







1、背景
如果有一天有人面试问你:如何对1000万数字进行排序。
这时候你可以回答:“使用forkjoin”。
Fork/Join是在Java7中提供的一个并发执行任务的框架。他的基本运行流程就是:把一个大任务分解成子任务,如果子任务还不是足够小,就继续分解成子子任务,一直分解到足够小。具体要分解到有多小,你可以自己定义这个阈值。
然后把这些子任务分摊给多个线程去执行,每个线程对应一个双端队列负责保存这些原子任务。
这里叫“原子”任务,之所以叫原子任务,就是为了说明他们已经足够小。是经过多次的递归后的结果。
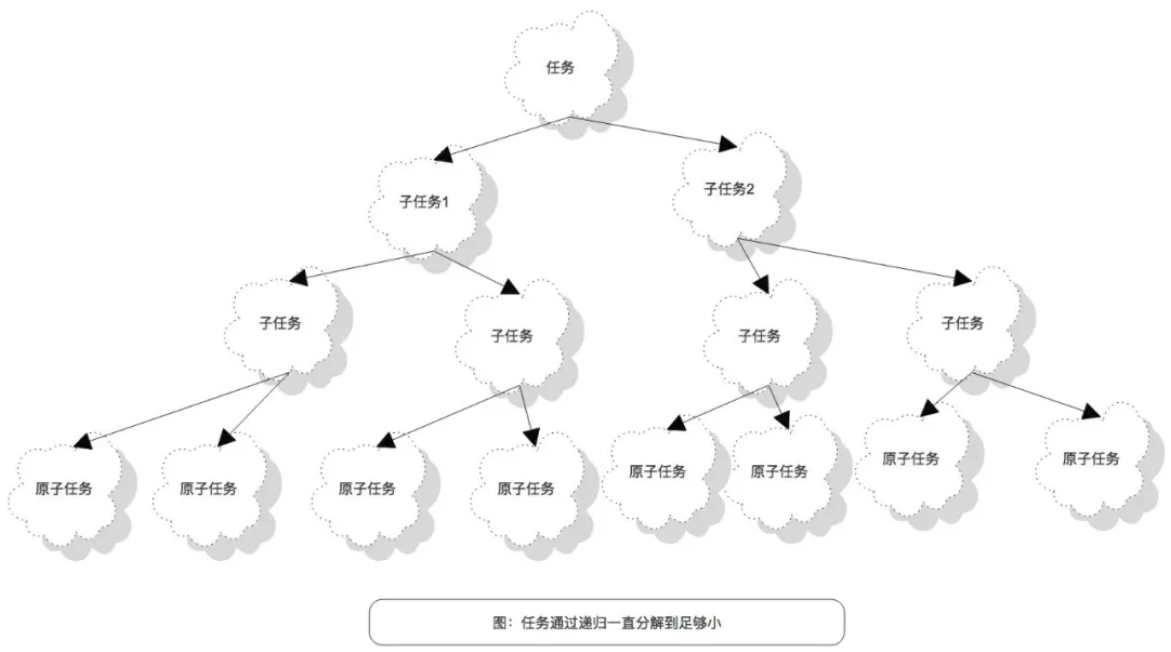
没错,这就是fork的过程。join的过程就是上面的图颠倒过来。
2、工作窃取算法
工作窃取算法指的是某个线程从其他队列里窃取任务来执行。使用的场景是一个大任务拆分成多个小任务,为了减少线程间的竞争,把这些子任务分别放到不同的队列中,并且每个队列都有单独的线程来执行队列里的任务,线程和队列一一对应。但是会出现这样一种情况:A线程处理完了自己队列的任务,B线程的队列里还有很多任务要处理。A是一个很热情的线程,想过去帮忙,但是如果两个线程访问同一个队列,会产生竞争,所以A想了一个办法,从双端队列的尾部拿任务执行。而B线程永远是从双端队列的头部拿任务执行(任务是一个个独立的小任务),这样感觉A线程像是小偷在窃取B线程的东西一样。--引自网络
下图是窃取算法的流程:

3、框架介绍
Fork/Join框架在java.util.concurrent包中定义。包含几个支持并发编程的类和接口。它的主要作用就是它简化了多线程创建的过程及其使用,并自动化了多个处理器之间的进程分配机制。
这个框架中有两个概念,四个核心类:
两个概念:任务(ForkJoinTask)和线程池(ForkJoinPool)。
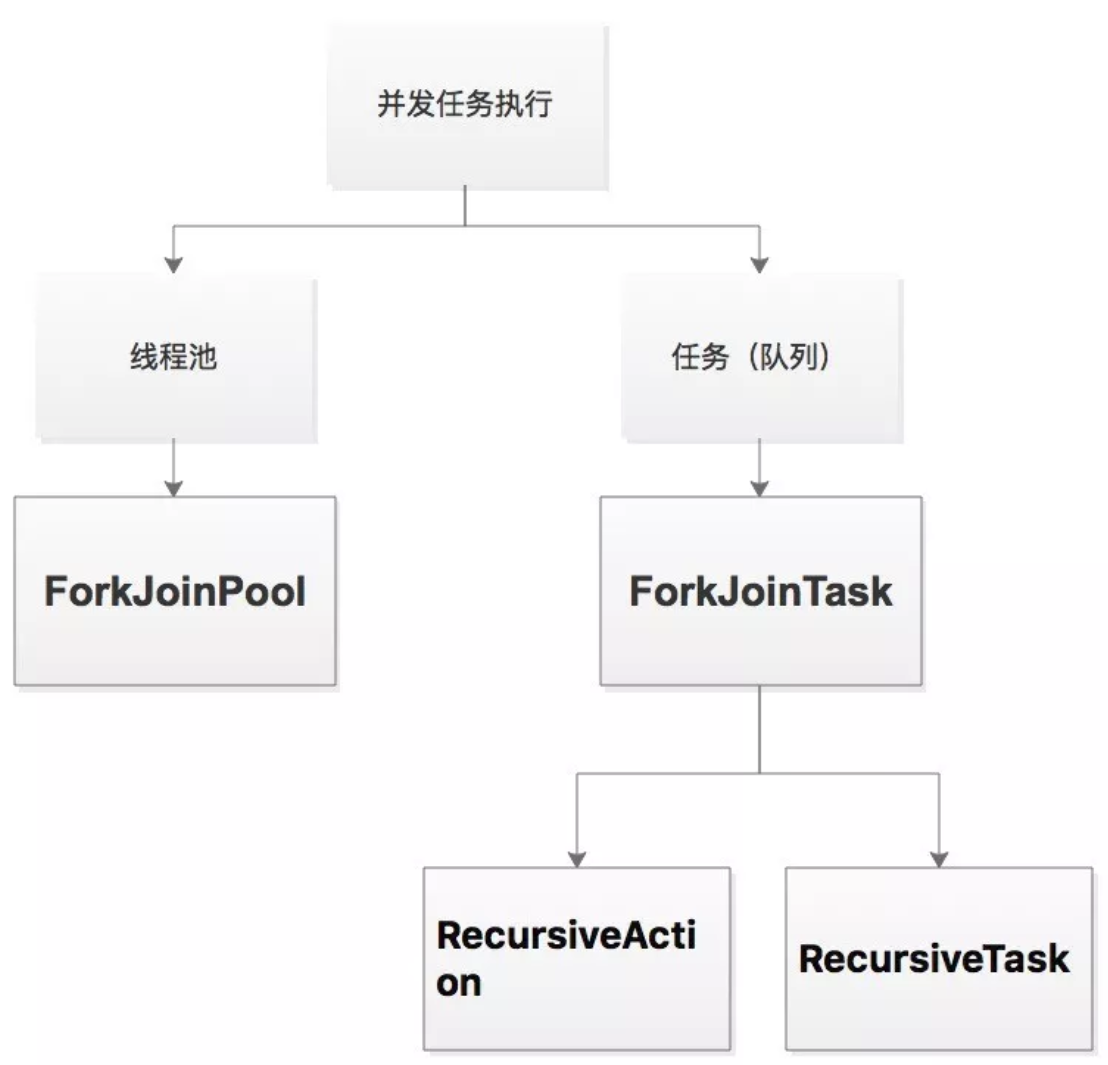
四个核心类:
