





HDFS和MapReduce是Hadoop的两大核心。
整个Hadoop体系结构主要是通过HDFS来实现分布式存储的底层支持的,而且通过MapReduce来实现分布式并行任务处理的程序支持。
一、HDFS体系结构
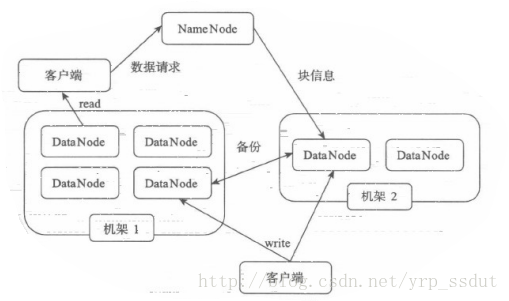
HDFS採用了主从(Master/Slave)结构模型。一个HDFS集群是由一个NameNode和若干个DataNode组成的。当中,NameNode作为主server。管理文件系统的命名空间和client对文件的訪问操作;集群中的DataNode管理存储的数据。HDFS典型的部署是在一个专门的机器上执行NameNode,集群中的其它机器各执行一个DataNode。也能够在执行NameNode的机器上同一时候执行DataNode。或者一台机器上执行多个DataNode。
一个集群仅仅有一个NameNode的设计大大简化了系统架构。
从终于用户的角度来看,它就像传统的文件系统一样。能够通过文件夹路径对文件运行CRUD(Create/Read/Update/Delete)操作。
NameNode管理文件系统的元数据,DataNode存储实际的数据。
client通过同NameNode和DataNodes交互訪问文件系统。client联系NameNode以获取文件的元数据,而真正的文件I/O操作时直接和DataNode进行交互的。
下图为HDFS体系结构:
文件写入(Orclient文件上传):
1、Client向NameNode发起文件写入的请求。
2、NameNode依据文件大小和文件块配置情况,返回给Client它所管理部分DataNode的信息。3、Client将文件划分为多个Block,依据DataNode的地址信息,按顺序写入到每个DataNode块中。
文件读取:
1、Client向NameNode发起文件读取的请求。
2、NameNode返回文件存储的DataNode的信息。
3、Client读取文件信息。
client:将文件切分为block依次上传;与NameNode交互获取文件位置信息。与DataNode交互读取或者写入文件。管理和訪问HDFS
二、MapReduce体系结构
MapReduce是一种并行编程模式,利用这样的模式软件开发人员能够轻松编写出分布式并行程序。在Hadoop体系结构中,MapReduce是一个简单易行的软件框架。基于它能够将任务分发到由上千台商用机器组成的集群上,并以一种可靠容错的方式并行处理大量数据集,实现Hadoop并行任务处理能力。
MapReduce框架是由一个单独执行在主节点的JobTracker和执行在每一个集群从节点的TaskTracker共同组成的。主节点负责调度构成一个作业的全部任务,这些任务分布在不同的从节点上。
主节点监控他们的执行情况,而且又一次执行之前失败的任务;从节点仅负责由主节点指派的任务。
当一个Job被提交时,JobTracker接收到提交作业和其配置信息之后,就会将配置信息等分发给从节点,同一时候调度任务并监控TaskTracker的运行
兴许会不断完好补充……
Hadoop学习笔记(一)——Hadoop体系结构
最新推荐文章于 2024-07-13 14:51:19 发布

















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









