







 目录MR简介MR实现的操作流程作业提交流程Mapper阶段解读Reducer阶段解读数据流向分析总体处理流程分析Shuffle阶段解读MR简介一个MR作业通常会把输入的数据集切分为若干独立的数据块,先由Map任务并行处理,然后MR框架对Map的输出先进行排序,然后把结果作为Reduce任务的输入。MR框架是一种主从框架,由一个单独的JobTracker节点和多个TaskTracker节点组成。(JobTracker相当于Master,负责作业任务的调度,TaskT
目录MR简介MR实现的操作流程作业提交流程Mapper阶段解读Reducer阶段解读数据流向分析总体处理流程分析Shuffle阶段解读MR简介一个MR作业通常会把输入的数据集切分为若干独立的数据块,先由Map任务并行处理,然后MR框架对Map的输出先进行排序,然后把结果作为Reduce任务的输入。MR框架是一种主从框架,由一个单独的JobTracker节点和多个TaskTracker节点组成。(JobTracker相当于Master,负责作业任务的调度,TaskT
目录
MapReduce中job参数及设置map和reduce的个数
MR简介
一个MR作业通常会把输入的数据集切分为若干独立的数据块,先由Map任务并行处理,然后MR框架对Map的输出先进行排序,然后把结果作为Reduce任务的输入。MR框架是一种主从框架,由一个单独的JobTracker节点和多个TaskTracker节点组成。(JobTracker相当于Master,负责作业任务的调度,TaskTracker相当于Slave,负责执行Master指派的任务)
用户编写的程序分成三个部分:Mapper、Reducer 和Driver。
MapReduce计算任务可以划分为两个阶段:

MR实现的操作流程
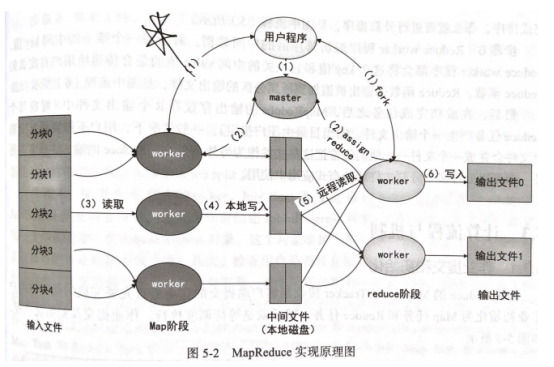
如上图所示,具体MR的具体步骤可描述如下:
步骤1:
把输入文件分成M块(每一块大小Hadoop默认是64M,可修改)。
步骤2:
master选择空闲的执行者worker节点,把总共M个Map任务和R个Reduce任务分配给他们,如上图中(2)所示。
步骤3:
一个分配了Map任务的worker读取并处理输入数据块。从数据块中解析出key/value键值对,把他们传递给用户自定义的Map函数,由Map函数生成并输出中间key/value键值对,暂时缓存在内存中,如上图中(3)所示。
步骤4:
缓存中的key/value键值对通过分区函数分成R个区域,之后周期性地写入本地磁盘上。并把本地磁盘上的存储位置回传给master,由master负责把这些存储位置传送给Reduce worker,如上图中(4)所示。
步骤5:
当Reduce worker接收到master发来的存储位置后,使用RPC协议从Map worker所在主机的磁盘上读取数据。在获取所有中间数据后,通过对key排序使得相同具有key的数据聚集在一起。如上图中(5)所示。
步骤6:
Reduce worker程序对排序后的中间数据进行遍历,对每一个唯一的中间key,Reduce worker程序都会将这个key对应的中间value值的集合传递给用户自定义的Reduce函数,完成计算后输出文件(每个Reduce任务产生一个输出文件)。如上图中(6)所示。
作业提交流程
步骤1:命令行提交。用户使用Hadoop命令行脚本提交MR程序到集群。
步骤2:作业上传。这一步骤包括了很多初始化工作,如获取用户作业的JobId,创建HDFS目录,上传作业、相关依赖库等到HDFS上。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1674
1674











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











