






一、基本信息
1.1 本次作业地址:https://edu.cnblogs.com/campus/ntu/Embedded_Application/homework/2088
1.2 项目的Git地址:https://gitee.com/ntucs/PairProg
二、项目分析
2.1 程序运行模块(方法、函数)介绍
①任务一:读取文件、统计行数写入result.txt方法
1 def process_file(dst): # 读文件到缓冲区 2 sum_info = {} 3 try: # 打开文件 4 f = open(dst, "r") 5 except IOError as e: 6 print (e) 7 return None 8 try: # 读文件到缓冲区 9 # 统计行数 10 lines = len(f.readlines()) 11 sum_info["file_row_count"] = lines 12 f.close() # 关闭文件 13 #重新打开文件 14 f = open(dst, "r") 15 bvffer = f.read() 16 except: 17 print ("Read File Error!") 18 return None 19 f.close() #关闭文件 20 sum_info["bvffer"] = bvffer 21 return sum_info
②任务一:使用正则表达式统计词频,存放如字典模块
1 def process_buffer(bvffer): 2 if bvffer: 3 word_freq = {} 4 # 下面添加处理缓冲区 bvffer代码,统计每个单词的频率,存放在字典word_freq 5 #文本字符串前期处理 6 strl_ist = bvffer.replace(punctuation, '').lower().split(' ') 7 #正则表达式规范 8 regex_str = "^[a-z]{4,}.{1,}" 9 #如果单词在字典里,则字典值加1,不在则添加该单词到字典里 10 for str in strl_ist: 11 if re.match(regex_str, str): 12 if str in word_freq.keys(): 13 word_freq[str] = word_freq[str] + 1 14 else: 15 word_freq[str] = 1 16 return word_freq
③任务一:保存排名前十结果至result.txt模块
1 # 保存结果到文件(result.txt) 2 def save_info(sorted_word_freq,lines): 3 try: 4 result_txt = open("result.txt", "w") # 以写模式打开,并清空文件内容 5 except Exception as e: 6 result_txt = open("result.txt", "x") # 文件不存在,创建文件并打开 7 8 result_txt.write("lines:" + lines + "\n") # 按行存储,添加换行符 9 result_txt.write("words:" +"10"+"\n") # 按行存储,添加换行符 10 11 for item in sorted_word_freq[:10]: 12 item = str(item).replace('(', '').replace(')', '').replace(',', ':').replace("'", "") 13 str1 = item.split(':') 14 str1 = "<" + str1[0] + ">:" + str1[1] 15 result_txt.write(str1 + "\n") # 按行存储,添加换行符 16 result_txt.close()
④任务一:主函数调用各个模块逻辑
1 if __name__ == "__main__": 2 #命令行传递参数 3 parser = argparse.ArgumentParser() 4 parser.add_argument('dst') 5 args = parser.parse_args() 6 dst = args.dst 7 #process_file接受参数 8 sum_info = process_file(dst) 9 # print(sum_info["file_row_count"]) 10 word_freq = process_buffer(sum_info["bvffer"]) 11 sorted_word_freq2 = output_result(word_freq) 12 lines = str(sum_info["file_row_count"]) 13 save_info(sorted_word_freq2,lines)
