







摘要
【背景】
MapReduce是一个google开发的编程模型,用来在分布式环境中处理和生成大数据集。许多现实世界的任务可以用两个函数实现:map和reduce函数。MapReduce在云计算中扮演了关键角色,因为MapReduce减少了分布式编程的复杂性,并且使得人们更容易的在普通机器组成的大规模集群上进行开发。Hadoop是一个实现Google MapReduce架构的开源项目。已经被广泛应用在了FaceBook,Yahoo,Twitter等许多网站。
【我们的工作】
我们开发了一个基于web的图形用户接口,可以帮助用户运用MapReduce而不需要去编写程序。用户只需要知道在target-value三元组中如何定义他们的任务即可
I、介绍
MapReduce产生背景、作用
近年来,云计算及其提供的服务发展迅速。MapReduce【1】编程模型便是云计算用到的一项技术。Google设计MapReduce用来处理大规模以生成有用信息。MapReduce将分布式计算系统的细节隐藏起来,使得对于用户来说分布式编程的复杂性大幅降低。
以及处理数据集基本流程
MapReduce将输入数据分割为大量Map操作节点,并且产生大量包含key/value对的输出。Reduce操作结点则将有相同value的键聚集到一起。
MapReduce数据流
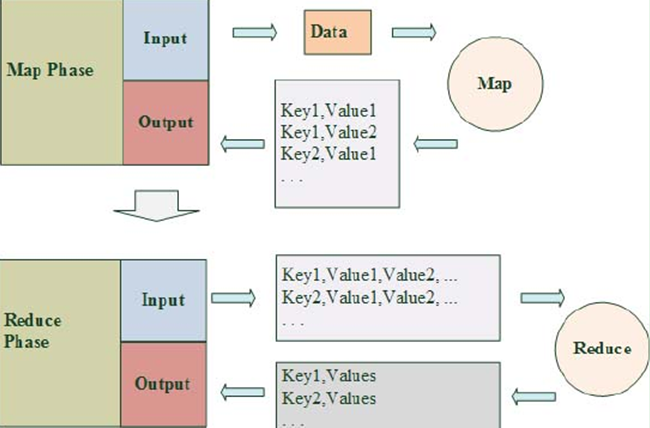
应用
一个例子是WordCounter;
还用在许多应用【2-10】中,比如分布式Grep,URL访问频率统计,web连接图反转,主机关键向量指标,倒排索引,分布式分类,安全增强型DNS群组,动态旅程以及其他真实世界应用。甚至在Google新闻搜索引擎技术,过滤器【5】,Google仍然使用MapReduce分析和生成最初的搜索索引。
提出问题
虽然MapReduce可以简化分布式计算编程的复杂性。MapReduce仍然不容易实现。
解决
我们提出了一个用户MapReduce数据处理的基于web的GUI,balabala。。。这样可以使得开发时间大大缩短,MapReduce范例也可以得到广泛应用。
II、相关工作
A、Hadoop MapReduce
Hadoop【6】是一个通过Apache实现谷歌MapReduce架构的开源项目。Hadoop MapReduce是一个在大规模商用硬件集群并行处理大规模数据的软件架构。
B、Cascading
MapReduce为用户建立大规模数据解决方案提供两个强大的简单函数:Map和Reduce。但对于开发者来说,将MapReduce应用分割为map函数和Reduce函数是很困难的。我们需要更高级的函数来帮助我们建立适用于现实世界案例的MapReduce解决方案。Cascading【7】是一个开源java库,其API为MapReduce提供一个抽象层。Cascading处理模型允许开发者在Hadoop平台快速开发复杂应用。
Cascading包含了过多的数据处理概念,所以不够方便。
取而代之的是控制基于web的GUI。因此,用户可以更直接、方面的解决现实世界的数据处理问题。
C、Pig
Pig是一个高层次的平台,帮助用户创建MapReduce程序,用Hadoop分析大数据集。
介绍了3个工具,单纯介绍Hadoop,没提到其优缺点;
Cascading解决了建立MapReduce程序的问题,可以快速开发应用,有新缺点,引出web-based GUI;
单纯介绍Pig,没提到其优缺点;
Pig:A high-level data-flow language and execution framework for parallel computation.
【真不知道这3个相关工作和本文有毛线的关系】
III、MapReduce数据处理的web-based GUI
原来缺点
在MapReduce中,map阶段使用用户自定义规则分割输入数据。Map输出key/value对将会被分为Reduce部分或者Combine部分。开发者不得不设计Map部分和Reduce部分的key/value对的编程细节。
新方法
Map和Reduce部分被每层的“目标-价值-操作”隐藏起来。
Point1、有一个从不同输出中集成不同格式数据的“容器”。
Point2、在一个用户上传数据到HDFS,初始化容器的列之后,它可以使用基于web 的GUI操作MapReduce处理数据。
开始介绍
A、目标-价值-操作
目标-价值-操作是一个简单而独到的在Map和Reduce中显示数据处理过程的想法。用户只需要选择一些对象作为目标,给每个对象一个value值,接着定义想要的操作。
Point1、比如说,在单词计数问题中,每个单词是一个目标,值是1,操作是sum。
Point2、另一个例子是文档倒排索引中每个单词和他的位置的对应。目标是每个单词。其文档名称是值。最后我们在合并操作后可以得到结果。
B、操作组成
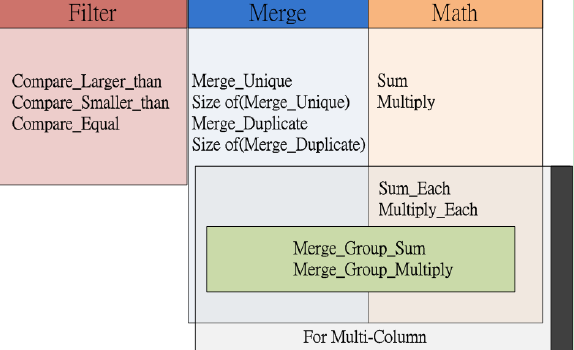
图2 目标-价值-操作的运算类型
Point1、比较运算的职责仅仅是过滤数据流中的数据,所以比较运算并没有返回值。
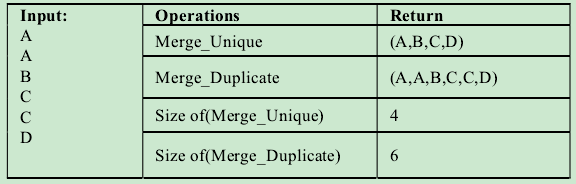
Point2、这里有4个不同的合并运算:Merge_Unique,Merge_Duplicate,Size of(Merge_Unique)和Size of(Merge_Duplicate)。后两个运算将会返回数据集的基数。
Merge_Group_Sum和Merge_Group_Multiply应该输入一对列值,其中一个是text类型,另一个integer类型。接着text会被合并,value会进行加法或者乘法操作。
TABLE I. THE MERGE EXAMPLES

