍后实现的逻辑
}
}
class MathsTest extends GroovyTestCase {
@NotYetImplemented
void testFib() {
def dataTable = [
1:1,
2:1,
3:2,
4:3,
5:5,
6:8,
7:13
]
dataTable.each { i, r ->
assert Maths.fib(i) == r
}
}
}
使用该技术的另一优点是,可以在明白如何 bug 之前,为这些 bug 编写测试用例。假如未来某一时刻,某个代码改动意外地修补这个 Bug,你就会得到通知,因为原本希望测试是不能通过的。
@groovy.transform.ASTTest
@ASTTest 是一种比较特殊的 AST 转换,它能帮助调试其他的 AST 转换或 Groovy 编译器本身。有了它,开发者能够在编译时仔细研究 AST,在 AST 上执行断言,而不是在编译结果上。这意味着这一 AST 信息能使我们在执行字节码之前就访问 AST。@ASTTest 可以放置在任意可注释的节点上,它需要两个参数:
- phase:设置在能够触发
@ASTTest的阶段。测试代码将在该阶段的末尾在 AST 树上运行。 - value:当可注释节点一旦到达相应阶段就执行的代码。
编译阶段只能从 org.codehaus.groovy.control.CompilePhase 中选择。但是,因为不可能用同一注释对一个节点注释两次,所以你不能对两个不同编译阶段的同一节点使用 @ASTTest。
value 是一个能够访问已注释节点的特殊变量 node 的闭包表达式。辅助 lookup 方法详细说明见下文。比如,我们可以像下面这样注释类节点:
import groovy.transform.ASTTest
import org.codehaus.groovy.ast.ClassNode
import static org.codehaus.groovy.control.CompilePhase.*
@ASTTest(phase=CONVERSION, value={ 1⃣️
assert node instanceof ClassNode 2⃣️
assert node.name == 'Person' 3⃣️
})
class Person {
}1⃣️ 检查在 CONVERSION 阶段后的抽象语法树的状态。
2⃣️ 节点引用了由 @ASTTest 注释的 AST 节点。
3⃣️ 可以用于在编译时执行断言。
@ASTTest 有趣的一个功能是,假如断言失败,则编译也失败。假设要在编译时检查一个 AST 转换的行为。这里就可以使用 @PackageScope。假如想验证 @PackageScope 注释的属性成为一个包私有字段。为了达到这个目的,就需要知道转换是在哪个阶段进行的,可以在这里找到:org.codehaus.groovy.transform.PackageScopeASTTransformation:语义分析。所以可以用下面这样的代码来写测试:
import groovy.transform.ASTTest
import groovy.transform.PackageScope
import static org.codehaus.groovy.control.CompilePhase.*
@ASTTest(phase=SEMANTIC_ANALYSIS, value= {
def nameNode = node.properties.find { it.name == 'name' }
def ageNode = node.properties.find { it.name == 'age' }
assert nameNode
assert ageNode == null // 再也不应该是一个属性了
def ageField = node.getDeclaredField 'age'
assert ageField.modifiers == 0
})
class Person {
String name
@PackageScope int age
}@ASTTest 注释可以放在语法所容许的任何地方。有时你可以需要测试不可注释的 AST 节点的内容。这时 @ASTTest 会提供一个便利的 lookup 方法,用来为用特殊令牌标记的节点搜索 AST:
def list = lookup('anchor') 1⃣️
Statement stmt = list[0] 2⃣️ 1⃣️ 返回包含标签是 anchor 的 AST 节点的列表。 2⃣️ 通常有必要选择处理的元素,因为 lookup 经常会返回一个列表。
假设需要测试一个 for 循环变量的声明类型,可以这样做:
import groovy.transform.ASTTest
import groovy.transform.PackageScope
import org.codehaus.groovy.ast.ClassHelper
import org.codehaus.groovy.ast.expr.DeclarationExpression
import org.codehaus.groovy.ast.stmt.ForStatement
import static org.codehaus.groovy.control.CompilePhase.*