ForkJoinTask<V>:这是一个抽象类。是Fork/Join任务的一个抽象,你需要继承此类,然后定义自己的计算逻辑。一个任务的创建就是通过此类中的fork()方法来实现的。这里说的任务几乎类似Thread类创建的那些普通线程,但更轻量级。因为它可以使用ForkJoinPool中少量有限的线程来管理大量的任务,所以它要比Thread类创建的线程更轻量。fork()方法异步执行任务,join方法可以一直等待到任务执行完毕。这个我们会在接下来的示例代码中也会有具体讲解。还有另外一个重要的方法就是invoke()方法,它是把fork和join两个操作合二为一成一个单独的调用。总之,主要有三个核心的方法,fork、join、invoke,要记住这三个方法分别是干什么用的。
ForkJoinPool:这个类线程池负责执行ForkJoinTask任务。
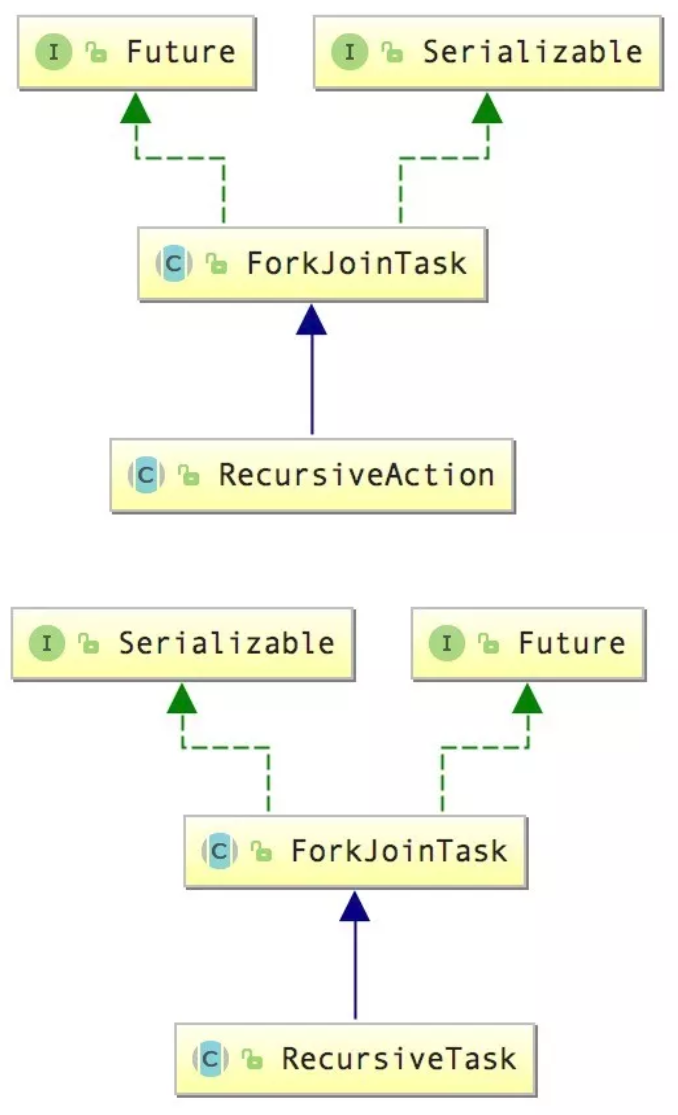
RecursiveAction:是并发包内现成的ForkJoinTask实现之一。继承自ForkJoinTask,负责处理那些不需要返回结果的任务。
RecursiveTask<V>:也是并发包内现成的ForkJoinTask实现之一。继承自ForkJoinTask,负责处理那些需要返回结果的任务。那么怎么记住这两个类的不通电呢?只需要记他们的最后一个单词,一个是Action,一个Task。Action本身就有点感觉是只负责执行,有去无回。
下面是二者的类图关系结构:
4、上代码
接下来我们通过一个求和的例子来说明ForkJoin的流程。现在我们要对1到8的整数进行求和。代码如下:
import java.util.concurrent.ExecutionException;
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.Future;
import java.util.concurrent.RecursiveTask;
public class CountTask extends RecursiveTask<Integer> {
private static final long serialVersionUID = 1L;
//阈值
private static final int THRESHOLD = 2;
private int start;
private int end;
public CountTask(int start, int end) {
this.start = start;
this.end = end;
}
@Override
