







一、hive的基本概念与原理
Hive是基于Hadoop之上的数据仓库,可以存储、查询和分析存储在 Hadoop 中的大规模数据。Hive 定义了简单的类 SQL 查询语言,称为 HQL,它允许熟悉 SQL 的用户查询数据,允许熟悉 MapReduce 开发者的开发自定义的 mapper 和 reducer 来处理内建的 mapper 和 reducer 无法完成的复杂的分析工作。Hive 没有专门的数据格式。
hive的访问方式: 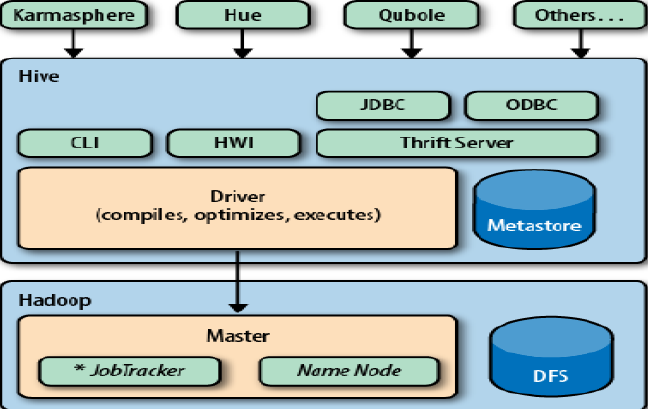
hive的执行原理:
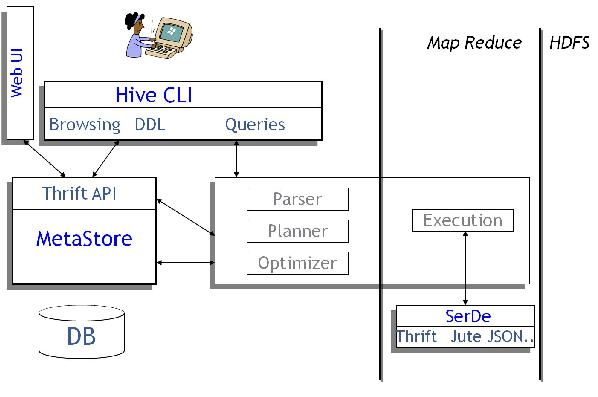
二、hive的常用命令
连接进入hive:hive
删除数据库:drop database if exists qyk_test cascade;如下图: 
然后,我们使用create database qyk_test;创建一个qyk_test的数据库,如下: 
接下来,我们执行create table user_info(id bigint, account string, name string, age int) row format delimited fields terminated by ‘\t’;创建一张表,如下:
我们可以执行describe user_info;查看表结构,如下: 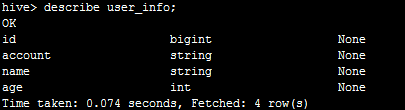
然后,我们使用create table user_info_tmp like user_info;创建一个和user_info一样结构的临时表,如下: 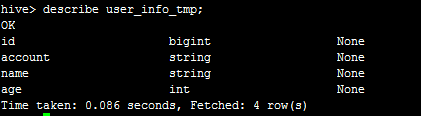
然后我们准备一个文件user_info.txt,以制表符分隔,如下

11 1200.0 qyk1 21
22 1301 qyk2 22
33 1400.0 qyk3 23
44 1500.0 qyk4 24
55 1210.0 qyk5 25
66 124 qyk6 26
77 1233 qyk7 27
88 15011 qyk8 28- 1
接下来执行load data local inpath ‘/tmp/user_info.txt’ into table user_info;可看到如下:
然后执行select * from user_info;可看到: 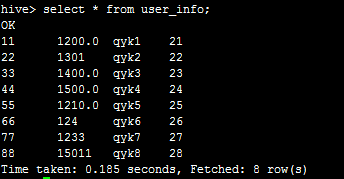
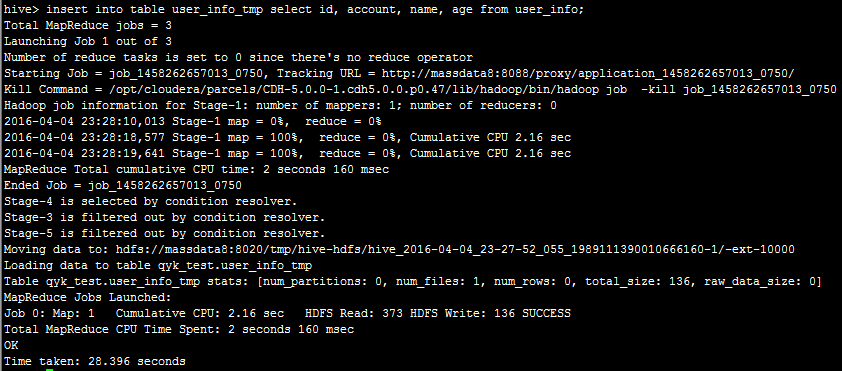
然后,我们执行insert into table user_info_tmp select id, account, name, age from user_info;可以看到:
这里,hive将此语句的执行转为MR,最后将数据入到user_info_tmp。
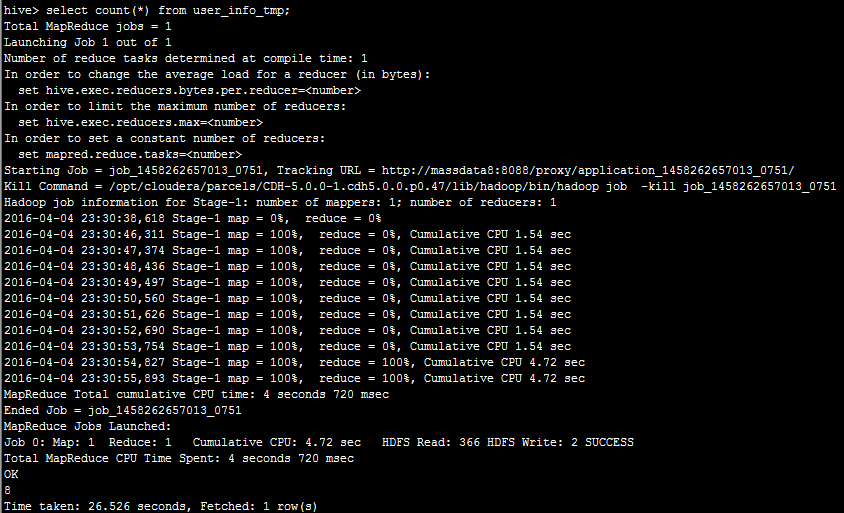
