







监控分布式应用本来就是一个困难的事情,每个线程每个任务都在随机的硬件实例上执行,茫茫多的日志,有意设计的Failure Tolerance 都使定位、debug一个问题变得不太可能。
最近为了监控akka项目引入了Kamon以及相关的技术栈:
- Kamon: 在应用程序中使用;
- statsd:收集监控信号
- Graphite:存储监控信息的时序数据库
- Grafana:图形化监控结果
#Kamon Kamon是一个在jvm之上运行的监控程序运行的库。Kamon专注于集成Typesafe旗下的框架和scala语言,但事实上只要是JVM之上的程序都能用。
Kamon中用户既可以创建自己的metrics,也可以通过AspectJ获得Kamon已做好的几个流行的框架/库里的监测信息。Kamon支持的这样的框架有:
- AKKA
- Spray
- Play Framework
- JDBC
###非常容易上手
- sbt/maven 安装
- 修改配置文件
- 主程序中Kamon.start()
AKKA集成
Kamon通过两个module来集成akka:
- kamon-akka
- kamon-akka-remote:允许远程/分布式的情况下保持TraceContext
__TraceContext__用来保持程序运行过程中的更多调用细节。比如"发帖"和"获取文章列表"两个功能都要使用"获取用户详情"的方法,则单独监控"获取用户详情"方法是不够的。 we refer to the invocation of a functionality as a Trace and to each of the components being used to make up the trace as Segments. Each request to “post new status” is generating a new trace, and, each usage of the “get user details” section is a segment that belongs to the aforementioned trace. All the information related to a trace is stored in a single TraceContext instance.
获取Actor、dispatcher和route的metrics以及TraceContext是基本不需要写代码的。在配置文件中做类似这样的配置即可:
kamon.metric.filters {
akka-actor {
includes = ["Arachne/user/**"]
excludes = ["Arachne/system/**"]
}
akka-dispatcher {
includes = [
"Arachne/akka.actor.default-dispatcher", "Arachne/akka.actor.fetcher-dispatcher", "Arachne/akka.actor.preparse-filter-dispatcher"
]
}
akka-router {
includes = ["Arachne/user/**"]
}
}
Include里面写的都是Akka的actor path,ActorPath和ActorRef的关系可见下图: 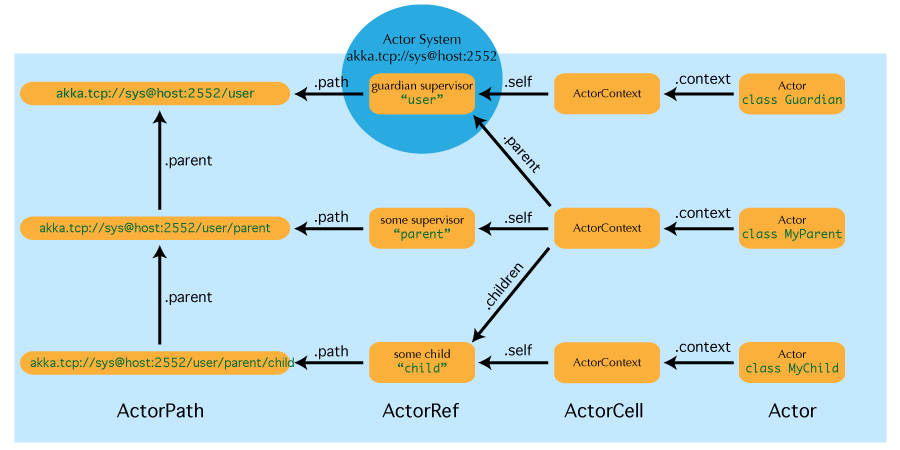 Kamon可获取的Metric就不列了,比较常见的有如消息处理的时间和消息在mailbox中的堆积。
Kamon可获取的Metric就不列了,比较常见的有如消息处理的时间和消息在mailbox中的堆积。
#Statsd 在监控数据统计中类似于logstash的角色,经UDP协议接收监控数据,聚集,并发给下一个应用。比如说一个Counter,他就会把10秒内该Counter累加的值,发送到后端。比如Time/Timing,他会把次数、最大值、最小值、平均值发往后端。所有的数据都是以10秒为一个周期的。
#Graphite/InfluxDB Graphite和InfluxDB类似于ELK中Elasticsearch的角色,负责存储和pivot数据。相比之下,Graphite/InfluxDB应该算作"Time Series DBMS" 而不是搜索引擎,其更注重于大量数字数据的统计信息,而不是每个文档/记录。
| Elasticsearch | Graphite/InfluxDB |
|---|---|
| 适合以分类建模 | 适合以数字建模 |
| 文档 | 大量的以时间间隔的数字,字符串(InfluxDB) |
| 信息之间的关系可以使用query来确定 | 信息之间有定义 |
| 非结构化的模型 | 模型之间的关系可以预先定义 |
时序化数据库是个很有意思的话题,现在最流行的三个产品是InfluxDB,RRDtool和Graphite,以后再聊。 
#Grafana 在监控数据统计中类似于Kibana的角色,和Kibana的主要区别有:
- 所有图标都是基于时间轴的;
- 不支持数据查询;
- 有访问权限系统;















 3177
3177

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









