







1.flume的基本概念
本文中所有与flume相关术语都采用斜体英文表示,这些术语的含义如下所示。
flume 一个可靠的,分布式的,用于采集,聚合,传输海量日志数据的系统。
Web Server 一个产生 Events 的系统。
Agent flume 系统中的一个节点,它主要包含三个部件:Source, Channel, Sink。
Event 事件,在 flume-agent 内部传输的数据结构。一个 Event 由 Map<String, String>Headers 和 byte[] body 组成,其中 Headers 保存了 Event 的属性,body 保存了 Event 的内容。
Source Agent Source 用来接收 WebServer 产生的 Events,以及其他 flume-agent 中的 Sink产生的 Events。
Channel Source 将 Events 放在 Channel 中保存,Channel 主要有两种,是 MemoryChannel 和FileChannel,分别将 Events 存放在内存中和文件中。
Sink Sink 用来消费 Channel 内保存的 Events,然后将 Events 发送出去。
Sinkgroups 将多个 Sink 组合在一起,形成 Sinkgroups。
HDFS Hadoop分布式文件系统,它用来存储日志数据,也就是 Sinks 发送出来的 Events。
2.flume的数据流模型
(1) 单 Agent 数据流模型
如下图1所示,单个 Agent 主要包括三个部件:Source, Channel, Sink。

图1 单Agent的数据流模型
整个数据流如下:
Web Server 产生 Events,并将 Events 发送到 Source 中。
Source 接收 Events,并将 Events 发送到 Channel 中。
Channel 存储 Events。
Sink 消费Channel 中存储的 Events,并将 Events 发送到 HDFS。
HDFS 磁盘存储 Events。
(2)多 Agent 串行传输数据流模型
如图2所示,两个 Agent 组成的数据流传输模型。

