







group by 有一个原则,
不分组必聚合原则:就是 select 后面的所有列中,没有使用聚合函数的列,必须出现在 group by 后面(重要)
一、group by取最大值
面试遇到一个分组取最大值的问题
例子一 取最新充值记录
充值记录表
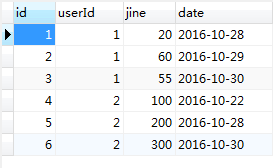
CREATE TABLE chongZhi (
id int not null primary key AUTO_INCREMENT COMMENT '主键编号',
userId int COMMENT '充值用户id',
jine int COMMENT '充值金额',
date date COMMENT '充值日期'
)ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT '充值记录表';
insert into chongZhi(userId,jine,date) value(1,20,'2016-10-28');
insert into chongZhi(userId,jine,date) value(1,60,'2016-10-29');
insert into chongZhi(userId,jine,date) value(1,55,'2016-10-30');
insert into chongZhi(userId,jine,date) value(2,100,'2016-10-22');
insert into chongZhi(userId,jine,date) value(2,200,'2016-10-28');
insert into chongZhi(userId,jine,date) value(2,300,'2016-10-30');
select userId as 用户ID,max(date) as 最近充值时间 from chongZhi group by 1;运行结果

可是这样不能显示充值数据ID和充值金额,不然会违反不分组必聚合原则sql会报错。
下面的例子可以解决这个问题。
例子二 物料供货商最新报价
物料报价表:
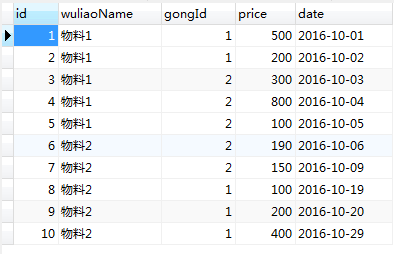
根据上面的表 查询每种物料 每种供货商 的最新报价:
与上面问题的不同之处:
①这个是两个字段确定唯一性(类似联合主键,这里是联合分组)。
②需要显示本表中其他的字段。
其实这个差不多。
SQL:
CREATE TABLE `WuLiaoBiao` (
id int not null primary key AUTO_INCREMENT COMMENT '主键编号',
wuliaoName varchar(50) COMMENT '物料名',
gongId int COMMENT '供货商ID',
price int COMMENT '价格',
date date COMMENT '日期'
)ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT '物料表';
insert into WuLiaoBiao(wuliaoName,gongId,price,date) value('物料1',1,500,'2016-10-01');
insert into WuLiaoBiao(wuliaoName,gongId,price,date) value('物料1','1','200','2016-10-02');
insert into WuLiaoBiao(wuliaoName,gongId,price,date) value('物料1','2','300','2016-10-03');
insert into WuLiaoBiao(wuliaoName,gongId,price,date) value('物料1','2','800','2016-10-04');
insert into WuLiaoBiao(wuliaoName,gongId,price,date) value('物料1','2','100','2016-10-05');
insert into WuLiaoBiao(wuliaoName,gongId,price,date) value('物料2','2','190','2016-10-06');
insert into WuLiaoBiao(wuliaoName,gongId,price,date) value('物料2','2','150','2016-10-09');
insert into WuLiaoBiao(wuliaoName,gongId,price,date) value('物料2','1','100','2016-10-19');
insert into WuLiaoBiao(wuliaoName,gongId,price,date) value('物料2','1','200','2016-10-20');
insert into WuLiaoBiao(wuliaoName,gongId,price,date) value('物料2','1','400','2016-10-29');
