






在Java语言中,Java语言的设计者对常用的数据结构和算法做了一些规范(接口)和实现(具体实现接口的类)。所有抽象出来的数据结构和操作(算法)统称为Java集合框架(JavaCollectionFramework)。
Java程序员在具体应用时,不必考虑数据结构和算法实现细节,只需要用这些类创建出来一些对象,然后直接应用就可以了,这样就大大提高了编程效率。
概述
- 什么是框架?
类库的集合
- 什么是集合?
存放数据的容器
- 集合框架用来干什么?
用来表示和操作的统一的架构
集合框架包含了两部分:一部分是类,一部分是接口(用来规范相似功能的类)
主要结构图:
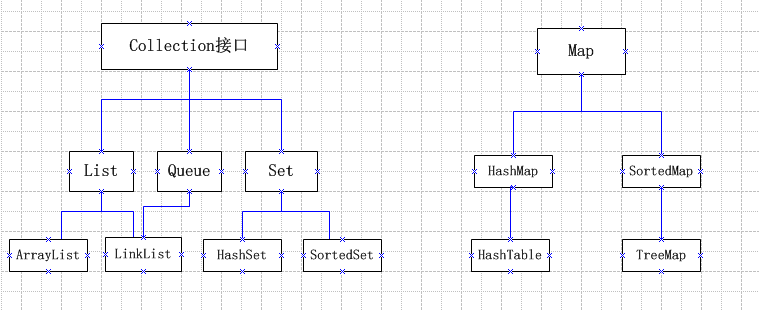
Java集合工具包位于Java.util包下,包含了很多常用的数据结构,如数组、链表、栈、队列、集合、哈希表等。
Java集合框架的使用重点:List列表、Set集合、Map映射、迭代器(Iterator、Enumeration)、工具类(Arrays、Collections)。
Collection
Collection是List、Set等集合高度抽象出来的接口,它包含了这些集合的基本操作,实现该接口及其子接口的所有类都可应用clone()方法,并是序列化类。
主要实现关系层次图:
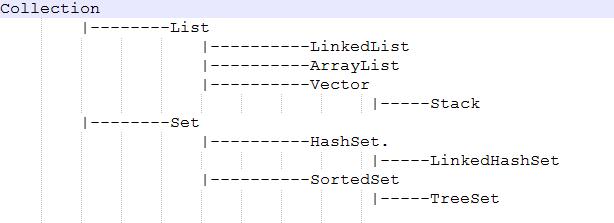
Collection的常用方法:
- 添加
boolean add(E e);
boolean addAll(Collection<> c) - 删除
boolean remove(E e);
boolean removeAll(Collection<> c) ;
void clear(); - 判断
boolean contains(Object o)
boolean containsAll(Collection<> c)
boolean isEmply(); - 获取
int size();
Iterator iterator(); - 其他
boolean retainAll(Collection coll);
Object[] toArray();
List
List接口通常表示一个列表,可随机访问包含的元素,元素是有序的,可在任意位置增、删元素,不管访问多少次,元素位置不变,允许重复元素。
用Iterator实现单向遍历,也可用ListIterator实现双向遍历。
List特有的常见方法:
- 添加
void add(index,element);
void add(index,collection); - 删除
Object remove(index); - 获取
Object get(index);
int indexOf(object);
int lastIndexOf(object);
Last subList(from,to); - 修改
Object set(index,element);
LinkedList
内部是链表数据结构,随机访问很慢,增删操作很快,不耗费多余资源,允许null元素,非线程安全 .如果多个线程同时访问一个List,则必须自己实现访问同步。
List list = Collections.synchronizedList(new LinkedList(...));
ArrayList
内部是数组数据结构,元素顺序存储。新增元素改变List大小时,内部会新建一个数组,在将添加元素前将所有数据拷贝到新数组中 。随机访问很快,删除非头尾元素慢,新增元素慢而且费资源 。较适用于无频繁增删的情况,可增长数组,50%延长。比数组效率低,如果不是需要可变数组,可考虑使用数组,非线程安全。
Vector
另一种ArrayList,具备ArrayList的特性。所有方法都是线程安全的(双刃剑,和ArrayList的主要区别) 比ArrayList效率低。
Stack
LIFO的数据结构,Stack继承自Vector,也是同步的。
Set
通常表示一个集合,接口中的方法和Collection中的一致。是一个不允许重复元素的Collection,可以有一个空元素,不可随机访问包含的元素,只能用Iterator实现单向遍历,Set**不同步**。
HashSet
内部数据结构是哈希表(HashMap),元素是无序的,迭代访问元素的顺序和加入的顺序不同 .多次迭代访问,元素的顺序可能不同,非线程安全。
LinkedHashSet
基于HashMap和链表的Set实现,迭代访问元素的顺序和加入的顺序相同,多次迭代访问,元素的顺序不变。
SortedSet
加入SortedSet的所有元素必须实现Comparable接口,元素是有序的。
TreeSet
基于TreeMap实现的SortedSet,可以对Set集合中的元素进行排序,排序后按升序排列元素,非线程安全。
两种排序方式:
- 让元素自身具备比较功能,元素就需要实现Compareable方法覆盖compareTo方法。
- 让集合自身具备比较功能,定义一个类实现Comparator接口,覆盖compare方法。
Map
是一个映射接口,Map没有继承Collection接口,Map提供key到value的映射。一个Map中不能包含相同的key,每个key只能映射一个value。
抽象类AbstractMap通过适配器模式实现了Map接口中的大部分函数,TreeMap、HashMap、WeakHashMap等实现类都通过继承AbstractMap来实现,但不常用的HashTable直接实现了Map接口。
实现关系层次图:
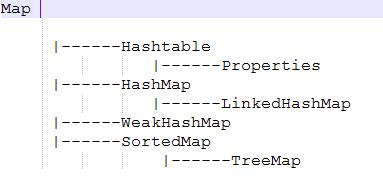
map中常用的方法:
- 添加
value put(key,value):返回前一个和key关联的值,如果没有则返回null - 删除
void clear():清空map集合。
value remove(key):根据指定的key删除这个键值对 - 判断