图2: 两个 Agent 串行传输数据流模型
整个数据流如下:
Agent foo Agent foo 中的 Source 接收外部 Events,存储到 Channel 中,Sink 从 Channel 中获取 Events,再将 Events 传输到 Agent bar 的 Source 中。
Agent bar Agent bar 中的 Source 接收 Agent foo 的 Sink 发送的 Events,存储到 barChannel,再由 bar Sink消费。
整个数据流只做了一件事,就是传输数据。
(3)收集数据流模型
如图3所示,Agent1,Agent2,Agent3负责从不同的 Web Server 中接收 Events,并将 Events 发送到 Agent4,Agent4 再将 Events 发送到 HDFS。
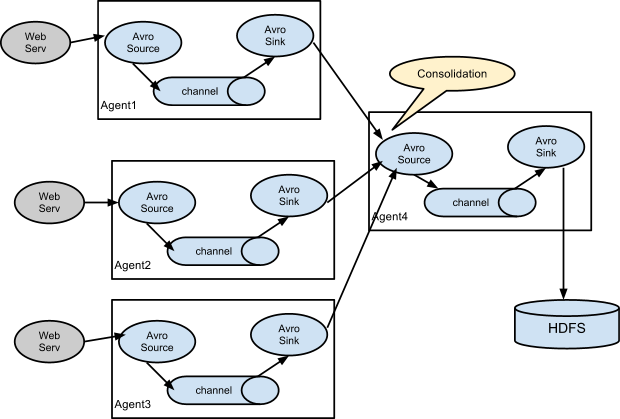
图3:收集数据流模型
整个数据流如下:
Agent1 接收 Events,并将 Events 传输到Agent4。
Agent2 接收 Events,并将 Events 传输到Agent4。
Agent3 接收 Events,并将 Events 传输到Agent4。
Agent4 接收 Agent1,Agent2,Agent3 的 Events,然后将 Events 存储到 HDFS。
整个数据流完成的功能:不同的 Agent 收集不同的 Web Server 产生的日志数据,并将所有的日志数据存储到一个目的地 HDFS。
(4)多路数据流模型
一个 Agent 中可以由一个 Source ,多个 Channels ,多个 Sinks 组成多路数据流,其多路数据流模型如下图4所示。
一个 Source 接收外部 Events,并将 Events 发送到三路 Channel 中去,然后不同的 Sink 消费不同的 Channel 内的 Events ,再将 Events 进行不同的处理。
Source 如何将 Events 发送到不同的 Channel 中?这里 flume 采用了两种不同的策略,是replicating 和 multiplexing 。
其中 replicating 是 Source 将每个 Event 都发送到 Channel 中,这样就将 Events 复制成 3 份发到不同的地方去。
其中 multiplexing 是 Source 根据一些映射关系,将不同种类的 Event 发送到不同的 Channel中去,即将所有 Events 分成3份,分别发送到三个 Channels。
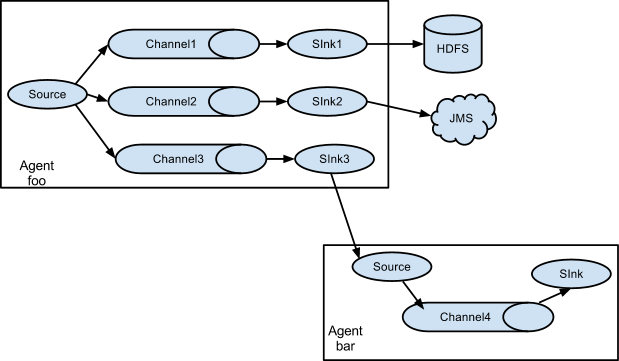
图4 多路数据流模型
整个数据流如下:
Agent foo Source 将接收到的 Events 发送到 Channel1--Sink1--HDFS,Channel2--Sink2--JMS,Channel3--Sink3--Agent bar
Agent bar Source 接收 Agent foo 中 Sink3 发送的 Events,然后发送到 Channel4--Sink
(5) Sinkgroups数据流模型
现在考虑这样两个问题,一是 某 Sink 负责消费某 Channel 中的 Events,那么如果该 Sink 挂掉之后, 该 Channel 则会堵死。
二是 某 Sink 负责消费某 Channel 中的 Events,那么如果该 Sink 速度慢,或者该 Sink 的消费能力达不到 Source 的接收能力呢? 大量的 Events 会在 Channel 中堆积,造成堵塞。
为了解决这两种情况,flume 中存在一种数据流模型,将多个 Sinks 绑定在一起,形成Sinkgroups,它们共同负责消费某个 Channel 内的 Events。
但是在某个时刻,只有一个 Sink 消费 Channel 内的 Events,于是有两种策略保证从Sinkgroups 中选择出一个 Sink 来消费 Channel 中的 Events。
这两种策略分别是:failover 和 load_balance。其中 failover 机制,会将所有 Sinks 标识一个优先级,一个以优先级为序的 Map 保存着 活着的 Sink,一个队列保存着 失败的 Sink。
每次都会选择优先级最高的活着的 Sink 来消费 Channel 的 Events。每过一段时间就对失败队列中的 Sinks 进行检测,如果变活之后,就将其插进 活着的 Sink Map。
另一种 load_balance机制,在这种机制下,还有两种不同的策略,分别是 round_robin 和random。则 round_robin 就是不断地轮询 Sinkgroups 内的 Sinks,已保证均衡。
random 则是从 Sinkgroups 中的 Sinks 随机选择一个。
该数据流模型如下图5所示。

图5 Sinkgroups数据流模型
整个数据流如下:
Source 负责接收 Events,并将其发送到 Channel 中。
Channel 负责存储 Events。
Sinkgroups 负责消费 Channel 中的 Events,并将 Events 发送到 HDFS 存储。
(6)单 Agent,多条数据流
如下图6所示,在单个 Agent 中,可以由多个 Sources,Channels,Sinks 组成多条完全不相交的数据流。
图6
整个数据流如下:
Source1 Channel1 Sink1 HDFS1 组成数据流1
Source2 Channel2 Sink2 HDFS2 组成数据流2
数据流1和数据流2完全不相关。
(7)各种各样的数据流模型
从上面介绍的6种不同的数据流模型中,我们可以得知,模型1和模型2相当于程序设计中的顺序执行。
模型3中 Agent1,Agent2,Agent3 收集 Events 处于并行状态,向 Agent4 发送 Events 处于并发状态。
模型4 相当于程序设计中的 if--else,选择模型。
模型5中 三个 Sinks 也相当于处于并发状态。
模型6 相当于程序设计中的 并行模型。
则通过这6种不同的数据流模型,我们可以将它们进行不同的组合,形成各种各样的数据流模型,以应付我们的需求。
3. 解析数据流模型
不同的数据流模型,具有不同的功能,但是这些数据流模型是靠哪些组件,哪些策略来构成的。本节将分析不同的数据流模型在 Agent 内部是如何实现的。
(1) Agent 内部组件架构
如下图6所示,这是 Agent 内部一个比较完整的架构图,它不仅仅包含了 Source, Channel,Sink,还包含了 SinkRunner, Interceptor, ChannelSelector, Transaction,
SinkRunner, SinkProcessor, SinkSelector。下面我们将详细介绍每个部件在 Agent 内部所承担的责任。

