






本节书摘来自异步社区《重构HTML:改善Web应用的设计(修订版)》一书中的第2章,第2.2节,作者: 【美】Elliotte Rusty Harold 更多章节内容可以访问云栖社区“异步社区”公众号查看。
2.2 验证器
即使没有人去遵守,这确实还是HTML的标准。判断网站是否遵守HTML标准的一种方法是,通过验证服务来运行页面。验证结果可以让人有所启发,为你提供修复的明确细节以及一个预估工作量的良好建议。
2.2.1 W3C标记验证服务
对于公开页面,可选的验证器是W的标记验证服务。只要输入需检查页面的URL,就可以看到结果了。图2-1是这个服务验证我博客的一个示例。

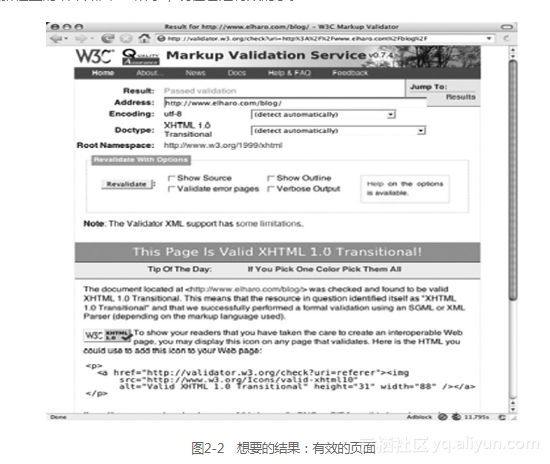
看起来是我记错了blockquote元素的语法,错把cite当做source属性了。这个服务比我想象中的要好。我修正后重新检查的结果如图2-2所示,现在它是有效的了。
通常没有必要检查网站的每个页面,因为大部分的错误都是重复的。一般来说,一旦你确定了某种错误,就有可能找到源头并自动修正问题。比如,上面的例子我只要简单地在其他页面搜索
这个页面现在比刚开始的要更清晰了。接着我检查了一个我所能找到最古老的、很少维护的页面,它产生了144个不同的错误。
私密验证
W诚然可信,但你并不想把内部的私密网页提交到W上。实际上,处理医学、财务和其他私人数据时,这样做可能是违法的。
这种形式的验证对编写是有利的,对于网站的抽查以确定可能的工作量也很有用,即使是单一的页面。但在某种程度上,你必须检查网站的所有页面而不只是少数的几页。因此,自动化的批处理的验证器就显得很有必要了。2.2.2 日志验证程序
W标记验证服务促使了日志验证程序(Log Validator)的诞生,它是一个用Perl写的命令行工具,用于检查整个网站。它还可以使用Web服务器的日志文件算出最流行的页面,并从这些页面开始分析。显然,与一年100次点击量的页面相比,你会更在意一个每分钟100次单击的页面。日志验证程序为你提供方便的待修复问题清单,并以页面的严重性和流行性排序。代码清单2-1显示了这样一份记录清单的开头部分。代码清单2-1 日志验证程序的输出结果 Results for module HTMLValidator **************************************************************** Here are the 10 most popular invalid document(s) that I could find in the logs for www.elharo.com. Rank Hits #Error(s) Address ------ ------ ----------- ------------------------------------- 1 2738 21 http://www.elharo.com/blog/feed/atom/ 2 1355 21 http://www.elharo.com/blog/feed/ 3 1231 3 http://www.elharo.com/blog/ 4 1127 6 http://www.elharo.com/ 6 738 3 http://www.elharo.com/blog/networks /2006/03/18/looking-for-a-router/feed/ 11 530 3 http://www.elharo.com/journal /fruitopia.html 20 340 1 http://www.elharo.com/blog /wp-comments-post.php 23 305 3 http://www.elharo.com/blog/birding /2006/03/15/birding-at-sd/ 25 290 4 http://www.elharo.com/journal /fasttimes.html 26 274 1 http://www.elharo.com/journal/这份输出清单中前两个页面属于Atom feed文档而非HTML文件,因此可以置之不理。但访问量排行第3和第4的页面就棘手了,因为它们分别是我的博客主页和网站主页,因此毫无疑问需要修复问题。因为访问量排行第5的页面是有效的,所以没有在这份清单中显示出来。访问量排行第11、25和26的页面是XML前的页面,不属于XHTML。它们无效并不奇怪,但因为它们仍有点击量,所以也是需要修复的。
访问量排行第20的页面也肯定有一处错误,不过那是用于发表评论的一个脚本罢了。当验证器试图对它使用方法GET而不是POST时,它接收到的只能是一个空白页面。虽然不是一个大问题,但或许我需要给GET一个完整的评论清单来修复它。或者我更应该简单地配置这个脚本返回HTTP error 405 Method Not Allowed,而不是依赖于200 OK和一个空白文档。
之后就是那些流量不是很大的各个页面了。从顶部开始,并顺路往下开始工作吧。
2.2.3 xmllint