⑤任务二:停词表模块
功能实现方法:使用 nltk(Natural Language Toolkit,自然语言处理工具包,在NLP领域中,最常使用的一个Python库。)下载英文停词表,存放到list_stopWords集合中,接着对将要处理的英文单词进行判断是否与list_stopWords中的词汇相等,如果相等则跳过,即停词功能。
代码模块如下:
1 def process_buffer(bvffer): 2 if bvffer: 3 word_freq = {} 4 # 下面添加处理缓冲区 bvffer代码,统计每个单词的频率,存放在字典word_freq 5 #文本字符串前期处理 6 strl_ist = bvffer.replace(punctuation, '').lower().split(' ') 7 #英文停止词,set()集合函数消除重复项 8 nltk.download("stopwords") 9 list_stopWords = list(set(stopwords.words('english'))) 10 11 #如果单词在字典里,则字典值加1,不在则添加该单词到字典里 12 for str in strl_ist: 13 if str not in list_stopWords: 14 if str in word_freq.keys(): 15 word_freq[str] = word_freq[str] + 1 16 else: 17 word_freq[str] = 1 18 return word_freq
⑤任务二:列出高频短语模块
实现步骤: 使用 使用 nltk(Natural Language Toolkit,自然语言处理工具包,在NLP领域中,最常使用的一个Python库。)中Text的相关函数——collocations 列出文本中出现频率较高的双连词,如United States, Vice President。
实现代码如下:
1 #提取词组 2 def getcizu(): 3 # 这里设置自己的文件夹 4 corpus_root = 'D:\project_resPIDER\student_info' 5 wordlists=PlaintextCorpusReader(corpus_root, '.*',encoding='ISO-8859-1') 6 # 自行修改自己所设置文件夹下txt的名字 7 x=nltk.text.Text(wordlists.words('Gone_with_the_wind.txt')) 8 #改动20可以设置提取词组的数目 9 print(x.collocations(50, window_size=3))
2.2 程序算法时间、空间复杂度分析
针对任务2的主要逻辑模块停词表进行分析时间和空间复杂度。
假设停词表文件有N个单词,待分析的文本单词集合有n个单词,根据两个for循环分析,则该模块的时间复杂度大概为
O(N*n),又根据操作系统的空间内存重复调用可知,该模块的时间复杂度经优化后应该小于O(N*n)。
另一方面,该模块的空间复杂度由程序定义的list集合的容量决定,即停词表容量加待分析文本容量,大概为50k左右。
1 def process_buffer(bvffer):
2 if bvffer: 3 word_freq = {} 4 # 下面添加处理缓冲区 bvffer代码,统计每个单词的频率,存放在字典word_freq 5 #文本字符串前期处理 6 strl_ist = bvffer.replace(punctuation, '').lower().split(' ') 7 #英文停止词,set()集合函数消除重复项 8 nltk.download("stopwords") 9 list_stopWords = list(set(stopwords.words('english'))) 10 11 #如果单词在字典里,则字典值加1,不在则添加该单词到字典里 12 for str in strl_ist: 13 if str not in list_stopWords: 14 if str in word_freq.keys(): 15 word_freq[str] = word_freq[str] + 1 16 else: 17 word_freq[str] = 1 18 return word_freq
2.3 程序运行案例截图
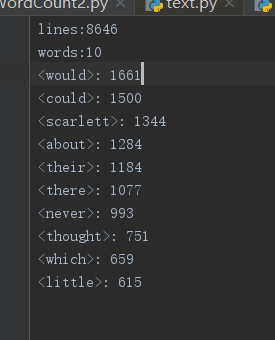
①任务1:result.txt截图
②任务2:停词表的使用与result2.txt截图