图6 Agent 内部组件架构图
从途中可以看出,将整个数据流分成两阶段,分别是第一阶段:Source --> Channel, 第二阶段: Channel --> Sink。
下面就从这两个阶段来详细介绍各个组件在数据流过程中承担的责任。
(2) 第一阶段
图6既是数据流图,也是对象结构图。从图中可以看出,一个 SourceRunner 对象包含一个 Source对象,一个 Source 对象包含一个 ChannelProcessor对象,
一个 ChannelProcessor 对象包含 多个 Interceptor 对象和一个 ChannelSelector 对象。
首先 SourceRunner 负责启动 Source, 则 Source 监控是否有 Events 发送过来,如果有,则接收 Events。
其次 Events 被 ChannelProcessor 中的 Interceptor 进行过滤,Interceptor 的功能有三种,分别是 丢弃 Event,修改 Event 再返回,直接返回 Event(不做任何操作)。
举例:Interceptor 有两种比较好理解的,分别是 Timestamp Interceptor 和 host Interceptor,Timestamp Interceptor 会对每个 Event 的添加属性时间戳, host Interceptor会为
每个 Event 添加属性 host 。
然后,ChannelSelector 的主要功能是完成上面的多路数据流模型,分别有两种,replicating 和multiplexing。也就是说 ChannelSelector 为每个 Event 选择它所要发送到的 Channel。
在 replicating 模式下,每个 Event 都被发送到 多个 Channel 中;在 multiplexing 模式下,不同的 Events 会被发送到不同的 Channel 中。
最后,Source 与每个 Channel 通过 Transaction 建立连接,将 Events 发送到 Channel 中去。
(3)第二阶段
从图中可以看出,一个 SinkRunner 对象包含一个 SinkProcessor 对象,一个 SinkProcessor 对象包含多个 Sinks 和/或 一个 SinkSelector。
首先 SinkRunner 启动一个 SinkProcessor 对象,SinkProcessor 有三种,分别是DefaultSinkProcessor,FailoverSinkProcessor,LoadBalancingSinkProcessor。
看到这里你是不是有点印象了,对,这就是我们上面提到的 Sinkgroups 数据流模型。如果单个Sink 的话,则使用 DefaultSinkProcessor,它负责启动 Sink;
如果多个 Sinks 组成一组的话,则可以设置 SinkProcessor 为 failover 或 loadBalance。
其中 FailoverSinkProcessor 会将各个 Sink 设置优先级。保存了一个 SortedMap<Integer, Sink> liveSinks,活着的 Sinks,一个 Queue<FailedSink> failedSinks,保存死的 Sinks。
每次会从 liveSinks 中选择一个优先级最高的 Sink 来消费 Events。如果某个 Sink 挂掉,则将其放在 failedSinks里,并且每次都尝试 failedSinks中的第一个 Sink,如果它能变活,则将其
转到 liveSinks 中。其中 LoadBalancingSinkProcessor 里有一个对象 SinkSelector,该SinkSelector 有两种,分别是 round_robin 和 random。这里你又有印象啦。则 SinkSelector 就是在 Sinkgroups 中
选择某个 Sink 来消费 Events。 round_robin 是轮询 Sinkgroups 中的所有 Sinks, random 是从 Sinkgroups 中随机选择 某个 Sink。
其次,SinkProcessor 会选择某个 Sink,启动 Sink。
最后,Sink 与 Channel 通过 Transaction 建立连接。消费 Channel 内的 Events。















 3384
3384

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