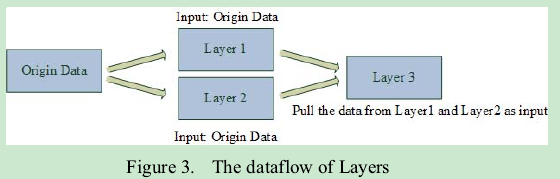
C、层次
在我们基于web的GUI中,“层次”控制到MapReduce工作的链接。每一层由单个或者一系列的目标-价值-操作和容器组成。一个层次可以将其他层次的输出或者原始数据作为其输入。
D、容器
“容器”将不同的输出合并为多列相同数据集,这使得当用户把来自不同层次的不同输出作为其输入时产生的输出数据流可见,方便。

E、系统架构
MapReduce数据处理基于web-based GUI和一个Hadoop集群。
下图显示了我们提出的系统架构和工作流。
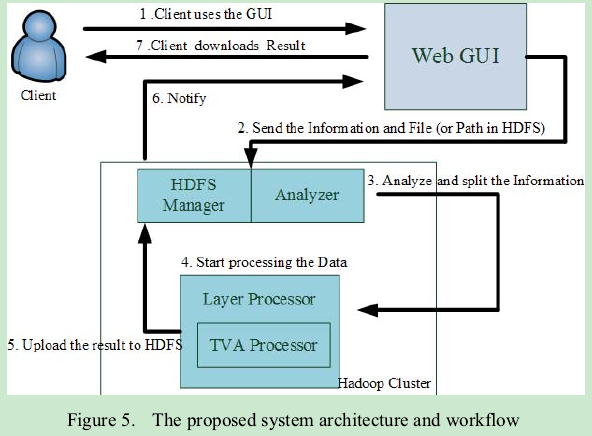
【查了查没找到TVA Processor是什么】
GUI优缺点
虽然GUI很方便,但却没有真正编程富有弹性。但编程中过多的操作远远超过GUI的复杂性。因此,当我们想要处理超大规模复杂数据任务的时候,GUI方法在协作模块化工作方面是非常合适的。
IV、学习案例和实现
在我们基于web的GUI中,用户可以拖动目标-价值-操作,输入路径形式和容器放到网页上的拖放区域。拖放提供了一个便捷的控制方法。
接着举例子,先用MapReduce描述过程,再用GUI方式实现
原本MapReduce实现:
下图是计算两两文档相似度的算法

sim[i,j]表示文档i和文档j的相似度。把di和dj看作单词大集合;
推测Pt是公共单词集合,把每个单词分别在di和dj出现次数的乘积累加起来算出sim作为相似度;
如果是两个相同文档,自然其计算结果会非常大。

盯着这小图看了一会才明白:
第3列列出了对每个单词而言,不同文档中出现的次数;
reduce成第四列没变,接着map操作后,计算两个文档之间的权重,以A为例,A在d1,d3两文档中权重相乘得相似度1×2=2,所以d1,d3之间相似度为2,只出现在一个文档中的单词直接被忽略;
shuffle操作合并上一步的权重,得到最终两两权重;
Web-based GUI实现:


GUI中的计算过程本质上和MapReduce是一样的,但借助GUI工具,用户不用接触shuffle、map之类具体操作,只需要做:
1、在层次1中,我们想要计算每个文档中每个单词的权重,这和倒排索引和单词统计很像。我们选择单词和文档名作为目标,将value赋值为1,操作是Sum,这样我们算出了最后权重。
2、在层次2中,我们选择单词作为目标,将一对文档名和权重作为value,将Merge_Group_Multiply作为操作。
最后,我们将权重相加得到两两文档相似度结果。
V、结论和展望
重新回顾一下我们的工作,好像很叼的样子。。
我们为MapReduce数据处理提出了一个基于web的GUI。
我们也提出了3个抽象数据处理构建积木块以隐藏Map和reduce的编程细节。用户只要选择一些对象作为目标;给每个对象赋值,执行操作。层次和容器使得输入/输出可见,而且易于控制。
我们提出的方法非常适合基于web的GUI,因为MapReduce数据处理的复杂性会大大降低。因此,用户不需要在它们的电脑下载Hadoop,却可以在任何地点,任何设备用过GUI处理他们的数据。















 1955
1955

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