然后,我们执行select count(*) from user_info_tmp;可看到:
同样的是将sql转为mr执行。
最后,执行insert overwrite table user_info select * from user_info where 1=0;清空表数据。
执行drop table user_info_tmp;便可删除表,如下: 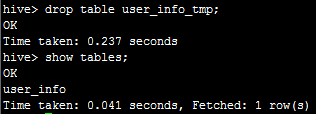
好了,基本命令就讲到这儿,关于外部表、分区、桶以及存储格式相关的概念大家也可以去研究下。

三、编写MR将数据直接入到hive
此MR只有Mapper,没有reducer。直接在mapper输出到hive表。
pom需新增依赖:
<!-- hcatalog相关jar -->
<dependency>
<groupId>org.apache.hive.hcatalog</groupId>
<artifactId>hive-hcatalog-core</artifactId>
<version>${hive.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hive.hcatalog</groupId>
<artifactId>hive-hcatalog-hbase-storage-handler</artifactId>
<version>${hive.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hive.hcatalog</groupId>
<artifactId>hive-hcatalog-server-extensions</artifactId>
<version>${hive.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hive.hcatalog</groupId>
<artifactId>hive-hcatalog-pig-adapter</artifactId>
<version>${hive.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hive.hcatalog</groupId>
<artifactId>hive-webhcat-java-client</artifactId>
<version>${hive.version}</version>
</dependency>Mapper类:
/**
* Project Name:mr-demo
* File Name:HiveStoreMapper.java
* Package Name:org.qiyongkang.mr.hivestore
* Date:2016年4月4日下午10:02:07
* Copyright (c) 2016, CANNIKIN(http://http://code.taobao.org/p/cannikin/src/) All Rights Reserved.
