







 说明这篇文章主要是为了演示OkHttp和多线程的简单运用,利用多线程和HTTP断点续传的特性实现多线程下载。总体分为三种实现发难,并且实现了这三种方案。这里先说明,这只是一个Demo程序,为了快速实现功能,所以没有太多设计思想在里面,很多异常情况也没有考虑。所以,不喜勿喷,你如果觉得应该怎样,而不是我这样,那你自己去实现好了。当然,如果对我的方案,或实现上面有更好的想法,欢迎讨论。多线程下载方案分...
说明这篇文章主要是为了演示OkHttp和多线程的简单运用,利用多线程和HTTP断点续传的特性实现多线程下载。总体分为三种实现发难,并且实现了这三种方案。这里先说明,这只是一个Demo程序,为了快速实现功能,所以没有太多设计思想在里面,很多异常情况也没有考虑。所以,不喜勿喷,你如果觉得应该怎样,而不是我这样,那你自己去实现好了。当然,如果对我的方案,或实现上面有更好的想法,欢迎讨论。多线程下载方案分...
说明
这篇文章主要是为了演示OkHttp和多线程的简单运用,利用多线程和HTTP断点续传的特性实现多线程下载。总体分为三种实现发难,并且实现了这三种方案。这里先说明,这只是一个Demo程序,为了快速实现功能,所以没有太多设计思想在里面,很多异常情况也没有考虑。所以,不喜勿喷,你如果觉得应该怎样,而不是我这样,那你自己去实现好了。当然,如果对我的方案,或实现上面有更好的想法,欢迎讨论。
多线程下载方案分析
方案一
首先,第一个方案肯定是最简单的,将一个文件的内容按线程数分割任务,每个任务下载一块区域的数据,然后将数据写到各自的临时文件中。每一个任务对应一个线程,所有线程执行完后把临时文件中的内容合并到一个文件中(如下图所示)。
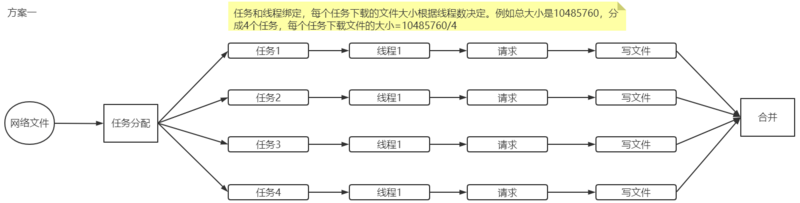
这个方案实现起来很简单,只要懂一点多线程知识都能实现。
方案二
第二种方案骚味高级一些,首先说方案一中的问题。如果不考虑其它因素,单从多线程的角度来看,这种方案不能充分发挥线程的优势。举个栗子,如果有4个线程,有3个结束了,剩下那个执行很慢,就得等它结束才能执行后续步骤,它手上的任务也不能分出来个其它线程来处理,这样就会拖累整个进度。所以就会出现这样一个场景:忙的很忙,闲的很闲。
所以,为了让每个线程都忙起来,就需要将任务分成诺干个小任务。这样,即使有一个线程慢,那它影响的只是它现在处理的那一小块任务,其它线程执行完当前的任务后,又可以去领取任务了继续来做。
基于上面的分析,可以设定一个阈值(即每个任务下载的文件大小),按这个阈值将整个文件分解成诺干任务,然后放在线程池中,让线程去处理。线程池中的线程数是固定的,一般都是CPU的内核数,比如8个/16个或32个。这样就能让每个CPU都工作起来(多线程并不是线程越多,执行越快,以后再写文章来说明这个问题)。具体方案如下图所示。
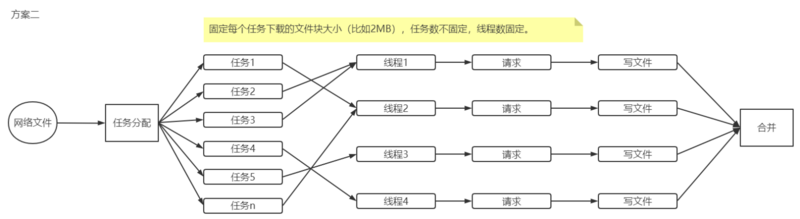
要实现这个方案,就需要用到线程池,要理解线程池的工作原理。如果了解线程池,这个实现起来也不难。
方案三
方案二看上去很完美,但也有两个问题,这里只说一个,另一个留个大家自己去发现,如果你发现了可以在评论区说出来,也可以提出你的解决方案。这里要说的这个问题就是磁盘I/O的问题,虽然以现在的硬盘来说基本上不会出现这个问题,but...请容许我装一波B行么?
