







1、Redis内存组成
1)自身内存,(没有任何存储的时候,rss 内存)通常在3M左右,忽略不计
2)对象内存,即用户的数据存储,主要包括 keys+values , 所以说键的长度也是个因素
3)缓冲内存,输入输出缓冲区,AOF 缓冲区,复制积压缓冲,输入输出是重点考虑因素
4)内存碎片,used_memory_rss_human - used_memory_human 就是内存碎片
2、info memory
used_memory_human:644.96K // Redis 分配器分配的存储总量,没有包括碎片部分
used_memory_rss_human:2.54M // OS 角度看Redis所占用的存储总量,包括碎片部分
total_system_memory_human:1.49G // OS 总内存
used_memory_lua_human:25.00K // Lua 运行内存
maxmemory_human:1.96M // 设置的最大内存
maxmemory_policy:volatile-lru // 内存最大时采取的策略机制来删除键
mem_allocator:jemalloc-4.0.3 // 内存分配器,使用 jemalloc 是很不错的
mem_fragmentation_ratio:1.34 // used_memory_rss_human/used_memory_human
3、内存碎片
内存碎片产生的主要原因是内存分配器 jemalloc ,因为他们分配内存都是采用固定范围大小的存储空间,比如一个只需要 2.01M 对象,可能就会被分配空间为 4 M,因为 2 M 放不下。
当然另外的原因是,很多对象在修改的时候(比如字符串追加),Redis会为其分配更多的空间,这个时候有些空间也是浪费的,这个和Java的List Map分配差不多。
还有大量的键值定时过期,而这些过期的键又没有得到充分的释放回收,所以也会导致空间浪费。
内存碎片比例计算: mem_fragmentation_ratio
如果大于1,说明有内存碎片存在,如果非常大,那么应该适当重启程序来释放碎片
如果小于1,说明Redis在使用 SWAP , 内存与磁盘数据交换,这个很好性能,看看内存是否充足
4、Fork 内存消耗
无论是AOF重写还是RDB备份,都会fork一个子进程出来进行操作,那么这个操作所耗费的内存就叫做子进程内存消耗。
对于Fork操作具体是这样的,子进程和父进程同时共享物理内存,如果这个时候父进程还有写操作,那么子进程就会把写操作的那部分内存拷贝一份出来,那么这部分内存就是多出来要耗费的内存,Linux 用来 copy_on_write。可以查看日志,XXX memory used by copy-on-write
因此假如在Fork时没有写操作,那么内存消耗公式为:子进程+父进程 = 父进程 = Redis总内存
如果Fork时有写操作,那么内存消耗就是: 子进程复制那部分+父进程 = Redis总内存
所以得出的结论是Fork操作时总内存耗费并不是父进程的两倍,而是大于等于父进程
这里复制的时候为了避免过多的复制内存页,需要关闭OS的HugePage,因为开启他时默认复制需要 2 MB,但是关闭时复制只要 4 KB,足足差了 512 倍。
> echo never > /sys/kernel/mm/transparent_hugepage/enabled
> sysctl vm.overcommit_memory = 1 // 防止内存不足时而fork失败
5、设置内存上限
>config set maxmeory 1024
>config set maxmemory-policy XXX
设置最大内存,以及达到最大内存时采取的措施,最大内存时很有必要设置的,因为这个可以防止系统内存耗尽而宕机;如果达到最大内存时Redis应该采用何种策略去对Redis空间释放呢?也就是策略配置,默认就直接抛出异常。
其实通过动态设置内存最大值可以进行Redis瘦身,不过这种方式会造成一定的阻塞,而且无论使用何种策略来瘦身都试很好性能的,Redis在查找满足条件的键和删除这些键时有点性能损耗。
6、内存回收
1)定时任务删除,每秒运行10次查找过期需删除的键。
2)惰性删除,使用这个键的时候,先判断这个键是否过期,如果过期则删除,这其实影响到了 exist 命令的效率,但是他提高了Redis的整体性能,因为总是使用定时去删除在大量Key同时过期时就会出现大量的删除操作而阻塞整个Redis。
7、内存空间节省
因为Redis所耗费的空间都多是在对象内存,那么如何减少对象内存的空间就是首要任务。
Redis的五大数据类型都是通过 RedisObject 来封装的,这个结构体里面存储了基本的
1)type // 数据类型
2)encoding // 内部编码
3)refcount // 引用次数(共享对象,对于 1-9999 的整型使用共享)
4)lru // 最近使用时间
5)*ptr // 具体数据指针
-- 相关命令查看引用数量,编码类型,以及数据结构类型
>set str 1
> object refcount str
(integer) 2147483647
> object encoding str
"int"
> type str
string
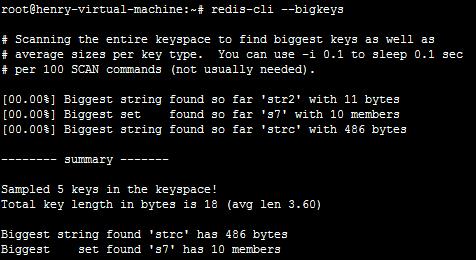
8、发现大对象 redis-cli --bigkeys
找出5种数据结构中最大的对象,因为对象的大小和时间复杂度有直接关系,所以减小对象和废弃高复杂度的算法是一种很直接的方式。
注意:对于具体数据结构的编码优化就暂时不列了,因为很多内容,目前最重要的是如何发现阻塞的问题,然后解决他。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