*
*/
package org.qiyongkang.mr.hivestore;
import java.io.IOException;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hive.hcatalog.data.DefaultHCatRecord;
import org.apache.hive.hcatalog.data.HCatRecord;
import org.apache.hive.hcatalog.data.schema.HCatSchema;
import org.apache.hive.hcatalog.mapreduce.HCatOutputFormat;
/**
* ClassName:HiveStoreMapper <br/>
* Function: Mapper类. <br/>
* Date: 2016年4月4日 下午10:02:07 <br/>
* @author qiyongkang
* @version
* @since JDK 1.6
* @see
*/
public class HiveStoreMapper extends Mapper<Object, Text, WritableComparable<Object>, HCatRecord> {
private HCatSchema schema = null;
//每个mapper实例,执行一次
@Override
protected void setup(Mapper<Object, Text, WritableComparable<Object>, HCatRecord>.Context context)
throws IOException, InterruptedException {
schema = HCatOutputFormat.getTableSchema(context.getConfiguration());
}
@Override
protected void map(Object key, Text value, Mapper<Object, Text, WritableComparable<Object>, HCatRecord>.Context context)
throws IOException, InterruptedException {
//每行以制表符分隔 id, account, name, age
String[] strs = value.toString().split("\t");
HCatRecord record = new DefaultHCatRecord(4);
//id,通过列下表
record.set(0, Long.valueOf(strs[0]));
//account
record.set(1, strs[1]);
//name
record.set(2, strs[2]);
//age,通过字段名称
record.set("age", schema, Integer.valueOf(strs[3]));
//写入到hive
context.write(null, record);
}
public static void main(String[] args) {
String value = "1 1200 qyk 24";
String[] strs = value.toString().split("\t");
for (int i = 0; i < strs.length; i++) {
System.out.println(strs[i]);
}
}
}
主类:
/**
* Project Name:mr-demo
* File Name:LoadDataToHiveMR.java
* Package Name:org.qiyongkang.mr.hivestore
* Date:2016年4月4日下午9:55:42
* Copyright (c) 2016, CANNIKIN(http://http://code.taobao.org/p/cannikin/src/) All Rights Reserved.
*
*/
package org.qiyongkang.mr.hivestore;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hive.hcatalog.data.DefaultHCatRecord;
import org.apache.hive.hcatalog.data.schema.HCatSchema;
import org.apache.hive.hcatalog.mapreduce.HCatOutputFormat;
import org.apache.hive.hcatalog.mapreduce.OutputJobInfo;