boolean containKey(key)
boolean containValue(value)
boolean isEmpty(); - 获取
value get(key);通过键获取值,如果没有该键返回null,当然可以通过返回null来判断是否包含指定键
int size()获取键值对个数。
取出Map集合中的所有值的方法:
- 通过keySet方法获取map中所有的键所在的Set集合,再通过Set的迭代器获取到每一个键,再对每一个键获通过map集合的get方法取其对应值即可。
Map map = new LinkedHashMap();
map.put("1", "第一个数");
map.put("2", "第二个数");
map.put("3", "第三个数");
for (Object obj : map.keySet()) {
String key = (String) obj;
String value = (String) map.get(key);
}
- 通过map集合的entryset方法也可取出map集合当中所有的键值对,返回的就是Map.Entry对象,再通过Map.Entry对象的getkey和getvalue方法就可以取出对应的键和值。
Map map = new LinkedHashMap();
map.put("1", "one");
map.put("2", "two");
map.put("3", "three");
for (Object obj : map.entrySet()) {
Entry entry = (Entry) obj;
String key = (String) entry.getKey();
String value = (String) entry.getValue();
}
- 通过Iterator遍历keySet或entryset
Map map = new HashMap();
map.put("1", "one");
map.put("2", "two");
map.put("3", "three");
Set set = map.keySet();
Iterator it = set.iterator();
while (it.hasNext()) {
String key = (String) it.next();
String value = (String) map.get(key);
}
Map map = new HashMap();
map.put("1", "one");
map.put("2", "two");
map.put("3", "three");
Set set = map.entrySet();
Iterator it = set.iterator();
while (it.hasNext()) {
Entry entry = (Entry) it.next();
String key = (String) entry.getKey();
String value = (String) entry.getValue();
}
Hashtable
用作键的对象必须实现了hashcode()、equals()方法,也就是说只有Object及其子类可用作键,Hashtable继承于Dictionary字典,实现Map接口。键、值都不能是空对象,多次访问,映射元素的顺序相同 ,线程安全。
Properties
继承于Hashtable,键和值都是字符串。
HashMap
内部结构是哈希表,键和值都可以是空对象,不保证映射的顺序,多次访问,映射元素的顺序可能不同,非线程安全。
LinkedHashMap
继承于HashMap ,多次访问,映射元素的顺序是相同的,性能比HashMap差。
WeakHashMap
当某个键不再正常使用时,垃圾收集器会移除它,即便有映射关系存在,非线程安全。
SortedMap
键按升序排列,所有键都必须实现Comparable接口。
TreeMap
内部结构是二叉树(基于红黑树实现),不同步,可以对Map集合中的键进行排序。
Iterator
Iterator是遍历集合的迭代器(不能遍历Map,只用来遍历Collection),Collection的实现类都实现了iterator()函数,它返回一个Iterator对象。
ListIterator则专门用来遍历List。
而Enumeration则是JDK1.0时引入的,作用与Iterator相同,但它的功能比Iterator要少,它只能在Hashtable、Vector和Stack中使用。
Arrays和Collections是用来操作数组、集合的两个工具类。
使用技巧
- 需要唯一用Set
且需要指定顺序:TreeSet
不需要:HashSet
得到与存储一致的顺序:LinkedHashSet - 不需要唯一用List
需要频繁增删动作用:LinkedList
不需要:ArrayList -
如果涉及到堆栈、队列等操作,应该考虑用List;
-
对于需要快速插入,删除元素,应该使用LinkedList;
-
如果需要快速随机访问元素,应该使用ArrayList。
-
如果程序在单线程环境中,或者访问仅仅在一个线程中进行,考虑非同步的类,其效率较高。
-
如果多个线程可能同时操作一个类,应该使用同步的类。 要特别注意对哈希表的操作,作为key的对象要正确复写equals和hashCode方法。 尽量返回接口而非实际的类型,如返回List而非ArrayList,这样如果以后需要将ArrayList换成LinkedList时,客户端代码不用改变,这就是针对抽象编程。
版权声明:请尊重个人劳动成果,转载注明出处,谢谢!
http://my.csdn.net/Amazing7















 127
127

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