第三个方案其实和方案二差不多,只是将写文件改成了写缓存,Why??因为我牛B,我乐意!说正经的,如果你的硬盘写入速度很慢,多慢呢?硬盘写入速度
如果出现了磁盘I/O的问题,那将会影响每个线程的处理效率。因为每个任务里的下载请求返回数据后,都需要将数据写入一个文件,写入文件慢了就会拖累下载速度。所以,方案三与方案二不同的地方,是将写入临时文件换成写入缓存队列(就是内存),然后另一个线程负责去队列去数据,然后写到文件中。这样即使磁盘慢,那也不会影响下载速度了,如下图所示。
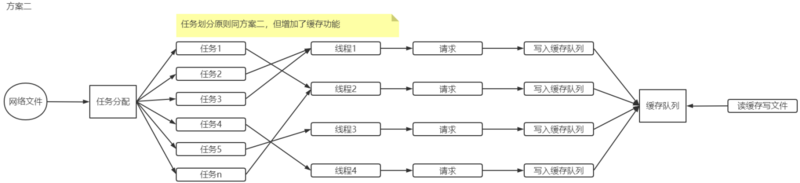
实现了方案二,再实现这个方案就只需要将写入临时文件改成写入缓存队列,合并文件改成一个读缓存队列写文件的线程任务就可以了。这里就需要再了阻塞解队列的概念,同样的,如果你了解什么是阻塞队列,那实现起来也不难了。
要实现以上三种方案,都是有先决条件的:
要先得到文件的大小,如果不清楚文件的大小,那如何划分任务?
需要目标服务器支持断点续传,如果不支持,也没法将任务分成多个执行,因为每个任务需要下载不同区域的内容,具体到后面方案实现中讲。
以上两点,缺一不可。
方案实现
基于以上实现方案,我们知道了第一步是要先获取文件大小,在HTTP请求中,可以通过响应头的 Content-Length 属性得到。所以,我们第一步是要先发起一个 HEAD 请求,得到文件信息。因为 HEAD 请求只会返回响应头,没有响应体,所以响应速度会很快,而且,我们现在需要的内容在响应头就可以拿到。
// 用于存储下载文件的信息
public class DownloadInfo {
private String fileName;
private long fileSize;
private long saveSize;
private Status status = Status.WAITING;
private Path localPath;
private URL location;
private String description;
private URL refLocation;
private long lastConnectTime;
......省略get/set
}
下面的 DownloadTask 类实现了一个简单的下载功能,获取下载文件信息的方法就在 initDownloadInfo 方法中,注释已经写得很清楚了,我就不说了,有疑问可以发评论区。在这个方法里面主要获取文件名、文件大小、是否支持断点续传、服务器是否使用的分片传输这些内容。
只有服务器支持断点续传(响应头的Accept-Ranges=bytes表示支持),我们才能够使用多线程去下载,因为断点续传就是通过在请求中加一个Range头,告诉服务器,你需要取文件哪个范围的内容。所以,这样就可以使用多线程,每个线程分别高速服务器取不同范围的内容,这也就是多线程下载的原理。
所以,要实现多线程下载,最主要的是看服务器能不能支持了,如果不支持,那就没法实现,因为每次请求,它都会返回所有的内容,这样即使你使用多线程,每个线程取的内容一样,这样根本毫无意义。
另外,有些服务器可能还会开启分片传输(响应头的Transfer-Encoding=chunked表示已开启),如果遇到这样的请求,也没法实现多线程下载。因为服务器的分片传输它不会在响应头告诉你这个文件有多大,而是在响应体中把内容一点一点传给你。所以,遇到这样的,你就只能老老实实用一个线程取慢慢接受了。
还有些服务器的断点续传请求可能还会需要带入 ETag (可以把它当成文件的唯一编号,文件内容有变化,这个值也会变)。所以,我下面的代码中,取了这几个属性。
import lombok.extern.slf4j.Slf4j;
import okhttp3.OkHttpClient;
import okhttp3.Request;
import okhttp3.Response;
import org.apache.commons.lang3.math.NumberUtils;
import org.nbpeak.net.download.Utils;
import org.nbpeak.net.download.demo.pojo.DownloadInfo;
import java.io.IOException;
import java.io.InputStream;
import java.io.UnsupportedEncodingException;
import java.net.URL;
import java.net.URLDecoder;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
/**
* 单线程下载,主要为了演示OkHttp的基本用法
*/
@Slf4j
public class DownloadTask {
private boolean chunked;
private boolean supportBreakpoint;
private DownloadInfo downloadInfo;
private String eTag;
public DownloadTask(String url) throws IOException {
initDownloadInfo(url);
}
public DownloadInfo getDownloadInfo() {
return downloadInfo;
}
/**
* 初始化下载信息,根据URL获取文件信息
*
* @param url
* @throws IOException
*/
private void initDownloadInfo(String url) throws IOException {
log.info("初始化,获取下载文件信息...");
OkHttpClient client = new OkHttpClient();
// 创建客户端对象和请求对象,发起head请求
Request headRequest = new Request.Builder()
.head()
.url(url)
.build();
// 发起请求,从响应头获取文件信息
try (Response response = client.newCall(headRequest).execute()) {
long length = -1;
String fileName = getFileName(response);
log.info("获取到文件名:" + fileName);
// 获取分块传输标志
String transferEncoding = response.header("Transfer-Encoding");