/**
* ClassName:LoadDataToHiveMR <br/>
* Function: MR将数据直接入到hive. <br/>
* Date: 2016年4月4日 下午9:55:42 <br/>
*
* @author qiyongkang
* @version
* @since JDK 1.6
* @see
*/
public class LoadDataToHiveMR {
public static void main(String[] args) {
Configuration conf = new Configuration();
try {
Job job = Job.getInstance(conf, "hive store");
job.setJarByClass(LoadDataToHiveMR.class);
// 设置Mapper
job.setMapperClass(HiveStoreMapper.class);
// 由于没有reducer,这里设置为0
job.setNumReduceTasks(0);
// 设置输入文件路径
FileInputFormat.addInputPath(job, new Path("/qiyongkang/input"));
// 指定Mapper的输出
job.setMapOutputKeyClass(WritableComparable.class); // map
job.setMapOutputValueClass(DefaultHCatRecord.class);// map
//设置要入到hive的数据库和表
HCatOutputFormat.setOutput(job, OutputJobInfo.create("qyk_test", "user_info", null));
//这里注意是使用job.getConfiguration(),不能直接使用conf
HCatSchema hCatSchema = HCatOutputFormat.getTableSchema(job.getConfiguration());
HCatOutputFormat.setSchema(job, hCatSchema);
//设置输出格式类
job.setOutputFormatClass(HCatOutputFormat.class);
job.waitForCompletion(true);
} catch (Exception e) {
e.printStackTrace();
}
}
}
然后,我们使用maven打个包,上传到服务器。
然后,我们准备一个user_info.txt,上传至hdfs中的/qiyongkang/input下:
11 1200.0 qyk1 21
22 1301 qyk2 22
33 1400.0 qyk3 23
44 1500.0 qyk4 24
55 1210.0 qyk5 25
66 124 qyk6 26
77 1233 qyk7 27
88 15011 qyk8 28- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
注意以制表符\t分隔。
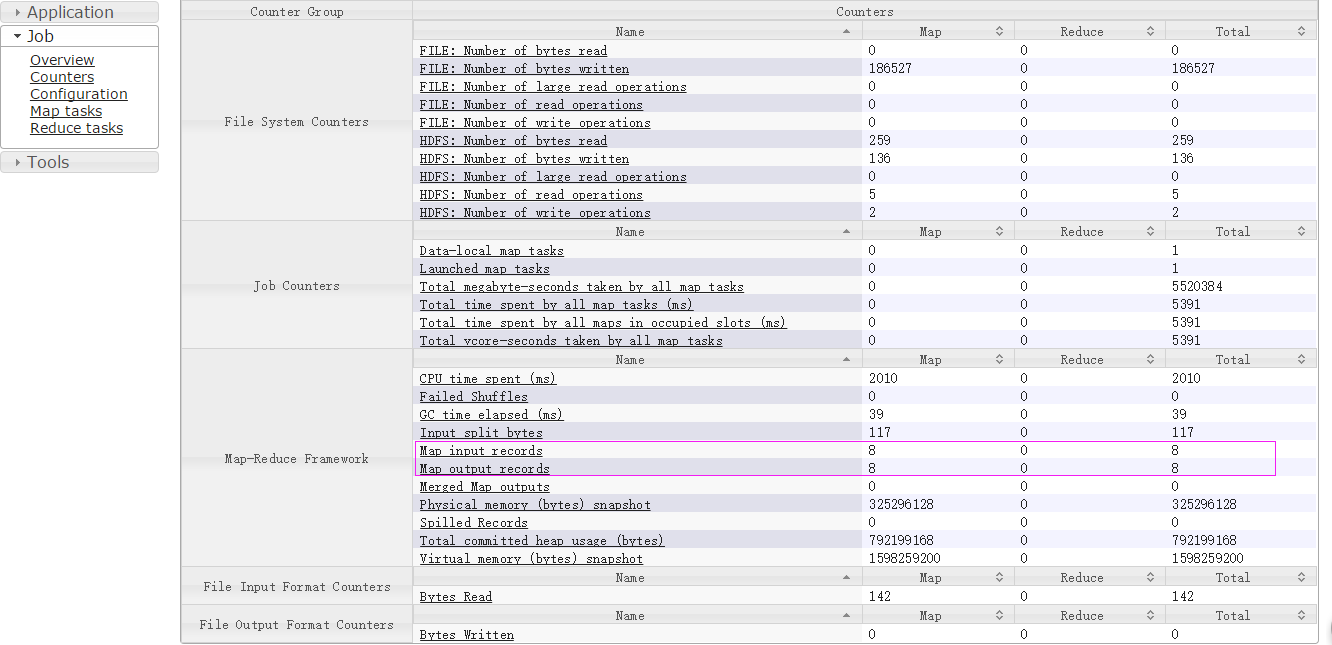
然后执行yarn jar mr-demo-0.0.1-SNAPSHOT-jar-with-dependencies.jar,在jobhistory可以看到:
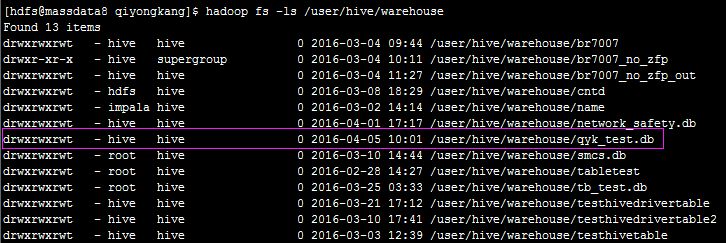
其实,hive的元数据是放在hdfs上,执行hadoop fs -ls /user/hive/warehouse可以看到:
然后,我们在hive命令行执行 select * from user_info;可以看到: 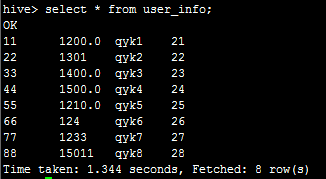
说明数据从hdfs写入到hive成功。
四、使用java jdbc连接Thrift Server查询元数据
接下来,我们使用java编写一个客户端,来查询刚才入到hive里面的数据,代码如下:
package org.hive.demo;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.ResultSetMetaData;
import java.sql.SQLException;
import java.sql.Statement;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import org.apache.log4j.Logger;
public class HiveStoreClient {