protected Integer compute() {
int sum = 0;
//判断任务是否足够小
boolean canCompute = (end - start) <= THRESHOLD;
if (canCompute) {
//如果小于阈值,就进行运算
for (int i = start; i <= end; i++) {
sum += i;
}
} else {
//如果大于阈值,就再进行任务拆分
int middle = (start + end) / 2;
CountTask leftTask = new CountTask(start, middle);
CountTask rightTask = new CountTask(middle + 1, end);
//执行子任务
leftTask.fork();
rightTask.fork();
//等待子任务执行完,并得到执行结果
int leftResult = leftTask.join();
int rightResult = rightTask.join();
//合并子任务
sum = leftResult + rightResult;
}
return sum;
}
public static void main(String[] args) {
ForkJoinPool forkJoinPool = new ForkJoinPool();
CountTask task = new CountTask(1, 100);
//执行一个任务
Future<Integer> result = forkJoinPool.submit(task);
try {
System.out.println(result.get());
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}
}上面的代码就是对1到8进行求和。我们继承了RecursiveTask类实现了我们地递归逻辑。以下是这个大任务的拆分过程,最后被拆分成了四个子任务:1+2,3+4,5+6,7+8。在拆分成这四个原子任务之前,是进行了递归fork不断拆分后才最终拆分成四个原子任务的。
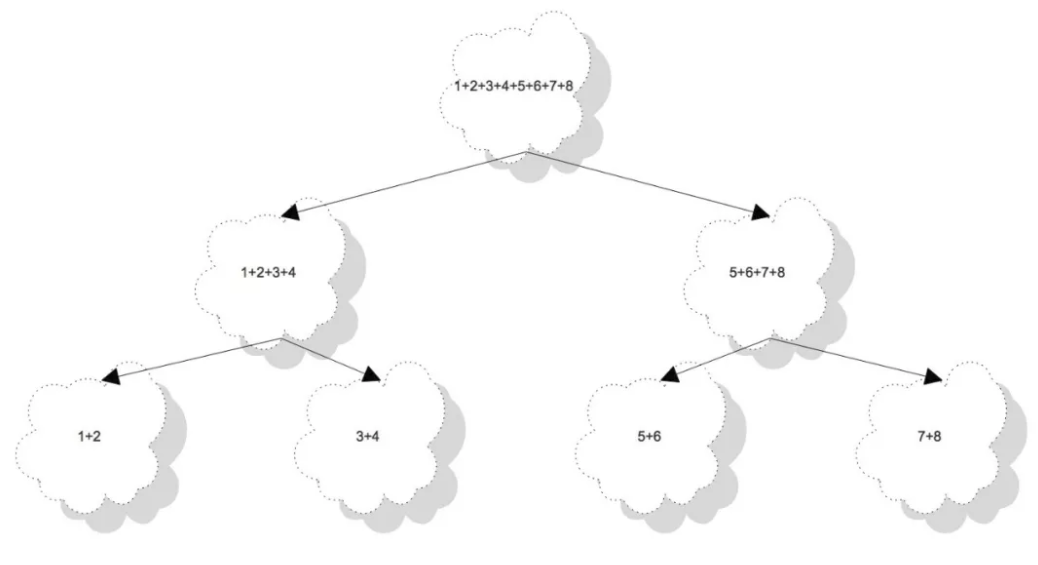