class Something {
@ASTTest(phase=SEMANTIC_ANALYSIS, value= {
def forLoop = lookup('anchor')[0]
assert forLoop instanceof ForStatement
def decl = forLoop.collectionExpression.expressions[0]
assert decl instanceof DeclarationExpression
assert decl.variableExpression.name == 'i'
assert decl.variableExpression.originType == ClassHelper.int_TYPE
})
void someMethod() {
int x = 1;
int y = 10;
anchor: for (int i=0; i<x+y; i++) {
println "$i"
}
}
}
@ASTTest 通常会在测试闭包内暴露以下这些变量:
node与通常一样,对应已注释的节点。compilationUnit可访问当前的org.codehaus.groovy.control.CompilationUnit。compilePhase返回当前的编译阶段(org.codehaus.groovy.control.CompilePhase)。
还有一个好玩的情况,假如没有指定 phase 属性。在这种情况下,闭包将会在每个编译阶段后SEMANTIC_ANALYSIS 后(并包括)得以执行。转换的上下文在每个阶段后还保留着,以便检查在两次阶段中所改变的内容。
下面的范例介绍了如何转储在一个类节点上注册的一列 AST 信息:
import groovy.transform.ASTTest
import groovy.transform.CompileStatic
import groovy.transform.Immutable
import org.codehaus.groovy.ast.ClassNode
import org.codehaus.groovy.control.CompilePhase
@ASTTest(value={
System.err.println "Compile phase: $compilePhase"
ClassNode cn = node
System.err.println "Global AST xforms: ${compilationUnit?.ASTTransformationsContext?.globalTransformNames}"
CompilePhase.values().each {
def transforms = cn.getTransforms(it)
if (transforms) {
System.err.println "Ast xforms for phase $it:"
transforms.each { map ->
System.err.println(map)
}
}
}
})
@CompileStatic
@Immutable
class Foo {
}下例展示了如何记住在两个阶段之间用于测试的变量:
import groovy.transform.ASTTest
import groovy.transform.ToString
import org.codehaus.groovy.ast.ClassNode
import org.codehaus.groovy.control.CompilePhase
@ASTTest(value={
if (compilePhase==CompilePhase.INSTRUCTION_SELECTION) { 1⃣️
println "toString() was added at phase: ${added}"
assert added == CompilePhase.CANONICALIZATION 2⃣️
} else {
if (node.getDeclaredMethods('toString') && added==null) { 3⃣️
added = compilePhase 4⃣️
}
}
})
@ToString
class Foo {
String name
}
1⃣️ 如果当前编译器阶段是指令选择阶段。
2⃣️ 那么我们要保证 toString 添加到 CANONICALIZATION 中。
3⃣️ 否则,如果 toString 存在,added 这个从上下文而来的变量就会为 null。
4⃣️ 那么,编译器阶段是添加 toString 的那个阶段。
2.1.10. Grape handling
@groovy.lang.Grab
@groovy.lang.GrabConfig
@groovy.lang.GrabExclude
@groovy.lang.GrabResolver
@groovy.lang.Grapes
Grape 是一个内嵌入 Groovy 中的依赖项管理引擎,它依赖于一些前文介绍过的注释。
2.2 开发 AST 转换
有两类转换:全局和局部。
-
全局转换是由编译器应用于被编译的代码上的。实现全局转换的已编译类位于一个添加到编译器类路径的 Jar 文件中,含有服务定位器文件
