







Logstash是一款轻量级的日志搜集处理框架,可以方便的把分散的、多样化的日志搜集起来,并进行自定义的处理,然后传输到指定的位置,比如某个服务器或者文件。
下载后直接解压,就可以了。
通过命令行,进入到logstash/bin目录,执行下面的命令:
logstash -e ""可以看到提示下面信息(这个命令稍后介绍),输入hello world!
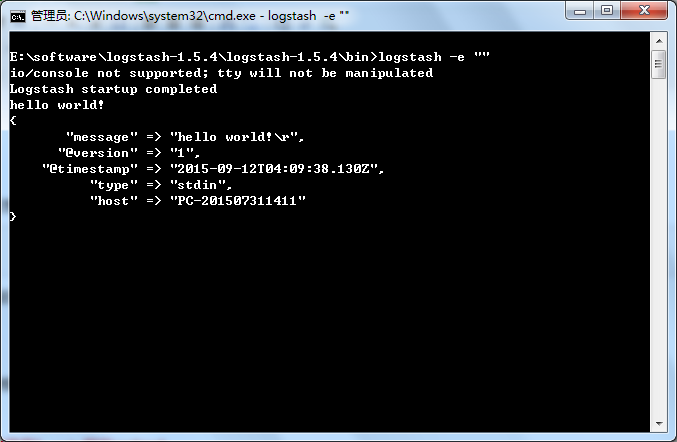
可以看到logstash尾我们自动添加了几个字段,时间戳@timestamp,版本@version,输入的类型type,以及主机名host。
工作原理
Logstash使用管道方式进行日志的搜集处理和输出。有点类似*NIX系统的管道命令 xxx | ccc | ddd,xxx执行完了会执行ccc,然后执行ddd。
在logstash中,包括了三个阶段:
输入input --> 处理filter(不是必须的) --> 输出output
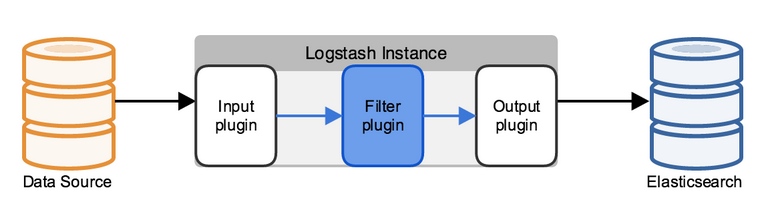
每个阶段都由很多的插件配合工作,比如file、elasticsearch、redis等等。
每个阶段也可以指定多种方式,比如输出既可以输出到elasticsearch中,也可以指定到stdout在控制台打印。
由于这种插件式的组织方式,使得logstash变得易于扩展和定制。
input 数据输入端,可以接收来自任何地方的源数据。
- file:从文件中读取
- syslog:监听在514端口的系统日志信息,并解析成RFC3164格式。
- redis:从redis-server list 中获取
- beat:接收来自Filebeat的事件
- 等等
Filter 数据中转层,主要进行格式处理,数据类型转换、数据过滤、字段添加,修改等,常用的过滤器如下。
- grok: 通过正则解析和结构化任何文本。Grok 目前是logstash最好的方式对非结构化日志数据解析成结构化和可查询化。logstash内置了120个匹配模式,满足大部分需求。
- mutate: 在事件字段执行一般的转换。可以重命名、删除、替换和修改事件字段。
- drop: 完全丢弃事件,如debug事件。
- clone: 复制事件,可能添加或者删除字段。
- geoip: 添加有关IP地址地理位置信息。
- 等等
output 是logstash工作的最后一个阶段,负责将数据输出到指定位置,兼容大多数应用,常用的有:
- elasticsearch: 发送事件数据到 Elasticsearch,便于查询,分析,绘图。
- file: 将事件数据写入到磁盘文件上。
- mongodb:将事件数据发送至高性能NoSQL mongodb,便于永久存储,查询,分析,大数据分片。
- redis:将数据发送至redis-server,常用于中间层暂时缓存。
- graphite: 发送事件数据到graphite。http://graphite.wikidot.com/
- statsd: 发送事件数据到 statsd。
- 等等
配置文件说明
前面介绍过logstash基本上由三部分组成,input、output以及用户需要才添加的filter,因此标准的配置文件格式如下:
input {...}
filter {...}
output {...}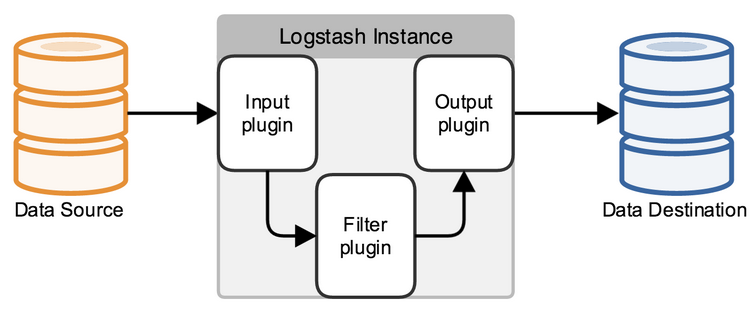
在每个部分中,也可以指定多个访问方式,例如我想要指定两个日志来源文件,则可以这样写:
input {
file { path =>"/var/log/messages" type =>"syslog"}
file { path =>"/var/log/apache/access.log" type =>"apache"}
}类似的,如果在filter中添加了多种处理规则,则按照它的顺序一一处理,但是有一些插件并不是线程安全的。
比如在filter中指定了两个一样的的插件,这两个任务并不能保证准确的按顺序执行,因此官方也推荐避免在filter中重复使用插件。
说完这些,简单的创建一个配置文件的小例子看看:
input {
file {
#指定监听的文件路径,注意必须是绝对路径
path => "E:/software/logstash-1.5.4/logstash-1.5.4/data/test.log"
start_position => beginning
}
}
filter {
}
output {
stdout {}
}日志大致如下:
hello,this is first line in test.log!
hello,my name is xingoo!
goodbye.this is last line in test.log!
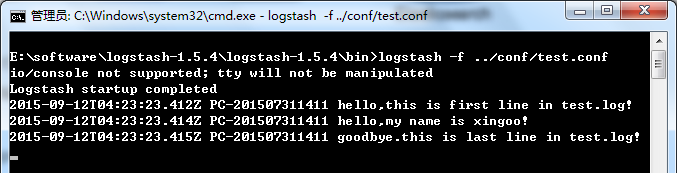
细心的会发现,这个日志输出与上面的logstash -e "" 并不相同,这是因为上面的命令默认指定了返回的格式是json形式。















 9808
9808

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