select t1.id,t1.wuliaoName,t1.gongId,t1.price,t1.date from WuLiaoBiao t1,
(select wuliaoName,gongId,max(date) as date from WuLiaoBiao group by wuliaoName,gongId) t2
where t1.wuliaoName=t2.wuliaoName and t1.gongId=t2.gongId and t1.date=t2.date;运行结果
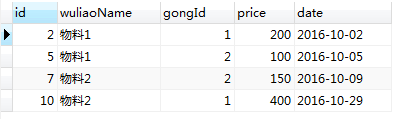
实现方式,依据【不分组必聚合原则】,因为需要查询的列有的不在聚合函数内,所以外层主查询不能分组。使用本身表以及该表的分组查询结果做自连接,where条件为分组查询的所有列(包括聚合函数列)和本身表做等值连接。
二、group by+case when
例子一 日期胜负表:
score 表:
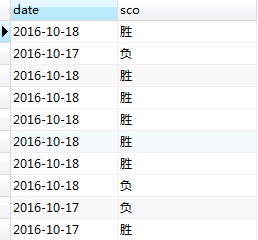
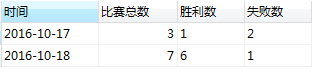
某球队需要做每天的比赛胜负数统计:
select date as 时间, count(1) as 比赛总数,
sum(case when sco='胜' then 1 else 0 end) 胜利数,
sum(case when sco="负" then 1 else 0 end) 失败数
from score group by date;或
select date as 时间, count(1) as 比赛总数,
sum(case sco when '胜' then 1 else 0 end) 胜利数,
sum(case sco when "负" then 1 else 0 end) 失败数
from score group by date;查询结果:
例子二 科目成绩(行转列):
数据表:
姓名 科目 分数
张三 语文 80
张三 数学 98
张三 英语 65
李四 语文 70
李四 数学 80
李四 英语 90
期望查询结果:
姓名 语文 数学 英语
张三 80 98 65
李四 70 80 90
代码
SQL 代码
create table testScore
(
tid int primary key AUTO_INCREMENT,
tname varchar(30) null,
ttype varchar(10) null,
tscor int null
)ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT '成绩表';
-- 插入数据
insert into testScore(tname,ttype,tscor) value('张三','语文',80);
insert into testScore(tname,ttype,tscor) value('张三','数学',98);
insert into testScore(tname,ttype,tscor) value('张三','英语',65);
insert into testScore(tname,ttype,tscor) value ('李四','语文',70);
insert into testScore(tname,ttype,tscor) value ('李四','数学',80);
insert into testScore(tname,ttype,tscor) value ('李四','英语',90);
select tname 姓名 ,
max(case ttype when '语文' then tscor else 0 end) 语文,
max(case ttype when '数学' then tscor else 0 end) 数学,
max(case ttype when '英语' then tscor else 0 end) 英语
from testScore
group by tname实例三 大州人口统计:
有如下数据:(为了看得更清楚,我并没有使用国家代码,而是直接用国家名作为Primary Key)
| 国家(country) | 人口(population) |
| 中国 | 600 |
| 美国 | 100 |
| 加拿大 | 100 |
| 英国 | 200 |
| 法国 | 300 |
| 日本 | 250 |
| 德国 | 200 |
| 墨西哥 | 50 |
| 印度 | 250 |
根据这个国家人口数据,统计亚洲和北美洲的人口数量。应该得到下面这个结果。
| 洲 | 人口 |
| 亚洲 | 1100 |
| 北美洲 | 250 |
| 其他 | 700 |
代码
SQL 代码
SELECT CASE country
WHEN '中国' THEN '亚洲'
WHEN '印度' THEN '亚洲'
WHEN '日本' THEN '亚洲'
WHEN '美国' THEN '北美洲'
WHEN '加拿大' THEN '北美洲'
WHEN '墨西哥' THEN '北美洲'
ELSE '其他' END AS 大州,
SUM(population) AS 人口总数