META-INF/services/org.codehaus.groovy.transform.ASTTransformation,其中含有转换类名。转换类必须是一个无参构造函数,并且实现了org.codehaus.groovy.transform.ASTTransformation接口。它将针对编译时的每个源来运行,所以为提高编译速度起见,千万不要用粗放而且耗费时间的方式来创建能够扫描所有 AST 的转换。 - 局部转换是一种通过注释那些想要转换的代码元素,从而实现局部应用的转换。为此,我们需要重用注释标记,这些注释标记应该实现
org.codehaus.groovy.transform.ASTTransformation。编译器自然会发现它们,然后将转换应用于这些代码元素。
2.2.1 编译阶段指南
Groovy AST 转换只能应用于 9 个编译阶段(org.codehaus.groovy.control.CompilePhase)之一。
全局转换可以应用于任何一个阶段,而局部转换则只能应用于语义分析阶段或其后阶段。编译器阶段为:
- 初始化阶段(Initialization):打开源文件,配置环境参数。
- 语法解析阶段(Parsing):使用语法来产生表示源代码的令牌树。
- 转换阶段(Conversion):从令牌树中创建抽象语法树(AST)。
- 语义分析阶段(Semantic Analysis):针对一致性及有效性进行检查,这是语法所检查不了的,然后解析类。
- 规范化阶段(Canonicalization):完整地构建 AST。
- 指令选择阶段(Instruction Selection):选择指令集合,比如:Java 6 或 Java 7 字节码级别。
- 类生成阶段(Class Generation):在内存中创建类的字节码。
- 输出阶段(Output):编写二进制输出到文件系统。
- 终止阶段(Finalization):执行最后的垃圾回收及清理工作。
总体来说,在阶段后期会获得更多的类型信息。如果转换涉及到读取 AST,稍后一些的阶段信息会更丰富,因此会更合适一些;如果转换涉及到写入 AST,则适宜采用较早的阶段,因为此时树的结构更稀疏。
2.2.2 局部转换
局部 AST 转换是相对于它们应用的上下文而言的。在多数情况下,上下文是由定义转换范围的注释所定义的。比如,定义一个字段意味著转换将应用到该字段上,而定义一个类也意味着转换将应用到整个类上。
下面来考虑一个简单的例子,假设想编写一个 @WithLogging 转换,在方法调用过程的起始阶段和结束阶段添加控制台消息。下面的 “Hello World” 范例会打印出 "Hello World" 以及起始和结束消息。
@WithLogging
def greet() {
println "Hello World"
}
greet()使用局部 AST 转换就能轻松实现,它需要两个要素:
@WithLogging注释的定义。org.codehaus.groovy.transform.ASTTransformation的实现,将日志表达式添加到方法上。
ASTTransformation 是一个能够让你访问 org.codehaus.groovy.control.SourceUnit 的回调函数,通过它你可以获得一个 org.codehaus.groovy.ast.ModuleNode(AST) 的引用。
AST(抽象语法树)是一个树状结构,其中大多数是 org.codehaus.groovy.ast.expr.Expression(表达式) 或 org.codehaus.groovy.ast.expr.Statement(语句)。学习 AST 的最佳途径是在调试器中探索它的用法。一旦有了 AST,就可以解析它,来了解代码信息或者重新编写加入新的功能。
局部转换注释是非常简单的,下面来看看 @WithLogging:
import org.codehaus.groovy.transform.GroovyASTTransformationClass
import java.lang.annotation.ElementType
import java.lang.annotation.Retention
import java.lang.annotation.RetentionPolicy
import java.lang.annotation.Target
@Retention(RetentionPolicy.SOURCE)
@Target([ElementType.METHOD])
@GroovyASTTransformationClass(["gep.WithLoggingASTTransformation"])
public @interface WithLogging {
} 注释的保持性是 SOURCE,因为你不需要注释通过它。这里的元素类型是 METHOD,因为注释 @WithLogging 应用到方法上。
但最重要的还是 @GroovyASTTransformationClass 注释。它将注释 @WithLogging 与你要编写的 ASTTransformation 类链接到一起。gep.WithLoggingASTTransformation 是我们要编写的 ASTTransformation 完整限定类名。这行代码将注释链接到了转换中。
