






本文讲述了如何使用代码模拟HTTP请求来实现数据爬取、点赞、评论回复等功能。
内容包括:
1.抓包软件WireShark的简单使用方法
2.Python库requests的基本使用
3.一个用代码回复博客的例子
一、思路阐述
首先,要模拟HTTP请求,我们要知道被模拟的真实HTTP它到底包含了哪些东西。它的目标URL是什么,参数是什么,是不是带cookie?除此之外还包括了哪些(比如Header)?
为了获取这些信息,我们可以使用抓包软件WireShark来捕获我们真实提交请求时的数据。
这里解释一下为什么要用WireShark?(Chrome浏览器本身其实也自带类似功能,有兴趣的朋友可以去研究下,但是我还是觉得抓包软件牛逼)
你可能觉得我要模拟HTTP请求来提交表单,只要看下网页源代码中的form表单有哪些字段就可以了。
没错,对于一些耿直的安全防护水平低的网站来说,这个方法确实可行。但对于大多数网站是行不通的。
拿某博客网站做例子,看到它源代码中有个表单域如下:

然而我开着抓包软件,在真实地完成一次评论操作后,获取到的POST请求是这样的:

当然,这可能是因为它的onsubmit中修改了参数名字。但是就算是你正确填写了参数名,可能也没法获得正确的结果。其中缘由,下文的例子会具体阐述。
通过抓包软件,我们获取到了真实的HTTP请求的内容(上面红字所提到的)。接下来就可以通过代码来模拟。当然,在模拟时肯定会碰到各种问题,这时候我们要做的就是比较模拟的包(即代码发送的包。你看,不用抓包软件你怎么去获取代码发送的请求?)和真实请求的包的内容,来完善代码(比如添加一些cookie、header等等)。
本文我使用Python来编写,用了它强大的requests 库来模拟。
OK,到这里大致思路已经清楚了:使用抓包软件获取真实HTTP请求的内容,并用python代码来模拟。接下来我们看一下怎么去使用WireShark获取我们需要的信息。
二、用抓包软件抓到我们想要的包
打开WireShark,看到主界面如下:
这时候选择一个正在使用的网络连接之后Start(开始抓包),然后出现如下的界面:
在这里我们看到各种各样的包,一会儿就把整个屏给刷满了。别急,我们给它做点过滤。
在Filter输入栏中输入过滤规则: ip.dst==116.213.120.41 and http.request.method=="POST"
解释一下:目标IP地址为116.... 以及 包内容为: 以POST方法提交的HTTP请求(关于过滤规则网上查一下比比皆是)
现在清爽多了是不是:
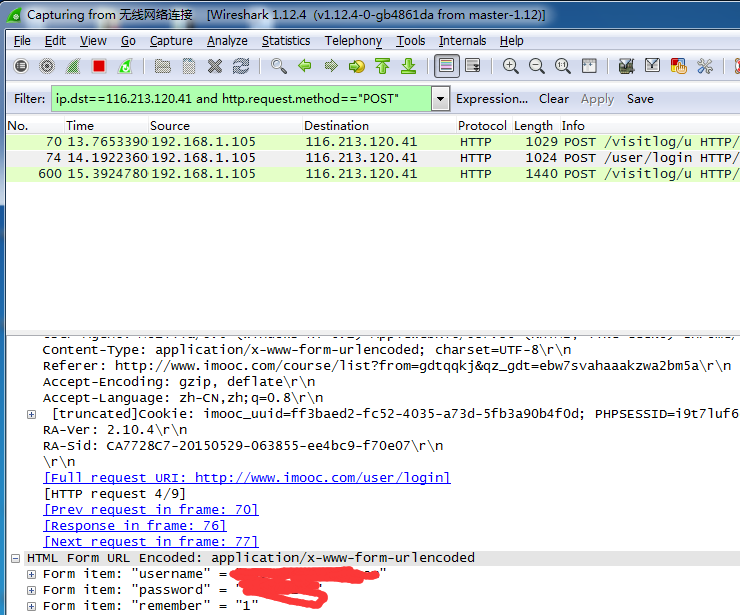
这里显示的是我真实登录慕课网所post的请求的内容。可以看到URL、提交的内容以及一些乱七八糟的信息。
有同学可能不清楚怎么获得慕课的IP:打开终端Ping一下慕课的网址就可以了,如下所示:
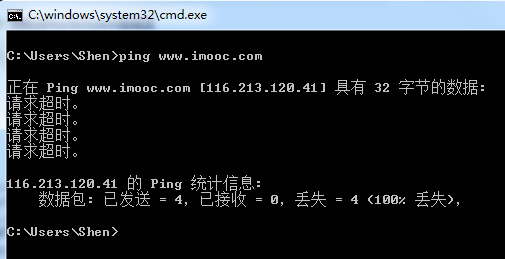
OK,到这里想必读者已经清楚如何利用WireShark来获取真实请求的包了。有了包的数据,接下来就要用代码来模拟了!
三、用代码来爬取数据、提交请求
本来想拿新浪博客做例子的。抓了下包看了内容吓哭了。也忒多了。还是拿某博客为例吧。
首先给个链接看看回复博客的效果:
http://blog.csdn.net/u012422829/article/details/46491779 这篇博客里抽风一样的评论有的是我之前做测试的时候真实提交的,有的是用代码提交的。
然后直接上代码:
[python] view plaincopy
import requests
from bs4 import BeautifulSoup
# coding="utf-8"
url = 'https://passport.csdn.net/account/login'
sess = requests.session()
print sess
