






大多数的程序代码是必要的时,它可以被加载到内存中运行。手术后,可直接丢弃或覆盖其它代码。
我们PC然在同一时间大量的应用,地址空间差点儿能够整个线性地址空间(除了部分留给操作系统或者预留它用)。能够觉得每一个应用程序都独占了整个虚拟地址空间(字长是32的CPU是4G的虚拟地址空间)。但我们的物理内存仅仅是1G或者2G。
即多个应用程序在同一时候竞争使用这块物理内存。其必定会导致某个时刻仅仅存在程序的某个片段在运行,也即是全部程序代码和数据分时复用物理内存空间—这就是内存管理单元(MMU)工作核心作用所在。
处理器系列的芯片(如X86、ARM7以上、MIPS)一般都会有MMU。跟操作系统一块实现虚拟内存管理。MMU也是Linux、Wince等操作系统的硬件要求。而控制器系统的芯片(面向低端控制领域,ARM1,2。MIPS M系列,80251等)一般都没有MMU,或者其仅仅有单一的线性映射机制。
本文要谈的是控制器领域SoC的内存管理单元的硬件设计,其重要的理念相同是代码和数据分时复用物理内存空间,在保障系统功能和性能的基础上最大限度地节省物理内存的目的。
相关的文章包含:SoC软件架构设计之中的一个:系统内存需求评估和节省内存的软件设计技巧。
一、内存管理单元(MMU)的工作机制
在阐述控制器领域的内存管理之前。还是要先介绍处理器领域的虚拟内存管理机制,前者非常大程度上是对后者核心机制精髓的借鉴。实现虚拟内存管理有几个模块是协调工作的:CPU、MMU、操作系统、物理内存。如图示(如果该芯片系列没有cache):
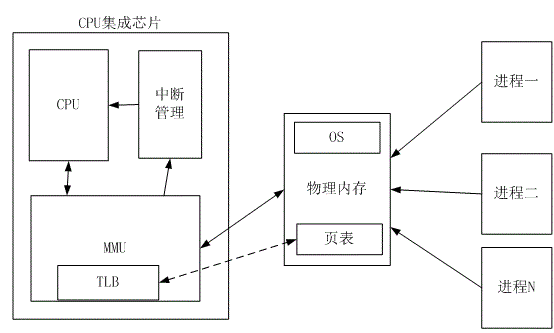
我们依据上图来分析一下CPU訪问内存的过程,如果寻址是0x10000008。一页大小为4K(12比特)。则虚拟地址会分成两个部分:页映射部分(20bit,0x10000)+页内偏移(12bit。 0x8)。CPU通过总线把地址信号(0x10000008)送给MMU,MMU会把该地址的页映射部分(20bit)拿到TLB中匹配。
TLB是什么东西?Translation Lookaside Buffer,网上有称为“翻译后备缓冲器”。
这个翻译都不知道它干什么。它的作用就是页表的缓冲,我喜欢叫它为页表cache。
其结构图例如以下:

能够想象,TLB就是索引地址数组,数组的每一个元素就是一个索引结构,包括虚拟页地址和物理页地址。其在芯片内部表现为寄存器形式,一般寄存器都是32位,实际上TLB中的页地址也是32位寄存器,仅仅只是索引比較时是比較前20bit。后12bit事实上也是实用的,比如能够设置某个bit是表示常驻的。即该索引是永远有效的,不能更换,这样的场景通常是为适合一些性能要求特别高的编解码算法而设计的。
很驻内存的一般在某个时刻(如TLB填满时訪问一个新的页地址)就会发生置换。
1) 假如0x10000008的前20bit在TLB中第M个索引中命中,这时就表示该虚拟页在物理内存中已经给它分配好相应的物理内存,页表中也已经做好记录。至于虚拟地址相应的代码页是否从外存储(flash,card,硬盘)的程序中载入到内存中还须要要另外的标记,怎么标记呢?就是利用上面所讲的TLB低12位的某一bit(我们称为K)来标识,1标识代码数据已经载入到内存,0表示还没载入到内存。假如是1,那就会用M中的物理地址作为高20bit,以页内偏移0x8作为低12bit,形成一个物理地址,送到内存去訪问。
此时该次訪问就会完毕。
2) 假如K是0。那意味着代码数据尚未载入到内存,这时MMU会向中断管理模块输出信号,触发一个中断进行内核态。由操作系统负责将相应的代码页载入到内存。
并改动相应页表项的K比特和TLB相应项的K比特为1.