做好上面这些之后,每当源单元中出现 @WithLogging 时,Groovy 编译器就开始调用 gep.WithLoggingASTTransformation。当运行这个简单脚本时,任何设置在 LoggingASTTransformation 中的断点都会在 IDE 中被触发。
ASTTransformation 类稍微复杂一些。下面是一个非常简单的转换,将为 @WithLogging 添加方法起始和结束的消息:
@CompileStatic 1⃣️
@GroovyASTTransformation(phase=CompilePhase.SEMANTIC_ANALYSIS) 2⃣️
class WithLoggingASTTransformation implements ASTTransformation { 3⃣️
@Override
void visit(ASTNode[] nodes, SourceUnit sourceUnit) { 4⃣️
MethodNode method = (MethodNode) nodes[1] 5⃣️
def startMessage = createPrintlnAst("Starting $method.name") 6⃣️
def endMessage = createPrintlnAst("Ending $method.name") 7⃣️
def existingStatements = ((BlockStatement)method.code).statements 8⃣️
existingStatements.add(0, startMessage) 9⃣️
existingStatements.add(endMessage) ⑩
}
private static Statement createPrintlnAst(String message) { ⑪
new ExpressionStatement(
new MethodCallExpression(
new VariableExpression("this"),
new ConstantExpression("println"),
new ArgumentListExpression(
new ConstantExpression(message)
)
)
)
}
}
1⃣️ 在 Groovy 中编写 AST 转换时,即使并不强制,也强烈建议使用 CompileStatic,因为这能提高编译器的性能。
2⃣️ 利用 org.codehaus.groovy.transform.GroovyASTTransformation 来注释,从而得知转换运行的具体编译阶段。这里正处于语义解析阶段。
3⃣️ 实现 ASTTransformation 接口。
4⃣️ 该接口只有一个 visit 方法。
5⃣️ nodes 参数是一个包含 2 个 AST 节点的数组。第一个是注释节点(@WithLogging),第二个是已被注释节点(方法节点)。
6⃣️ 创建一个语句,当进入方法时,打印消息。 7⃣️ 创建一个语句,当退出方法时,打印消息。 8⃣️ 方法体,在该例中是 BlockStatement。
9⃣️ 在已有代码的第一个语句之前添加进入方法消息。
⑩ 在已有代码的最后一个语句之后添加结束方法消息。
⑪ 创建一个 ExpressionStatement ,用来封装一个对应于 this.println("message") 的 MethodCallExpression。
重点是要注意本例的简洁风格,这里没有制定必要的检查,比如检查已注释节点是否真的是 MethodNode,或者检查方法体是 BlockStatement 的实例,等等。完善该例的工作就留给读者来完成了。
createPrintlnAst(String) 方法中新打印语句的创建过程值得我们注意下。创建代码的 AST 并不总是非常简单的。本例中,我们需要构建一个新的方法调用,传入接收者/变量、方法名称,以及一个参数列表。在创建 AST 时,将要创建的代码用 Groovy 文件保存是很有用的,在调试器中调查代码的 AST 也能让你学会应该创建的内容。从而学会如何编写类似 createPrintlnAst 这样的函数。
最后:
@WithLogging
def greet() {
println "Hello World"
}
greet() 产生:
Starting greet
Hello World
Ending greet 一定要知道,AST 转换直接参与到了编译过程中。初学者常犯的一个错误是将同一源树的 AST 转换代码当成是使用转换的类。位于同一源树一般意味着它们会在同一时间被编译。因为转换本身会在阶段中被编译,每个编译阶段都会处理同一源单位的所有文件,然后交由下一阶段继续处理。直接后果就是:转换无法在使用它的类之前获得编译!总之,AST 转换需要在使用前进行预编译。一般来说,将它们放在不同的源树会更方便一些。
2.2.3 全局转换
全局 AST 转换跟局部转换的一个重大区别在于:不需要注释,这意味着它们是全局应用的,也就是要应用到每个被编译的类上。由于全局转换会对编译器效率产生极大影响,所以一定要把它们最后的手段,不到万不得已不可使用。
沿袭使用上文中局部转换的范例,追踪所有的方法,而不仅仅是那些受 @WithLogging 注释的方法。基本上,我们希望这种代码的行为类似于之前经过 @WithLogging 的方法:
