






背景
在实际项目中,利用深度学习在检测道路车辆并分析车辆行为时,需要按照事先规定的方法绘制检测区(包含道路方向、车道区域等)。由于各种原因(人为、天气),获取视频数据的摄像角度容易偏移原来设定的位置,造成检测区域和实际画面不匹配,系统容易产生误检误报等错误数据。因此需要在摄像机位置偏移第一时间告诉系统检测模块停止工作,直到摄像机归位后再进行检测。摄像机角度偏移告警属于‘视频诊断’中的一类,本文利用提取图片特征点实现摄像机偏移告警,demo全部python代码不足200行。

前面有几篇博客文字太少,发不了首页:
这里是[AI+计算机视觉]的所有文章,需要的朋友可以点一波关注或者收藏一下。
图像特征点
对于任何一张二维图片,从像素级别上看,都存在一些我们肉眼看不到的比较独特的像素单元(可以理解为像素块),就像我们每个人的脸都会与众不同一样,我们称这些具有特点的像素区域为“图像特征点”。已经有非常成熟的算法来提取图片的特征点:
(1)Harris:用于检测角点;
(2)SIFT:用于检测斑点;
(3)SURF:用于检测斑点;
(4)FAST:用于检测角点;
(5)BRIEF:用于检测斑点;
(6)ORB:表示带方向的FAST算法与具有旋转不变性的BRIEF算法;
详细算法原理上网搜一下(我也不是很清楚:)),OpenCV中包含以上几种算法实现。
角点:
图像中涉及到拐角的区域,比如物体有轮廓,图像中的物体有边缘区分。
斑点:
一块有特别规律的像素区域。
方向、尺寸不变性:
指特征点不会受图片尺寸、旋转而改变,比如同一张图,你缩小一倍旋转90度后,特征点还是一样的。
图像匹配
提取两张图片的特征点,然后将这些特征点进行匹配关联。如果匹配程度满足某一阈值,则认为这两张图满足匹配条件。注意,对于同一个物体,拍摄角度不同,亮度不同都应该满足匹配条件。
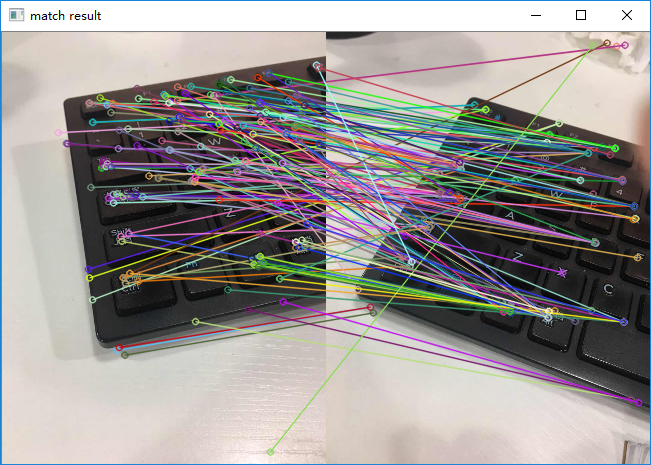
可以看到,对于同一个场景的不同拍摄角度的两张图片,能找到匹配到的特征点,但是误差非常大。我们设置一个阈值,满足该条件才认为两个点匹配:
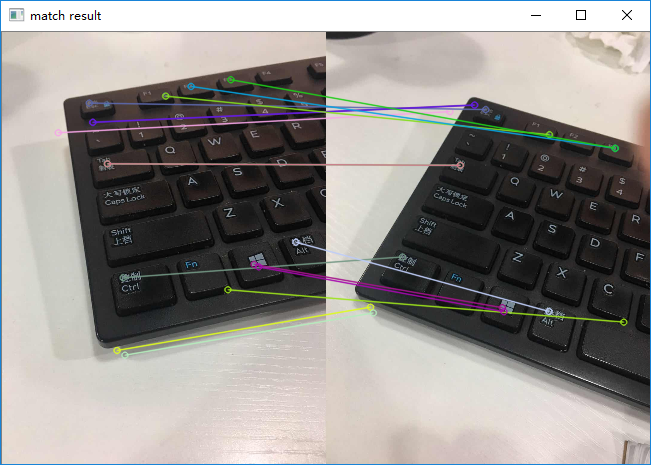
误差少很多了,匹配到的特征点也非常正确。
换一组摄像机的照片,前一张和后一张在拍摄时,摄像机角度往左下角有偏移,所以对应匹配到的特征点往右上方移动了:

我们可以看到,虽然拍摄角度不同,但是由于场景类似,仍然能匹配到特征点(为了减少绘图方便看清楚,阈值设置非常严格,如果放宽一点还能看到更多匹配到的点),而且这些匹配到的点几乎都正确。对于两张完全不同的场景照片,匹配到的特征点非常少或者为零(具体看设置的阈值)

场景不同,匹配到的特征点只有视频上的文字。
角度偏移告警
如果摄像机位置不变,前后拍摄两张照片,那么这两张照片匹配到的特征点的二维物理坐标应该是一样的(可能有轻微偏移,两张照片尺寸一致)。那么我们可以根据摄像机前后两帧(或间隔时间内取得的两帧)的匹配点物理位置是否有偏移,设置一个偏移阈值,大于该阈值时则认为偏移,否则认为没偏移(或轻微偏移),当然,如果两帧匹配到的特征点非常少(低于一个阈值),那么我们认为这俩帧完全不一样了(场景不一样了),这时候摄像机完全偏移了原来的角度。
