







1、Hadoop简介
Apache Hadoop是一款支持数据密集型分布式应用并以Apache 2.0许可协议发布的开源软件框架。它支持在商品硬件构建的大型集群上运行的应用程序。Hadoop是根据Google公司发表的MapReduce和Google档案系统的论文自行实作而成。
Hadoop框架透明地为应用提供可靠性和数据移动。它实现了名为MapReduce的编程范式:应用程序被分割成许多小部分,而每个部分都能在集群中的任意节点上执行或重新执行。此外,Hadoop还提供了分布式文件系统(Hadoop Nutch Distributed File System, HDFS),用以存储所有计算节点的数据,这为整个集群带来了非常高的带宽。MapReduce和分布式文件系统的设计,使得整个框架能够自动处理节点故障。
Hadoop的框架最核心的设计就是:HDFS和MapReduce.HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。
1.1、Hadoop生态系统
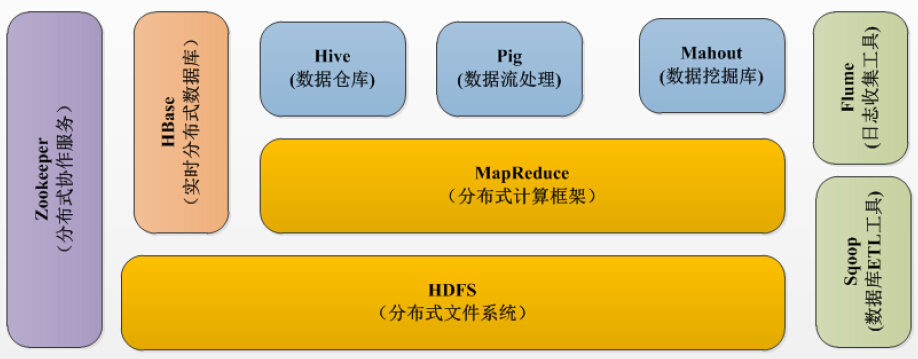
现在普遍认为整个Apache Hadoop“平台”包括:
- Hadoop内核
- MapReduce
- Hadoop分布式文件系统(HDFS)
- 一些相关项目,有Apache Hive和Apache HBase等等。
具体来说,Hadoop相关的项目有:
- Hadoop Common:在0.20及以前的版本中,包含HDFS、MapReduce和其他项目公共内容,从0.21开始HDFS和MapReduce被分离为独立的子项目,其余内容为Hadoop Common
- HDFS:Hadoop分布式文件系统(Distributed File System)-HDFS(Hadoop Distributed File System)。HDFS是一种数据分布式保存机制,数据被保存在计算机集群上,HDFS为HBase等工具提供了基础。
- MapReduce:并行计算框架,0.20前使用org.apache.hadoop.mapred旧接口,0.20版本开始引入org.apache.hadoop.mapreduce的新API。它是一个分布式、并行处理的编程模型,MapReduce把任务分为map(映射)阶段和reduce(化简)。由于MapReduce工作原理的特性,Hadoop能以并行的方式访问数据,从而实现快速访问数据。
- Apache HBase:分布式NoSQL列数据库,类似谷歌公司BigTable。是一个建立在HDFS之上,面向列的NoSQL数据库,用于快速读/写大量数据。HBase使用Zookeeper进行管理,确保所有组件都正常运行。
- Apache Pig:它是MapReduce编程的复杂性的抽象。Pig平台包括运行环境和用于分析Hadoop数据集的脚本语言(Pig Latin)。其编译器将Pig Latin翻译成MapReduce程序序列。
- Apache Hive:构建于hadoop之上的数据仓库,通过一种类SQL语言HiveQL为用户提供数据的归纳、查询和分析等功能。Hive最初由Facebook贡献。Hive让不熟悉MapReduce开发人员也能编写数据查询语句,然后这些语句被翻译为Hadoop上面的MapReduce任务。像Pig一样,Hive作为一个抽象层工具,吸引了很多熟悉SQL而不是Java编程的数据分析师。
- Apache Mahout:机器学习算法软件包。
- Apache Sqoop:结构化数据(如关系数据库)与Apache Hadoop之间的数据转换工具。Sqoop利用数据库技术描述架构,进行数据的导入/导出;利用MapReduce实现并行化运行和容错技术。
- Apache ZooKeeper:分布式锁设施,提供类似Google Chubby的功能,由Facebook贡献。用于Hadoop的分布式协调服务。Hadoop的许多组件依赖于Zookeeper,它运行在计算机集群上面,用于管理Hadoop操作。