def greet() {
println "Hello World"
}
greet() 实现这一点需要完成以下两步工作:
- 在
META-INF/services目录中创建org.codehaus.groovy.transform.ASTTransformation描述符。 - 创建
ASTTransformation实现。
描述符文件是必需的,必须位于类路径中。它将包含这行代码:
META-INF/services/org.codehaus.groovy.transform.ASTTransformation
gep.WithLoggingASTTransformation
转换代码看起来与局部用例没什么区别,但我们使用的是 SourceUnit,而不是 ASTNode[] 参数:
gep/WithLoggingASTTransformation.groovy
@CompileStatic 1⃣️
@GroovyASTTransformation(phase=CompilePhase.SEMANTIC_ANALYSIS) 2⃣️
class WithLoggingASTTransformation implements ASTTransformation { 3⃣️
@Override
void visit(ASTNode[] nodes, SourceUnit sourceUnit) { 4⃣️
def methods = sourceUnit.AST.methods 5⃣️
methods.each { method -> 6⃣️
def startMessage = createPrintlnAst("Starting $method.name") 7⃣️
def endMessage = createPrintlnAst("Ending $method.name") 8⃣️
def existingStatements = ((BlockStatement)method.code).statements 9⃣️
existingStatements.add(0, startMessage) ?
existingStatements.add(endMessage) ⑪
}
}
private static Statement createPrintlnAst(String message) { ⑫
new ExpressionStatement(
new MethodCallExpression(
new VariableExpression("this"),
new ConstantExpression("println"),
new ArgumentListExpression(
new ConstantExpression(message)
)
)
)
}
}
1⃣️ 在 Groovy 中编写 AST 转换时,即使并不强制,也强烈建议使用 CompileStatic,因为这能提高编译器的性能。
2⃣️ 利用 org.codehaus.groovy.transform.GroovyASTTransformation 来注释,从而得知转换运行的具体编译阶段。这里正处于语义解析阶段。
3⃣️ 实现 ASTTransformation 接口。
4⃣️ 该接口只有一个 visit 方法。
5⃣️ sourceUnit 参数可以提供对正在编译的源的访问,因此能够获取当前源的 AST 并从该方法中获取方法列表。
6⃣️ 迭代源文件中的每个方法。
7⃣️ 在进入方法时创建一个打印消息的语句。
8⃣️ 在退出方法时创建一个打印消息的语句。
9⃣️ 获取方法体,本例中是 BlockStatement。
? 在已有代码的第一条语句之前添加进入方法消息。
⑪ 在已有代码的最后一条语句之前附加退出方法消息。
⑫ 创建一个 ExpressionStatement ,用来封装一个对应于 this.println("message") 的 MethodCallExpression。
2.2.4 AST API 指南
AbstractASTTransformation
尽管我们看到,可以直接实现 ASTTransformation 接口,但在绝大多数情况下你不能这么做,而只能扩展 org.codehaus.groovy.transform.AbstractASTTransformation 类。该类提供的几种工具方法能轻松地实现 AST 转换。几乎所有 Groovy 所包含的 AST 转换都扩展自该类。
ClassCodeExpressionTransformer
将一个表达式转换成另一个表达式是一种常见的用例。Groovy 提供了一个能够轻松实现此种应用的类:org.codehaus.groovy.ast.ClassCodeExpressionTransformer。
创建一个 @Shout 转换,将方法调用参数中所有的 String 常量都转换为它们的大写字母版本。例如:
@Shout
def greet() {
println "Hello World"
}
greet() 打印结果为:
HELLO WORLD
转换代码可以使用 ClassCodeExpressionTransformer 使这项工作更轻松:
@CompileStatic