this.chunked = "chunked".equals(transferEncoding);
log.info("是否分块传输:" + Utils.yesOrNo(chunked));
// 没有分块传输才可获取到文件长度
if (!this.chunked) {
String strLen = response.header("Content-Length");
length = NumberUtils.toLong(strLen, length);
log.info("文件大小:" + Utils.byteToUnit(length));
}
// 是否支持断点续传
String acceptRanges = response.header("Accept-Ranges");
this.supportBreakpoint = "bytes".equalsIgnoreCase(acceptRanges);
this.eTag = response.header("ETag");
log.info("是否支持断点续传:" + Utils.yesOrNo(supportBreakpoint));
log.info("ETag:" + eTag);
// 创建下载信息
this.downloadInfo = new DownloadInfo(new URL(url), length, fileName);
}
}
/**
* 开始下载
*
* @param saveTo 保存到哪
* @throws IOException
*/
public void start(String saveTo) throws IOException {
// 确保目录存在
Path dirPath = Paths.get(saveTo);
if (!Files.exists(dirPath)) {
Files.createDirectories(dirPath);
}
downloadInfo.setLocalPath(Paths.get(saveTo, downloadInfo.getFileName()));
// 创建客户端对象和请求对象,发起get请求
OkHttpClient client = new OkHttpClient();
Request getRequest = new Request.Builder()
.url(downloadInfo.getLocation())
.build();
log.info("下载任务开始");
log.info("下载地址:" + downloadInfo.getLocation());
log.info("保存地址:" + downloadInfo.getLocalPath());
log.info("文件大小:" + Utils.byteToUnit(downloadInfo.getFileSize()));
log.info("是否支持断点续传:" + Utils.yesOrNo(isSupportBreakpoint()));
downloadInfo.setStatus(DownloadInfo.Status.RUNNING);
try (Response response = client.newCall(getRequest).execute()) {
final Path localPath = downloadInfo.getLocalPath();
Files.deleteIfExists(localPath);
final InputStream inputStream = response.body().byteStream();
Files.copy(inputStream, localPath);
downloadInfo.setStatus(DownloadInfo.Status.FINISHED);
log.info("下载完成");
}
}
/**
* 根据响应头或URL获取文件名
*
* @param response
* @return
*/
private String getFileName(Response response) {
String charset = "UTF-8";
String uriPath = response.request().url().uri().getRawPath();
String name = uriPath.substring(uriPath.lastIndexOf("/") + 1);
String contentDisposition = response.header("Content-Disposition");
if (contentDisposition != null) {
int p1 = contentDisposition.indexOf("filename");
//有的Content-Disposition里面的filename后面是*=,是*=的文件名后面一般都带了编码名称,按它提供的编码进行解码可以避免文件名乱码
int p2 = contentDisposition.indexOf("*=", p1);
if (p2 >= 0) {
//有的Content-Disposition里面会在文件名后面带上文件名的字符编码
int p3 = contentDisposition.indexOf("''", p2);
if (p3 >= 0) {
charset = contentDisposition.substring(p2 + 2, p3);
} else {
p3 = p2;
}
name = contentDisposition.substring(p3 + 2);
} else {
p2 = contentDisposition.indexOf("=", p1);
if (p2 >= 0) {
name = contentDisposition.substring(p2 + 1);
}
}
}
try {
name = URLDecoder.decode(name, charset);
} catch (UnsupportedEncodingException e) {
}
return name;
}
public boolean isSupportBreakpoint() {
return supportBreakpoint;
}
}
这是一个单线程版,仅为了熟悉OkHttp的用法(我这是第
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 519
519











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