html1 = sess.get(url).text
soup1 = BeautifulSoup(html1)
p1 = soup1.select("[name=lt]")[0]["value"]
p2 = soup1.select("[name=execution]")[0]["value"]
data = {
"lt": p1,
"execution": p2,
"_eventId": "submit",
"username": "your name",
"password": "your psw"
}
r = sess.post(url, data)
print r.text
#below is the code how to reply your blog
commentUrl="http://blog.csdn.net/u012422829/comment/submit?id=46491779"
html2 = sess.get(url).text
commentdata = {
"commentid":'',
"content":"I am excited that I can reply my blog by my python code!",
"replyId":'',
}
headers = {'content-type': 'application/x-www-form-urlencoded',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2272.118 Safari/537.36'}
sess.headers.update(headers)
r2 = sess.post(commentUrl, commentdata)
print r2.text
#below is the code how to crawl the info you want
msg = BeautifulSoup(sess.get('http://msg.csdn.net/').text)
for li in msg.select(".user_name"):
print li.text
#below is the code how to up your blog in the home page of CSDN
url3='http://blog.csdn.net/common/digg.html?id=46541445&blog=1248879&user=u012422829&action=up'
msg = BeautifulSoup(sess.get(url3).text)
print msg
关于登录代码的解释:
使用了Python强大的requests库来完成。有关这个库用法的介绍网上很多,读者可以自己去找找。
我先用抓包软件获取到了包的内容,确认了发送的表单内容之后,发现有3个隐藏域,于是直接从网站返回消息中获取。
一开始没有添加Header,发送的请求被拒绝处理(403Forbidden)。观察了两个包的内容,猜想可能是Header中User-Agent为Python脚本的原因,于是顺手把真实请求的Header复制下来,替换了User-Agent之后,成功登录。
看看爬下来的msg的输出:
可以看到我把所有消息的来源者的name爬下来了。
============写在后面====================================
爬其他网站数据也大同小异,不过很多都有反爬虫机制。比如刚刚试验知乎登录,一开始还可以,后来就被验证码弄的405ERR了,忧伤。
任何问题欢迎留言!
转载于:https://blog.51cto.com/hyman1994/1663677















 354
354











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