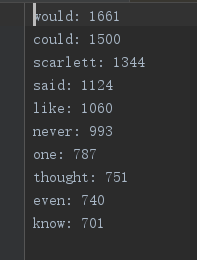
③任务2:高频词组截图(前30个)

三、性能分析
2.1 所花时间
任务一:

任务二:
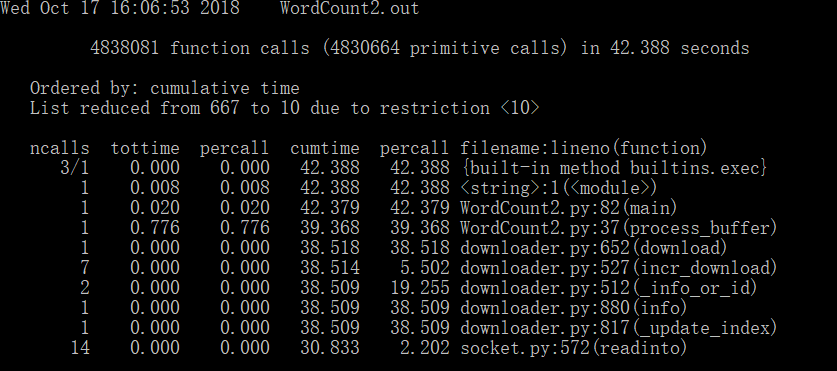
性能改进:根据上面任务二总运行时间截图可以得到,该模块运行时间冗长,长达至40s。经过分析可知停词表功能实现代码中,
每运行一次,下载一次nltk停词表。这是不必要的,所以讲下载停词表代码删去可得优化总运行时间。

如图对比可知,程序总运行时间显著减少了35s。
2.2 性能图表

四、其他
3.1 结队编程时间开销
每天1hour,大概一周左右完成全部功能。主要时间开销分两个部分——查阅
技术文档、结队编程大体分工为两位同学同时查阅技术文档,接着交流讨论。对各
个技术方式实践结队编程最后选择最合适的方案。
3.2 结队编程照片

五、事后分析与总结
4.1 提取高频短语——讨论过程
在解决任务2——提取高频短语时,我们两位同学在解决方法方面出现了分歧。
55号潘博提出 使用nltk中的collection方法,思考角度为“不重复造轮子”,并且该工具包已经发展成熟,
在使用过程中并不会产生程序问题。
56号侯磊同学提出 使用正则表达式,针对2个词汇的短语,与3个词汇的短语编写正则表达式,从文本中找出
符合要求的短语集合之后,进行短语统计(类似词频统计)。
最后,我们综合考虑是程序的时间复杂度,决定使用潘博同学的方法。
4.2 互相评价
潘博评价侯磊:侯磊同学虽然在编程方面基础不是很好,但是在合作的过程中积极为项目做贡献,在查阅资料与学习
方面不遗余力。美中不足的是对编写程序背后的逻辑方面,不够严谨,希望以后能够多加思考。
侯磊评价潘博:潘博同学不管在编程能力还是在技术储备方面都非常优秀,能够灵活运用已经学习的各门专业知识,
并且在代码编写与调试方面也非常熟练。在完成任务的同时,积极帮助我解答疑问,受益匪浅,期待下一次的合作。
4.3 评价整个过程
我们觉得,从本次作业完成的过程中,理解了软件工程不仅仅是一门关于程序编写与设计的学科,他还是一门包含“人”
的学科,甚至团队合作是软件开发中的至关重要的一环。
4.5 建议
①希望在课后作业的项目中能够包含 一些更“热门前言”的技术知识点,或者锻炼编程能力的算法。
②并且希望能够提高编程的比重,而减少博客编写的比重。相比于码字,我们更喜欢码代码。
③结队编程应该找能力相差不多的同学结队。
4.4 其他——总结思考
①.适用的项目
需要快速实现或功能逻辑复杂,研究型项目,缺少设计,设计简单。
②人员的选择
人员经验
开发经验至少两年以上,两个经验相当的程序员。
如果经验相差太多,容易造成一方的强势,另外一方弱势,不容易形成讨论的局面。
极限编程的基础在于开发团队的成员都是经验丰富,技术娴熟的。如果开发经验少于两年的人,对于团队合作,时间的管理,进度的把握,软件的构架经验欠缺。
人员性格
性格上有些程序员性格外向,有很多想法。有的性格内向,思维紧密。最好是有性格中性的两个人,其次是性格内向加一个性格外向的人,最糟糕的是看到两个性格外向的人再争吵,两个性格内向的人什么话也不说。
③.广义的结对和狭义的结对
狭义的理解:仅仅在编程时结对,两个人一起完成代码。
广义的理解:理解需求,设计时结对,编写主要功能时结对,重复性不重要的功能分开。最后再一起Review代码。















 1082
1082











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









