






一、文章来由
这个乱码问题很早以前就发现了,其实就是编码的问题导致~~~
二、现象
新建一个文本文档,输入“联通”二字(不带引号),然后保存、关闭,再重新打开。你发现了什么?没错,“联通”二字已经变成了乱码“��ͨ”,那么为什么会产生这种情况呢?这就要涉及到字符编码的问题了。

三、原因
在计算机技术刚出现的时候,只有ASCII这一种字符集,但是随着技术的发展,ASCII明显不够用了,因为ASCII码一共只规定了128个字符的编码,英语是够用了,但是其他语言不行,于是就又产生了其他的编码标准,比如简体中文的是GB2312编码。但是由于每种语言都制定了自己的字符集,导致最后存在的各种字符集实在太多,在国际交流中要经常转换字符集非常不便。因此,提出了Unicode字符集,它固定使用16 bits(两个字节、一个字)来表示一个字符,共可以表示65536个字符。标准的Unicode称为UTF-16。后来为了双字节的Unicode能够在现存的处理单字节的系统上正确传输,出现了UTF-8。注意UTF-8是编码,它属于Unicode字符集。Unicode字符集有多种编码形式,而ASCII只有一种。
有人开玩笑说出现这个BUG的原因是中国联通把微软得罪了,这当然是玩笑话了,其实出现上述乱码问题的关键在于字符集。记事本保存的时候,默认使用ANSI编码,比如“联通二字的ASNI编码为:FF FE 6A 00 68 03 ,UTF-8编码为:FF FE 54 80 1A 90。可以看到ASNI编码和UTF-8编码的前面都是“FF FE”,于是问题就产生了。当你在记事本中输入“联通”二字并且保存后,它默认是以ASNI编码保存的。但是打开文档时使用的则是UTF-8编码,于是就产生了乱码。这是因为记事本不能判断你保存时的编码标准,而且它也不会问你使用了哪种标准,于是就靠“猜测”来判断你的编码标准,因为联通二字的ANSI编码正好是以“FF FE”开头的,这样以ANSI编码保存以后再次打开,记事本首先检测到“FF FE”,就认为是UTF-8编码了,于是按照UTF-8编码打开以后就会显示为乱码。于是不可避免就可能产生错误,像“联通”二字这样的情况,还有别的,比如“透支”二字。
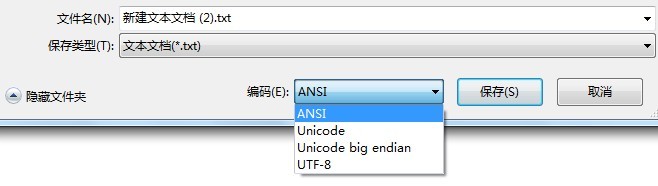
假设保存文档时选择另存为,编码格式选择UTF-8,那么你再打开那个文本文档时就不会发生乱码了。















 3818
3818











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