上面的代码中最核心的就是compute方法,以下是compute方法的基本逻辑路程图:
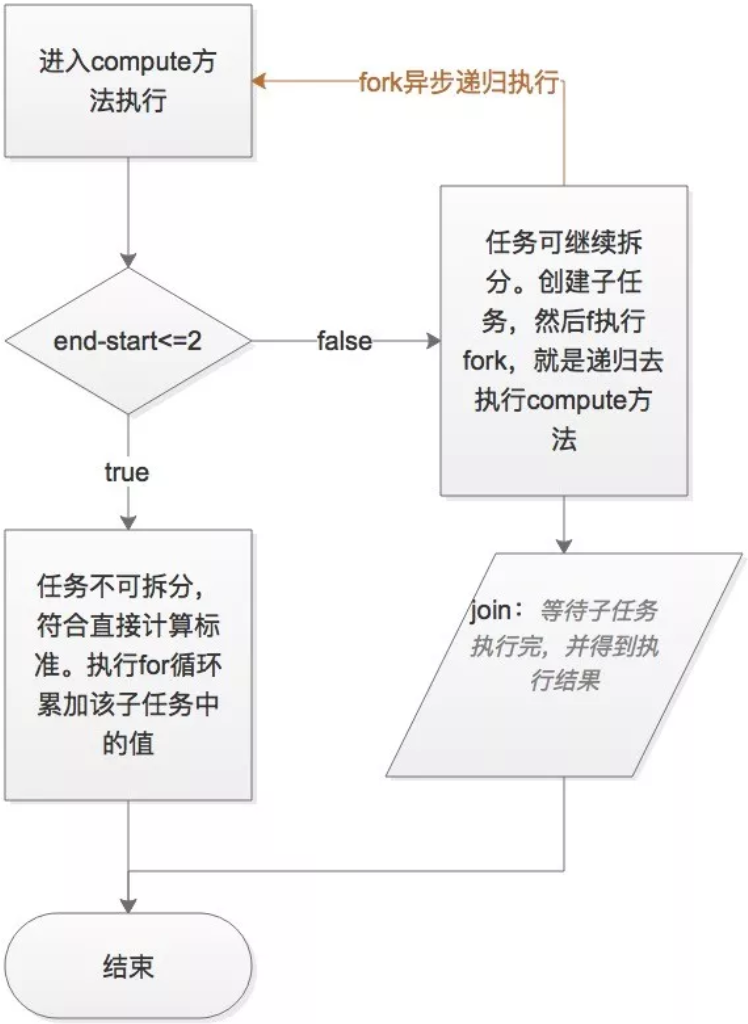
进入compute方法,首先会判断当前任务的边界是否足够小,是否小于等于阈值(原子任务的大小,这个由你自己来规定)。如果足够小,则无法再进行拆分,直接for循环累加计算然后返回;如果大于阈值(这里是2),则异步fork(线程)出子任务,继续递归调用compute方法,然后执行join,等待子任务执行完毕,并得到执行结果返回。
5、源码解读
Fork
fork():
public final ForkJoinTask<V> fork() {
Thread t;
if ((t = Thread.currentThread()) instanceof ForkJoinWorkerThread)
((ForkJoinWorkerThread)t).workQueue.push(this);
else
ForkJoinPool.common.externalPush(this);
return this;
}
fork方法内部会先判断当前线程是否是ForkJoinWorkerThread的实例,如果是,则将任务push到当前线程所维护的双端队列中。
那么我们来看看push方法。
ForkJoinPool push():
final void push(ForkJoinTask<?> task) {
ForkJoinTask<?>[] a; ForkJoinPool p;
int b = base, s = top, n;
if ((a = array) != null) { // ignore if queue removed
int m = a.length - 1; // fenced write for task visibility
U.putOrderedObject(a, ((m & s) << ASHIFT) + ABASE, task);
U.putOrderedInt(this, QTOP, s + 1);
if ((n = s - b) <= 1) {
if ((p = pool) != null)
p.signalWork(p.workQueues, this);//唤醒一个线程
}
