






副本放置策略
的副本放置策略的基本思想是:
第一block在复制和client哪里node于(假设client它不是群集的范围内,则这第一个node是随机选取的。当然系统会尝试不选择哪些太满或者太忙的node)。
第二个副本放置在与第一个节点不同的机架中的node中(随机选择)。
第三个副本和第二个在同一个机架,随机放在不同的node中。
假设还有很多其它的副本就随机放在集群的node里。
Hadoop的副本放置策略在可靠性(block在不同的机架)和带宽(一个管道仅仅须要穿越一个网络节点)中做了一个非常好的平衡。
下图是备份參数是3的情况下一个管道的三个datanode的分布情况。
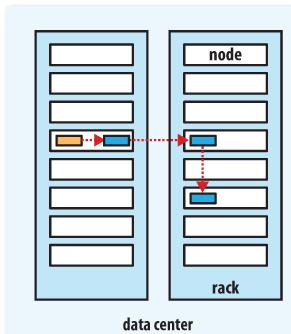
流水线复制
当client向 HDFS 文件写入数据的时候。一開始是写到本地暂时文件里。
假设该文件的副本系数设置为 3 ,当本地暂时文件累积到一个数据块的大小时,client会从 Namenode 获取一个 Datanode 列表用于存放副本。然后client開始向第一个Datanode数据传输,第一个 Datanode 一小部分一小部分 (4 KB) 地接收数据,将每一部分写入本地仓库。并同一时候传输该部分到列表中第二个 Datanode 节点。第二个 Datanode 也是这样,一小部分一小部分地接收数据,写入本地仓库。并同一时候传给第三个 Datanode 。
最后,第三个 Datanode 接收数据并存储在本地。因此,Datanode 能流水线式地从前一个节点接收数据。并同一时候转发给下一个节点,数据以流水线的方式从前一个Datanode拷贝到下一个Datanode。
机架感知
大型Hadoop集群以机架的形式来组织的,同一个机架上不同节点间的网络状况比不同机架之间更为理想。另外,NameNode设法将数据块副本保存在不同的机架上以提高容错性。
网络拓扑
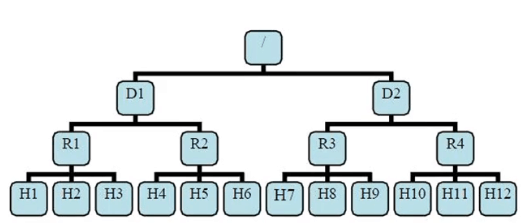
有了机架感知。NameNode就能够画出上图所看到的的datanode网络拓扑图。D1,R1都是交换机,最底层是datanode。
则H1的rackid=/D1/R1/H1,H1的parent是R1,R1的parent是D1。这些rackid信息能够通过topology.script.file.name配置。有了这些rackid信息就能够计算出随意两台datanode之间的距离。
distance(/D1/R1/H1,/D1/R1/H1)=0 同样的datanode
distance(/D1/R1/H1,/D1/R1/H2)=2 同一rack下的不同datanode
distance(/D1/R1/H1,/D1/R1/H4)=4 同一IDC下的不同datanode
distance(/D1/R1/H1,/D2/R3/H7)=6 不同IDC下的datanode
注意:
1)当没有配置机架信息时,全部的机器Hadoop都默认在同一个默认的
机架下,以名为”/default-rack”。这样的情况下,不论什么一台datanode机器,无论物理上是否属于同一个机架。都会被觉得是在同一个机架下。
2)一旦配置topology.script.file.name。就依照网络拓扑结构来寻找datanode。topology.script.file.name这个配置选项的value指定为一个可运行程序。通常为一个脚本。
版权声明:本文博客原创文章,博客,未经同意,不得转载。
















 1688
1688











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