private static String driverName = "org.apache.hive.jdbc.HiveDriver";
private static String url = "jdbc:hive2://172.31.25.8:10000/qyk_test";
private static String user = "hive";
private static String password = "";
private static final Logger log = Logger.getLogger(HiveStoreClient.class);
@SuppressWarnings("rawtypes")
public static void main(String[] args) {
Connection conn = null;
Statement stmt = null;
ResultSet res = null;
try {
//加载驱动
Class.forName(driverName);
//获取连接
conn = DriverManager.getConnection(url, user, password);
stmt = conn.createStatement();
// select * query
String sql = "select * from user_info";
System.out.println("Running: " + sql);
//执行查询
res = stmt.executeQuery(sql);
//处理结果集
List list = convertList(res);
System.out.println("总记录:" + list);
//获取总个数
sql = "select count(1) from user_info";
System.out.println("Running: " + sql);
res = stmt.executeQuery(sql);
while (res.next()) {
System.out.println("总个数:" + res.getString(1));
}
} catch (ClassNotFoundException e) {
e.printStackTrace();
log.error(driverName + " not found!", e);
System.exit(1);
} catch (SQLException e) {
e.printStackTrace();
log.error("Connection error!", e);
System.exit(1);
} finally {
try {
res.close();
stmt.close();
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
/**
*
* convertList:将结果集转换成map. <br/>
*
* @author qiyongkang
* @param rs
* @return
* @throws SQLException
* @since JDK 1.6
*/
@SuppressWarnings({ "rawtypes", "unchecked" })
public static List convertList(ResultSet rs) throws SQLException {
List list = new ArrayList();
ResultSetMetaData md = rs.getMetaData();
int columnCount = md.getColumnCount(); //Map rowData;
while (rs.next()) { //rowData = new HashMap(columnCount);
Map rowData = new HashMap();
for (int i = 1; i <= columnCount; i++) {
rowData.put(md.getColumnName(i), rs.getObject(i));
}
list.add(rowData);
}
return list;
}
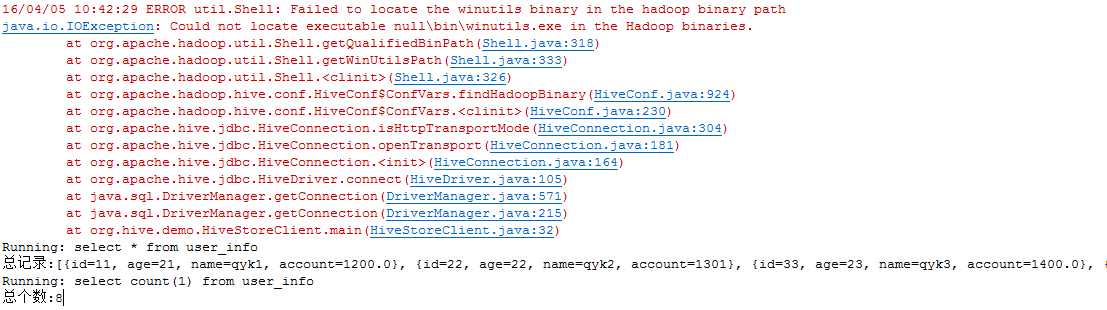
}执行后,可以看到控制台输出如下:
开始的异常可以忽略。可以看到数据,说明是成功的。
好了,hive就讲到这儿了。其实,hive还可以同步hbase的数据,还可以将hive的表数据同步到impala,因为它们都是使用相同的元数据,这个在后面的博文中再进行介绍。















 3914
3914

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