else if (n >= m)
growArray();
}
}在push方法里核心的方法就是signalWork方法,它会唤醒或创建一个线程来异步执行当前的任务:
ForkJoinPool signalWork():
/**
* 尝试去创建或激活一个worker线程
*/
final void signalWork(WorkQueue[] ws, WorkQueue q) {
long c; int sp, i; WorkQueue v; Thread p;
while ((c = ctl) < 0L) { // too few active
if ((sp = (int)c) == 0) { // no idle workers
if ((c & ADD_WORKER) != 0L) // too few workers
tryAddWorker(c);//
break;
}
//....略过一些非核心代码
int vs = (sp + SS_SEQ) & ~INACTIVE; // next scanState
int d = sp - v.scanState; // screen CAS
long nc = (UC_MASK & (c + AC_UNIT)) | (SP_MASK & v.stackPred);
if (d == 0 && U.compareAndSwapLong(this, CTL, c, nc)) {
v.scanState = vs; // 激活一个存在的线程 v
if ((p = v.parker) != null)
U.unpark(p);
break;
}
if (q != null && q.base == q.top) // no more work
break;
}
}Join
public final V join() {
int s;
if ((s = doJoin() & DONE_MASK) != NORMAL)
reportException(s);
return getRawResult();
}如果doJoin返回的状态不是NORMAL,则记录异常:
private void reportException(int s) {
if (s == CANCELLED)
throw new CancellationException();
