







一、spread与grouped mirror
GreenPlum在处理primary与mirror segment的关联匹配时,提供spread与grouped两种方式,经过反复测试可以看出这两种在一个物理服务器上同时存在多个mirror实例时会产生区别:
① grouped模式:将一个物理服务器上的这个N个mirror instance先捆绑为一个组,然后将这个组再与primary instance进行关联,如下图:
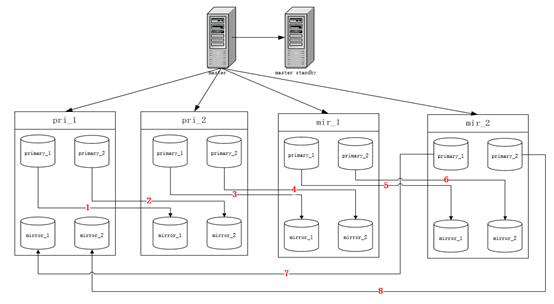
② spread模式:按照测试结果,我理解的是,它将这N个mirror instance “随机” 的匹配指向primary instance,如下图:
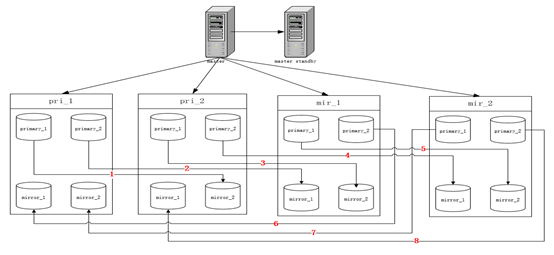
二、mirror
由于我是通过源码编译安装,然后按照如下顺序,手动创建配置文件进行操作
>> 最小化安装(1个master + 1个primary)
>> 添加 master standby
>> 添加mirror 匹配primary
>> 添加 primary && mirror 组
然后,在进行第四步继续扩展实例时,通过gpexpand命令创建配置文件,会给出如下提示:
| The current system appears to be non-standard. The number of primary segments is not consistent across all nodes: seg_1 != mir_1.gpexpand may not be able to symmetrically distribute the new segments appropriately. It is recommended that you specify your own input file with appropriate values. |
后来,经过验证发现,由于我是手动配置的mirror segment,且没有配置“across”交叉式的 primary -- mirror ,才出现这个问题,并且在后续输入server host之后,会提示类似于可用节点数不足的错误。
关于刚刚说的“across”交叉mirror,实际是这种情形:规划的primary服务器(如node1)与mirror服务器(node2),在完整的集群环境中二者均做primary与mirror节点,且二者交叉关联。
三、节点配置文件
在手动创建配置文件时,一定要注意:
>> dbid的连续性
>> content的连续性与一致性
>> 数据文件目录编号的连续性(这个编号可以按照content的值来定义)















 4105
4105

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