3) 假如0x10000008的前20bit在TLB全部索引中都没有命中。则MMU也会向中断管理模块输出一个信号触发中断进入内核态。由操作系统将0x10000008右移12位(即除以4K)到页表中去取得相应的物理页值。假如物理页值非0有效,说明代码已经载入到内存了。这时将页表项的值填入到某一个空暇的TLB项中。假如物理页值为0,说明尚未给这个虚拟页分配实际的物理内存空间。这时会给它分配实际的物理内存,并写好页表的相应项(这时K是0),最后将这索引项写入TLB的当中一条。
2)和3)事实上都是在中断内核态中完毕的。为什么不一块做了呢?主要是由于一次中断不应该做太多事情,以加大中断延时,影响系统性能。当然假设有芯片将两者做成一个中断也是能够理解的。我们再来看看页表的结构。页表当然也能够按TLB那样做成索引数组,可是这样有两个不好的地方:
1)页表是要映射所有的虚拟页面的,其维护在内存中也须要不小的空间。
页大小是4K时,那映射所有就是4G/4K=1M条索引,每条索引4*2=8个字节,就是8M内存。
2)假如按TLB那种结构。那匹配索引的过程就是一个for循环匹配电路,效率非常低。要知道我们做这个都是在中断态完毕的。
所以一般的页表都是设计成一维数组,即以整个线性虚拟地址空间按页为单位依次作为数组的下标,即页表的第一个字(4字节)就映射虚拟地址空间的最低4K,第二个字映射虚拟地址最低的第二个4K,以此类推,页表的第N个字就映射虚拟地址空间的第N个4K空间,即(N-1)*4K~4KN的地址空间。
这样页表的大小就是1M*4=4M字节,并且匹配索引的时候仅仅是一个偏移计算,很快。
承前启后,在引出第二部分之前先明白两个概念:
1. Bank表示代码分块的意思,类似于上面提到的页的概念。
2.不同代码分时复用内存:不同代码即意味着不同的虚拟地址相应的代码,(程序链接后的地址都是虚拟地址)。内存即物理内存,即一定大小的不同虚拟地址的代码在不同的时刻都跑在同一块一定大小的物理内存空间上。
每一块不同的代码块即是不同的代码Bank。
二、控制器领域SoC内存管理单元的硬件设计
这里专指没有内存管理单元的SoC设计。一般为了减少成本。在性能足够时,假设16位或者24位字长CPU可以解决这个问题。一般都不会去选32位字长的CPU。除非是计算性能考虑,或者32位CPU的license更廉价(一般非常少见)。仅仅要可以达到高效地进行内存管理。实现物理内存分时复用的目的,那都可以称为是成功或者有效的。在介绍真正的内存管理单元硬件设计之前。我们先简介一种利用工具链来实现内存分时复用的机制,然后再结合MMU和这个工具链实现的分块处理方法去设计我们新的内存管理单元,包含其硬件工作机制和软件设计和关键机制。
因为下面内容涉及到在审专利,经过考虑,临时将下面内容隐藏,适当时候再公开,抱歉!
×××××××
后记补充
在集成没有MMU的CPU时,SoC要实现内存管理,须要另外设计一个内存管理模块,实现MMU的核心功能,即代码分页(块)映射的功能。并且须要简化设计以达到最高的效率,同一时候代码分块须要直接地体如今链接脚本上。为了追求效率,编译链接后的可运行性文件还会被离线解析组织成一个更简化的运行文件,把不须要的段都删除,并将分块代码按逻辑顺序放好,以便于操作系统在必要时更快地载入。当然,操作系统的代码内存管理也须要配合内存管理硬件电路,并可以解析又一次打包后的运行程序文件。
因此内存管理的实现是须要架构师从软件和硬件上全面考虑,尽可能地在实现核心功能的基础上简化电路和设计。涉及的模块包含:硬件机制设计、物理内存分配、代码分块原则、linker脚本定义、打包运行文件、操作系统定制等等。兴许阐述的架构设计将会包含以上内容。
请关注SoC嵌入式软件架构设计(控制器SoC固件架构)系列博文:
SoC嵌入式软件架构设计之二:没有MMU的CPU实现虚拟内存管理的设计方法
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