FROM country_pop
GROUP BY CASE country
WHEN '中国' THEN '亚洲'
WHEN '印度' THEN '亚洲'
WHEN '日本' THEN '亚洲'
WHEN '美国' THEN '北美洲'
WHEN '加拿大' THEN '北美洲'
WHEN '墨西哥' THEN '北美洲'
ELSE '其他' END;同样的,我们也可以用这个方法来判断工资的等级,并统计每一等级的人数。SQL代码如下;
SQL 代码
SELECT
CASE WHEN salary <= 500 THEN '1'
WHEN salary > 500 AND salary <= 600 THEN '2'
WHEN salary > 600 AND salary <= 800 THEN '3'
WHEN salary > 800 AND salary <= 1000 THEN '4'
ELSE NULL END salary_class,
COUNT(*)
FROM Table_A
GROUP BY
CASE WHEN salary <= 500 THEN '1'
WHEN salary > 500 AND salary <= 600 THEN '2'
WHEN salary > 600 AND salary <= 800 THEN '3'
WHEN salary > 800 AND salary <= 1000 THEN '4'
ELSE NULL END;对于groupby后面一般都是跟一个列名,但在该例子中通过case语句使分组变得跟强大了。
实例四 人口性别分组(行转列):
有如下数据
| 国家(country) | 性别(sex) | 人口(population) |
| 中国 | 1 | 340 |
| 中国 | 2 | 260 |
| 美国 | 1 | 45 |
| 美国 | 2 | 55 |
| 加拿大 | 1 | 51 |
| 加拿大 | 2 | 49 |
| 英国 | 1 | 40 |
| 英国 | 2 | 60 |
按照国家和性别进行分组,得出结果如下
| 国家 | 男 | 女 |
| 中国 | 340 | 260 |
| 美国 | 45 | 55 |
| 加拿大 | 51 | 49 |
| 英国 | 40 | 60 |
代码
SQL 代码
SELECT country,
SUM( CASE WHEN sex = '1' THEN
population ELSE 0 END), --男性人口
SUM( CASE WHEN sex = '2' THEN
population ELSE 0 END) --女性人口
FROM Table_A
GROUP BY country;GROUP BY子句中的NULL值处理
当GROUP BY子句中用于分组的列中出现NULL值时,将如何分组呢?SQL中,NULL不等于NULL(在WHERE子句中有过介绍)。然而,在GROUP BY子句中,却将所有的NULL值分在同一组,即认为它们是“相等”的。
三、HAVING子句
GROUP BY子句分组,只是简单地依据所选列的数据进行分组,将该列具有相同值的行划为一组。而实际应用中,往往还需要删除那些不能满足条件的行组,为了实现这个功能,SQL提供了HAVING子句。语法如下。
SELECT column, SUM(column)
FROM table
GROUP BY column
HAVING SUM(column) condition value说明:HAVING通常与GROUP BY子句同时使用。当然,语法中的SUM()函数也可以是其他任何聚合函数。DBMS将HAVING子句中的搜索条件应用于GROUP BY子句产生的行组,如果行组不满足搜索条件,就将其从结果表中删除。
HAVING子句的应用
从TEACHER表中查询至少有两位教师的系及教师人数。
实现代码:
SQL 代码
SELECT DNAME, COUNT(*) AS num_teacher
FROM TEACHER
GROUP BY DNAME
HAVING COUNT(*)>=2HAVING子句与WHERE子句的区别
HAVING子句和WHERE子句的相似之处在于,它也定义搜索条件。但与WHERE子句不同,HAVING子句与组有关,而不是与单个的行有关。
1、如果指定了GROUP BY子句,那么HAVING子句定义的搜索条件将作用于这个GROUP BY子句创建的那些组。
2、如果指定WHERE子句,而没有指定GROUP BY子句,那么HAVING子句定义的搜索条件将作用于WHERE子句的输出,并把这个输出看作是一个组。
3、如果既没有指定GROUP BY子句也没有指定WHERE子句,那么HAVING子句定义的搜索条件将作用于FROM子句的输出,并把这个输出看作是一个组。
4、在SELECT语句中,WHERE和HAVING子句的执行顺序不同。在本书的5.1.2节介绍的SELECT语句的执行步骤可知,WHERE子句只能接收来自FROM子句的输入,而HAVING子句则可以接收来自GROUP BY子句、WHERE子句和FROM子句的输入。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