@GroovyASTTransformation(phase=CompilePhase.SEMANTIC_ANALYSIS)
class ShoutASTTransformation implements ASTTransformation {
@Override
void visit(ASTNode[] nodes, SourceUnit sourceUnit) {
ClassCodeExpressionTransformer trn = new ClassCodeExpressionTransformer() { 1⃣️
private boolean inArgList = false
@Override
protected SourceUnit getSourceUnit() {
sourceUnit 2⃣️
}
@Override
Expression transform(final Expression exp) {
if (exp instanceof ArgumentListExpression) {
inArgList = true
} else if (inArgList &&
exp instanceof ConstantExpression && exp.value instanceof String) {
return new ConstantExpression(exp.value.toUpperCase()) 3⃣️
}
def trn = super.transform(exp)
inArgList = false
trn
}
}
trn.visitMethod((MethodNode)nodes[1]) 4⃣️
}
}
1⃣️ 转换内部创建了 ClassCodeExpressionTransformer。
2⃣️ 转换器需要返回源单元。
3⃣️ 如果参数列表中发现类型字符串的常量表达式,将其转换为大写形式。
4⃣️ 在被注释的方法上调用转换器。
AST 节点
编写 AST 转换需要对 Groovy API 内部运作机制有深入了解,尤其需要了解 AST 类。因为这些类是内部的,所以 API 有可能会在将来对其进行改动,从而造成转换失败的情况。尽管有这种隐患,但 AST 还是比较稳固的,这种情况很少发生。
抽象语法树类属于 org.codehaus.groovy.ast 包。强烈建议读者使用 Groovy 控制台来了解这些类,特别是 AST 浏览器工具。利用 AST Builder 测试套件也是一个不错的学习途径。
2.2.5 测试 AST 转换
分离源树
本节内容是关于测试 AST 转换的最佳实践的。前面的几节重点讲了要想执行一个 AST 转换,就必须进行预编译。虽然听上去非常简单,但很多人还是会栽在这上头,试图在定义 AST 转换的那个源树上使用 AST 转换。
测试 AST 转换的第一要点在于,一定要将测试源和转换源分离开。再次声明,这就是最佳实践,但你一定也要确保构建能实际地分别进行编译。在 Apache Maven 和 Gradle 中这都是默认的。
调试 AST 转换
在 AST 转换中添加断点非常方便,所以可以在 IDE 中来调试代码。但是有可能你会发现 IDE 并不能在断点处停止。原因其实很简单:如果 IDE 使用 Groovy 编译器来编译 AST 转换的单元测试,那么编译就是从 IDE 中触发的,但编译文件的过程并没有调试选项。只有当测试用例执行时,调试选项才会设置在虚拟机上。简而言之:太晚了,类已经被编译了,转换已经应用了。
使用 GroovyTestCase 类就能很方便地解决这个问题,它能提供一个 assertScript 的方法。这意味着我们不必像下面这样来写代码:
static class Subject {
@MyTransformToDebug
void methodToBeTested() {}
}
void testMyTransform() {
def c = new Subject()
c.methodToBeTested()
}
应该这样写:
void testMyTransformWithBreakpoint() {
assertScript '''
import metaprogramming.MyTransformToDebug
class Subject {
@MyTransformToDebug
void methodToBeTested() {}
}
def c = new Subject()
c.methodToBeTested()
'''
}
当你使用 assertScript 时,一旦单元测试被执行,那么 assertScript 代码块中的代码就会被编译。也就是说这时 Subject 类会被编译,同时激活了调试功能,就会触发断点。
ASTTest
最后要介绍的是,测试 AST 转换也意味着要测试 AST 在编译时的状态。Groovy 提供的 @ASTTest 就是这样的一种工具,这种注释恩能够让你添加在 AST 上添加断言,详情参见:ASTTest 文档
2.2.6 外部参考资料
如果你更喜欢按步骤介绍的较为详细的编写 AST 转换的教程,不妨看看这个。

















 2324
2324

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









