






哈哈,学了几天golang,就用golang+goquery 配合chrome web scraper插件实现了一个百度知道标题的十分简易爬虫。呵呵,遇到了一个坑,就是网页是gbk编码,需要转utf-8,自己多次尝试,用个第三方库 github.com/axgle/mahonia 总算解决了。用chrome浏览器 web scraper插件的好处,就是不用你去看网页源码,不用去分析他的选择器,直接用web scraper里的选择器,网页上选一下,就能获得唯一的选择器代码,还可以预览数据。对于不懂前端编程不懂HTML+CSS和DOM的人来说,真的是所见即所得。直接复制web scraper插件里的选择器代码到goquery里即可。爬虫采集数据变的十分简单了。废话不多说,直接看代码:
package main import ( "fmt" "github.com/PuerkitoBio/goquery" "github.com/axgle/mahonia" "net/http" ) func main() { url:= "https://zhidao.baidu.com/search?lm=0&rn=10&pn=0&fr=search&ie=gbk&word=%CD%F8%C2%E7%D3%AA%CF%FA" resp, err := http.Get(url) if err != nil {panic(err)} if resp.StatusCode != 200 { fmt.Println("err") } html:= resp.Body doc, err := goquery.NewDocumentFromReader(html) encode:=mahonia.NewDecoder("gbk") //从()括号里的编码 解码成UTF-8编码 doc.Find("a.ti").Each(func(i int, contentSelection *goquery.Selection) { title := contentSelection.Text() utf8title:=encode.ConvertString(title) fmt.Println("第", i+1, "个帖子的标题:", utf8title) }) }
这个爬虫十分简易,也没做翻页等,纯粹是练手。
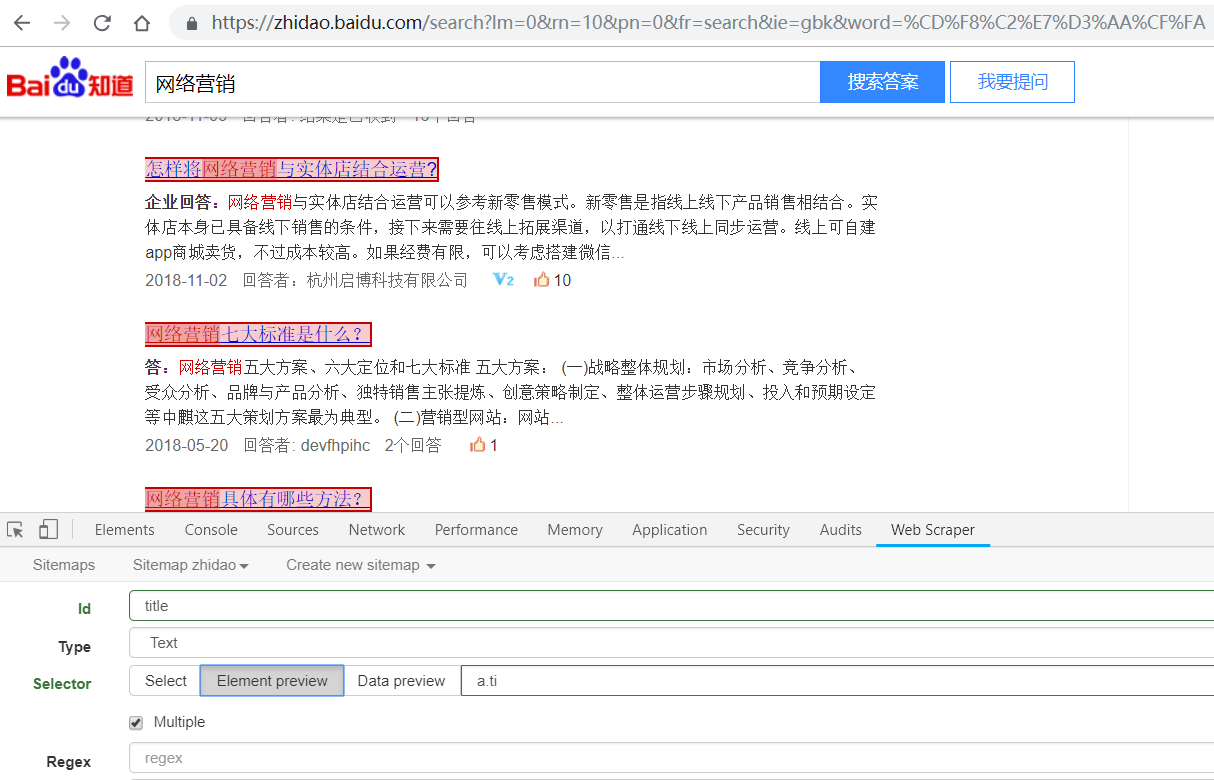
下面的截图是 chrome插件web scraper 获取选择器的截图,超级简单实用:















 2654
2654











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