if (s == EXCEPTIONAL)
rethrow(getThrowableException());
}如果状态是CANCELED,则抛出CancellationException。如果是EXCEPTIONAL,则把此异常原模原样抛出即可。
来看看doJoin方法:
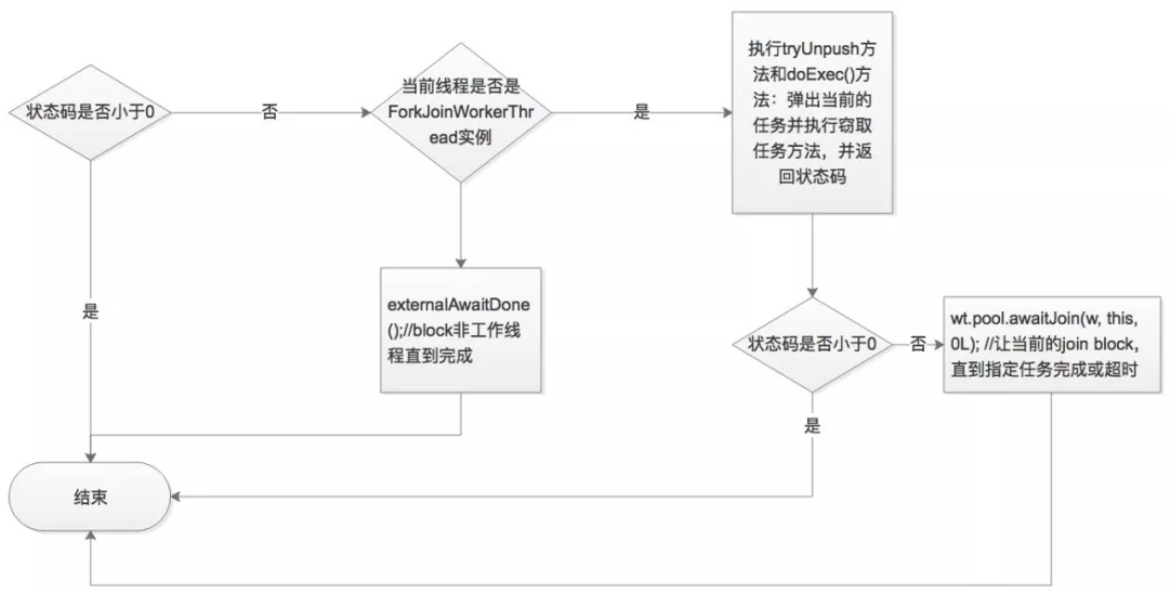
private int doJoin() {
int s; Thread t; ForkJoinWorkerThread wt; ForkJoinPool.WorkQueue w;
return (s = status) < 0 ? s :
((t = Thread.currentThread()) instanceof ForkJoinWorkerThread) ?
(w = (wt = (ForkJoinWorkerThread)t).workQueue).
tryUnpush(this) && (s = doExec()) < 0 ? s :
wt.pool.awaitJoin(w, this, 0L) :
externalAwaitDone();
}上面的return后的方法翻译成if else看着更直观一点:
if ((s = status) < 0) {
return s;
} else {
if (t = Thread.currentThread()) instanceof ForkJoinWorkerThread){
if (w = (wt = (ForkJoinWorkerThread) t).workQueue).
tryUnpush(this) && (s = doExec()) < 0){
return s;
}else{
return wt.pool.awaitJoin(w, this, 0L); //让当前的join block,直到指定任务完成或超时
}
}else{
return externalAwaitDone();//block非工作线程直到完成
}
}doJoin方法流程图:















 158
158

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