- Apache Flume:提供了分布式、可靠、高效的服务,用于收集、汇总大数据,并将单台计算机的大量数据转移到HDFS。它基于一个简单而灵活的架构,并提供了数据流的流。它利用简单的可扩展的数据模型,将企业中多台计算机上的数据转移到Hadoop
- Apache Avro:新的数据序列化格式与传输工具,将逐步取代Hadoop原有的IPC机制。
如下图所示:
1.2、优点
- 高可靠性。Hadoop按位存储和处理数据的能力值得人们信赖。
- 高扩展性。Hadoop是在可用的计算机集簇间分配数据并完成计算任务的,这些集簇可以方便地扩展到数以千计的节点中。
- 高效性。Hadoop能够在节点之间动态地移动数据,并保证各个节点的动态平衡,因此处理速度非常快。
- 高容错性。Hadoop能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配。
- 低成本。与一体机、商用数据仓库以及QlikView、Yonghong Z-Suite等数据集市相比,hadoop是开源的,项目的软件成本因此会大大降低。
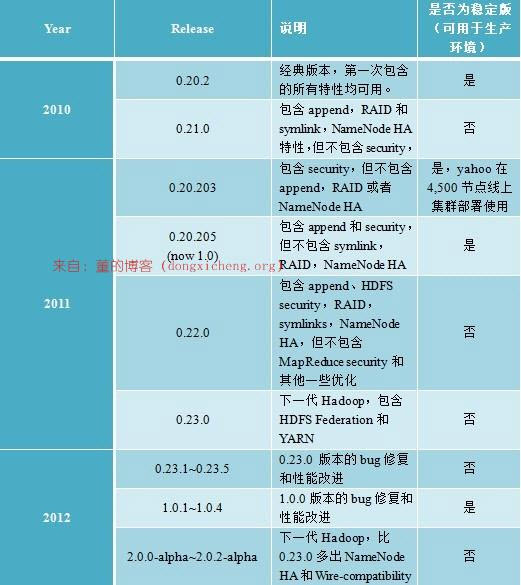
1.3 Apache版本衍化
Apache Hadoop版本分为两代,我们将第一代Hadoop称为Hadoop 1.0,第二代Hadoop称为Hadoop2.0。第一代Hadoop包含三个大版本,分别是0.20.x,0.21.x和0.22.x,其中,0.20.x最后演化成1.0.x,变成了稳定版,而0.21.x和0.22.x则NameNode HA等新的重大特性。第二代Hadoop包含两个版本,分别是0.23.x和2.x,它们完全不同于Hadoop 1.0,是一套全新的架构,均包含HDFS Federation和YARN两个系统,相比于0.23.x,2.x增加了NameNode HA和Wire-compatibility两个重大特性。
2、应用场景
美国着名科技博客GigaOM的专栏作家Derrick Harris在一篇文章中总结了10个Hadoop的应用场景:
- 在线旅游:全球80%的在线旅游网站都是在使用Cloudera公司提供的Hadoop发行版,其中SearchBI网站曾经报道过的Expedia也在其中。
- 移动数据:Cloudera运营总监称,美国有70%的智能手机数据服务背后都是由Hadoop来支撑的,也就是说,包括数据的存储以及无线运营商的数据处理等,都是在利用Hadoop技术。
- 电子商务:这一场景应该是非常确定的,eBay就是最大的实践者之一。国内的电商在Hadoop技术上也是储备颇为雄厚的。
- 能源开采:美国Chevron公司是全美第二大石油公司,他们的IT部门主管介绍了Chevron使用Hadoop的经验,他们利用Hadoop进行数据的收集和处理,其中这些数据是海洋的地震数据,以便于他们找到油矿的位置。
- 节能:另外一家能源服务商Opower也在使用Hadoop,为消费者提供节约电费的服务,其中对用户电费单进行了预测分析。
- 基础架构管理:这是一个非常基础的应用场景,用户可以用Hadoop从服务器、交换机以及其他的设备中收集并分析数据。
- 图像处理:创业公司Skybox Imaging 使用Hadoop来存储并处理图片数据,从卫星中拍摄的高清图像中探测地理变化。
- 诈骗检测:这个场景用户接触的比较少,一般金融服务或者政府机构会用到。利用Hadoop来存储所有的客户交易数据,包括一些非结构化的数据,能够帮助机构发现客户的异常活动,预防欺诈行为。
- IT安全:除企业IT基础机构的管理之外,Hadoop还可以用来处理机器生成数据以便甄别来自恶意软件或者网络中的攻击。
- 医疗保健:医疗行业也会用到Hadoop,像IBM的Watson就会使用Hadoop集群作为其服务的基础,包括语义分析等高级分析技术等。医疗机构可以利用语义分析为患者提供医护人员,并协助医生更好地为患者进行诊断。















 1337
1337

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