你也可以使用通用的XML验证器,比如xmllint,它在很多UNIX机器上都默认安装,也可以在Windows平台上使用。使用通用的XML验证器检查HTML既有优点,也有缺点。优点是可以把良构检查与有效性检查相互分离。通常,先修复良构问题,再去修复有效性问题更容易。实际上这也是本书的组织顺序。良构比有效性更重要。
使用普通XML验证器的第一个不足是,它不会捕捉HTML特定的问题,这些问题在DTD中没有规定得特别清楚。比如,它不会注意到a元素嵌套到另一个a元素的问题(尽管在实践中这个问题不是很常见)。第二个不足是它必须实际地读取DTD,不会设想它所检查文档的任何东西。
使用xmllint检查良构是非常简单的事,只需在命令行中指出需要检查的本地文件的地址或远程文件的URL。使用--noout选项指定不打印文档自身,而使用--loaddtd则允许解析实体引用。比如:
$ xmllint --noout --loaddtd http://www.aw.com http://www.aw-bc.com/:118: parser error : Specification mandate value for attribute nowrap <TD class="headerBg" bgcolor="#99" nowrap align="left"> ^ http://www.aw-bc.com/:118: parser error : attributes construct error <TD class="headerBg" bgcolor="#99" nowrap align="left"> ^ http://www.aw-bc.com/:118: parser error : Couldn't find end of Start Tag TD line 118 <TD class="headerBg" bgcolor="#99" nowrap align="left"> ^ http://www.aw-bc.com/:120: parser error : Opening and ending tag mismatch: IMG line 120 and A Benjamin Cummings" WIDTH="84" HEIGHT="64" HSPACE="0" VSPACE="0" BORDER="0"></A> ...在第一次运行这样的报表时,错误信息的数量往往使人气馁。千万不要认输——从头开始,逐一解决。大部分的错误都可归类为某种常见的分类中,本书稍后会讨论到,所以你可以一起解决它们。比如在这个例子中,第一个错误是nowrap属性缺少相应的值。你可以通过搜索nowrap并替换为nowrap="nowrap"轻易搞定。实际上通过多文件的搜索和替换,修复整个网站也不过5分钟。(本章后面我会给出更具体的细节。)
修改完后再次运行验证器。每进行一次修改,你看到的错误应该会更少,尽管偶尔会出现新的错误。简单地重复这个过程,直到消灭所有的良构错误。接下来的问题是,img元素使用的是起始标签(start-tag)而不是空元素标签(empty-element tag)。虽然这是个麻烦的标签,但也可以通过搜索BORDER="0">并替换为border="0"/>修复大部分问题。虽然不能找出img元素的所有问题,但确实可以修复大量类似的问题。
从清单中的第一个错误而不是随机挑一个错误着手修复是非常重要的。通常一个先出现的错误会导致更多的良构问题,忽略起始标签或结束标签引起的问题更是如此。修复先出现的错误往往可以免除后续的错误。
实现良构后,接着是检查有效性。只需在命令行加上--valid选项,比如:
$xmllint –noout –loaddtd –valid valid_aw.html
这很可能会显示更多需要检查和修复的错误,尽管通常都是些小问题。但基本的解决方法还是一样的:从顶端开始顺路而下,直到解决所有的问题。2.2.4 编辑器
很多HTML编辑器都有内置的页面验证支持。比如,在BBEdit中,你可以到Markup菜单项上选择Check/Document Syntax来验证正在编辑的页面;在Dreamweaver中,可以使用右键菜单中的Validate Current Document选项(不过要确保验证器设置为XHTML而非HTML)。从本质上说,这些工具只不过是通过如xmllint这样的解析器来检查文档是否有问题。
如果你使用的是Firefox,应该安装Chris Pederick的Web Developer插件。这样,你就可以通过Tools/Web Developer/Tools/Validate HTML菜单项快速验证任何页面了,它会把当前页面载入W验证器中。另外这个插件还提供了大量的有用选项。
无论你使用哪一种工具和技术来搜索标记错误,验证都是向XHTML重构的第一步。如果能看到问题之所在,那么问题已经解决了一半















 1231
1231











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