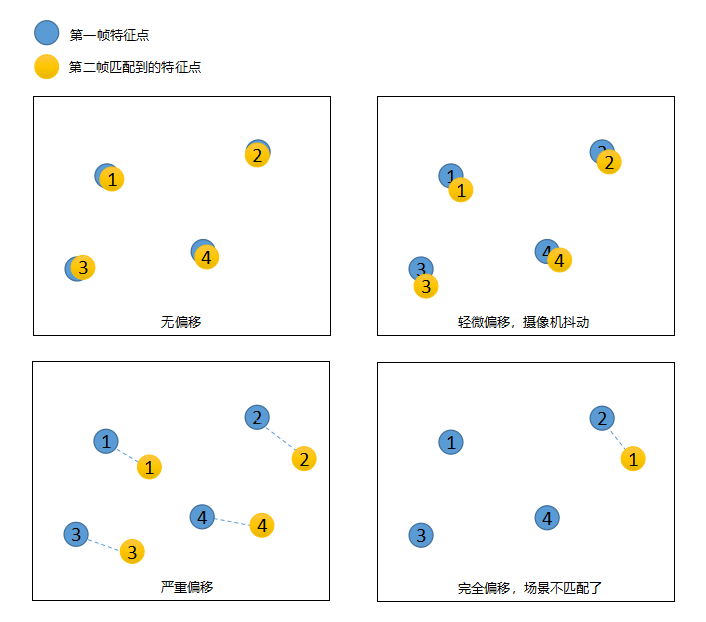
注意点:
1)阈值非常重要;
2)前后帧匹配时,要去掉类似摄像机自动加上去的“视频位置”、“当前时间”等等区域,因为这些区域很多时候能够匹配到特征点,并且物理位置坐标不会发生变化,造成误差;
3)在计算特征点物理位置偏移量时,取所有特征点物理位置偏移的平均值。
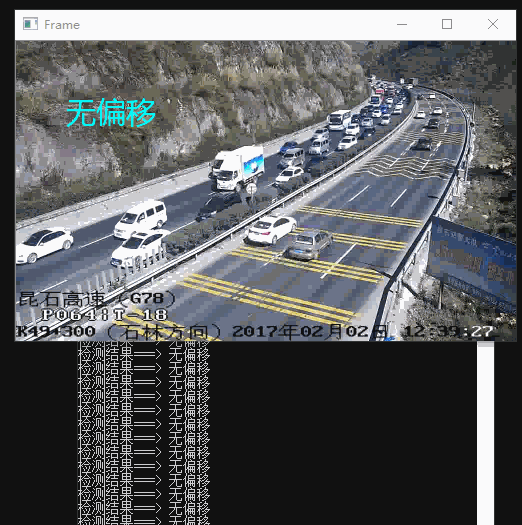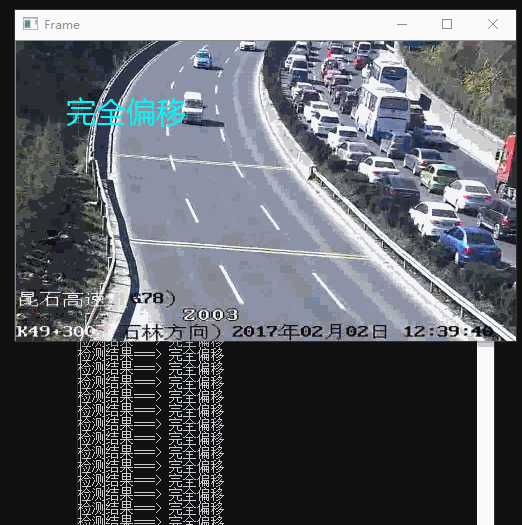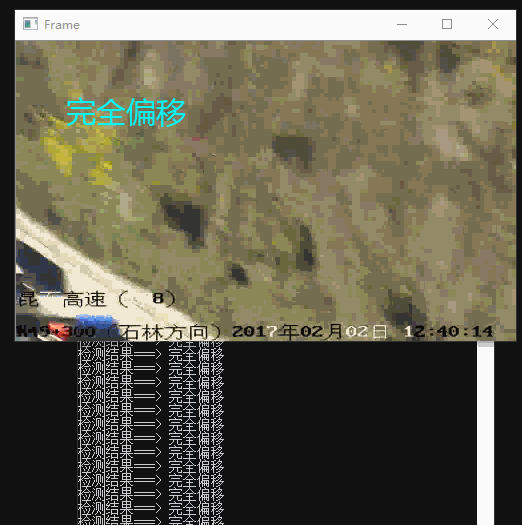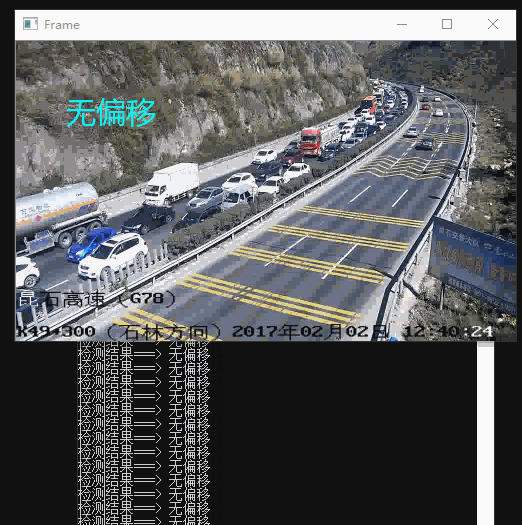
最终效果
间隔时间取视频中的帧,进行特征点对比。根据前面的思路分为4个等级:“无偏移”、“轻度偏移(抖动)”、“严重偏移”、“完全偏移”。
源代码
最重要的是代码,很简单,直接贴上来即可。加起来不到160行。测试很多场景,效果都不错。
1 ''' 2 视频帧匹配脚本 3 ''' 4 import numpy as np 5 import cv2 6 7 #至少10个点匹配 8 MIN_MATCH_COUNT = 10 9 #完全匹配偏移 d<4 10 BEST_DISTANCE = 4 11 #微量偏移 4<d<10 12 GOOD_DISTANCE = 10 13 14 15 # 特征点提取方法,内置很多种 16 algorithms_all = { 17 "SIFT": cv2.xfeatures2d.SIFT_create(), 18 "SURF": cv2.xfeatures2d.SURF_create(8000), 19 "ORB": cv2.ORB_create() 20 } 21 22 ''' 23 # 图像匹配 24 # 0完全不匹配 1场景匹配 2角度轻微偏移 3完全匹配 25 ''' 26 def match2frames(image1, image2): 27 img1 = cv2.cvtColor(image1, cv2.COLOR_BGR2GRAY) 28 img2 = cv2.cvtColor(image2, cv2.COLOR_BGR2GRAY) 29 30 size1 = img1.shape 31 size2 = img2.shape 32 33 img1 = cv2.resize(img1, (int(size1[1]*0.3), int(size1[0]*0.3)), cv2.INTER_LINEAR) 34 img2 = cv2.resize(img2, (int(size2[1]*0.3), int(size2[0]*0.3)), cv2.INTER_LINEAR) 35 36 sift = algorithms_all["SIFT"] 37 38 kp1, des1 = sift.detectAndCompute(img1, None) 39 kp2, des2 = sift.detectAndCompute(img2, None) 40 41 FLANN_INDEX_KDTREE = 0 42 index_params = dict(algorithm = FLANN_INDEX_KDTREE, trees = 5) 43 search_params = dict(checks = 50) 44 45 flann = cv2.FlannBasedMatcher(index_params, search_params) 46 47 matches = flann.knnMatch(des1, des2, k=2) 48 49 # 过滤 50 good = [] 51 for m,n in matches: 52 if m.distance < 0.7*n.distance: 53 good.append(m) 54 55 if len(good) <= MIN_MATCH_COUNT: 56 return 0 # 完全不匹配 57 else: 58 distance_sum = 0 # 特征点2d物理坐标偏移总和 59 for m in good: 60 distance_sum += get_distance(kp1[m.queryIdx].pt, kp2[m.trainIdx].pt) 61 distance = distance_sum / len(good) #单个特征点2D物理位置平均偏移量 62 63 if distance < BEST_DISTANCE: 64 return 3 #完全匹配 65 elif distance < GOOD_DISTANCE and distance >= BEST_DISTANCE: 66 return 2 #部分偏移 67 else: 68 return 1 #场景匹配 69 70 71 ''' 72 计算2D物理距离 73 ''' 74 def get_distance(p1, p2): 75 x1,y1 = p1 76 x2,y2 = p2 77 return np.sqrt((x1-x2)**2 + (y1-y2)**2) 78 79 80 if __name__ == "__main__": 81 pass
测试
1 ''' 2 摄像机角度偏移告警 3 ''' 4 import cv2 5 import do_match 6 import numpy as np 7 from PIL import Image, ImageDraw, ImageFont 8 9 ''' 10 告警信息 11 ''' 12 def putText(frame, text): 13 cv2_im = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB) 14 pil_im = Image.fromarray(cv2_im) 15 16 draw = ImageDraw.Draw(pil_im) 17 font = ImageFont.truetype("fonts/msyh.ttc", 30, encoding="utf-8") 18 draw.text((50, 50), text, (0, 255, 255), font=font) 19 20 cv2_text_im = cv2.cvtColor(np.array(pil_im), cv2.COLOR_RGB2BGR) 21 22 return cv2_text_im 23 24 25 26 27 texts = ["完全偏移","严重偏移", "轻微偏移", "无偏移"] 28 29 cap = cv2.VideoCapture('videos/test4_new.mp4') 30 31 if (cap.isOpened()== False): 32 print("Error opening video stream or file") 33 34 first_frame = True 35 pre_frame = 0 36 37 index = 0 38 39 while(cap.isOpened()): 40 ret, frame = cap.read() 41 if ret == True: 42 if first_frame: 43 pre_frame = frame 44 first_frame = False 45 continue 46 47 index += 1 48 if index % 24 == 0: 49 result = do_match.match2frames(pre_frame, frame) 50 print("检测结果===>", texts[result]) 51 52 if result > 1: # 缓存最近无偏移的帧 53 pre_frame = frame 54 55 size = frame.shape 56 57 if size[1] > 720: # 缩小显示 58 frame = cv2.resize(frame, (int(size[1]*0.5), int(size[0]*0.5)), cv2.INTER_LINEAR) 59 60 text_frame = putText(frame, texts[result]) 61 62 cv2.imshow('Frame', text_frame) 63 if cv2.waitKey(1) & 0xFF == ord('q'): 64 break 65 else: 66 break 67 68 cap.release() 69 cv2.destroyAllWindows()















 3459
3459











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









