






官网:https://dev.mysql.com/doc/refman/5.6/en/innodb-adaptive-hash.html
索引(Index)是帮助MySQL高效获取数据的数据结构。提取句子主干,就可以得到索引的本质:索引是数据结构。
从MySQL逻辑架构来看,MySQL有三层架构,第一层连接,第二层查询解析、分析、优化、视图、缓存,第三层,存储引擎。

索引通过分开查询片,节省了扫描查找时间,大大提升查询效率。
大部分数据库系统及文件系统都采用B-Tree或其变种B+Tree作为索引结构。
索引主要在存储引擎层上,不同的引擎也就有不同的B-Tree算法。
0x01.Hash Index
哈希索引只有Memory, NDB两种引擎支持,Memory引擎默认支持哈希索引,如果多个hash值相同,出现哈希碰撞,那么索引以链表方式存储。
但是,Memory引擎表只对能够适合机器的内存切实有限的数据集。
要使InnoDB或MyISAM支持哈希索引,可以通过伪哈希索引来实现,叫自适应哈希索引。
主要通过增加一个字段,存储hash值,将hash值建立索引,在插入和更新的时候,建立触发器,自动添加计算后的hash到表里。
直接索引
假如有一个非常非常大的表,如下:
CREATE TABLE IF NOT EXISTS `User` (
`id` int(10) NOT NULL COMMENT '自增id',
`name` varchar(128) NOT NULL DEFAULT '' COMMENT '用户名',
`email` varchar(128) NOT NULL DEFAULT '' COMMENT '用户邮箱',
`pass` varchar(64) NOT NULL DEFAULT '' COMMENT '用户密码',
`last` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '最后登录时间'
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
这个时候,比如说,用户登陆,我需要通过email检索出用户,通过explain得到如下:
mysql> explain SELECT id FROM User WHERE email = ‘ooxx@gmail.com’ LIMIT 1;
+----+-------------+-------+------+---------------+------+---------+------+--------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+------+---------------+------+---------+------+--------+-------------+ | 1 | SIMPLE | User | ALL | NULL | NULL | NULL | NULL | 384742 | Using where | +----+-------------+-------+------+---------------+------+---------+------+--------+-------------+
发现 rows = 384742 也就是要在384742里面进行比对email这个字段的字符串。
这条记录运行的时间是:Query took 0.1744 seconds,数据库的大小是40万。
从上面可以说明,如果直接在email上面建立索引,除了索引区间匹配,还要进行字符串匹配比对,email短还好,如果长的话这个查询代价就比较大。
如果这个时候,在email上建立哈希索引,查询以int查询,性能就比字符串比对查询快多了。
Hash 算法
建立哈希索引,先选定哈希算法,这里选用CRC32。
《高性能MySQL》说到的方法CRC32算法,建立SHA或MD5算法是划算的,本身位数都有可能比email段长了。
INSERT UPDATE SELECT 操作
在表中添加hash值的字段:
mysql> ALTER TABLE User ADD COLUMN email_hash int unsigned NOT NULL DEFAULT 0;
接下来就是在UPDATE和INSERT的时候,自动更新 email_hash 字段,通过MySQL触发器实现:
DELIMITER |
CREATE TRIGGER user_hash_insert BEFORE INSERT ON `User` FOR EACH ROW BEGIN
SET NEW.email_hash=crc32(NEW.email);
END;
|
CREATE TRIGGER user_hash_update BEFORE UPDATE ON `User` FOR EACH ROW BEGIN
SET NEW.email_hash=crc32(NEW.email);
END;
|
DELIMITER ;
这样的话,我们的SELECT请求就会变成这样:
mysql> SELECT email, email_hash FROM User WHERE email_hash = CRC32(“F2dgTSWRBXSZ1d3O@gmail.com”) ANDemail = “F2dgTSWRBXSZ1d3O@gmail.com”;
+----------------------------+------------+
| email | email_hash |
+----------------------------+------------+
| F2dgTSWRBXSZ1d3O@gmail.com | 2765311122 |
+----------------------------+------------+
在没建立hash索引时候,请求时间是 0.2374 seconds,建立完索引后,请求时间直接变成 0.0003 seconds。
AND email = "F2dgTSWRBXSZ1d3O@gmail.com" 是为了防止哈希碰撞导致数据不准确。
0x02.Hash Index 缺点
哈希索引也有几个缺点:
- 索引存放的是hash值,所以仅支持 < = > 以及 IN 操作
- hash索引无法通过操作索引来排序,因为存放的时候经过hash计算,但是计算的hash值和存放的不一定相等,所以无法排序
- 不能避免全表扫描,只是由于在memory表里支持非唯一值hash索引,就是不同的索引键,可能存在相同的hash值
- 如果哈希碰撞很多的话,性能也会变得很差
- 哈希索引无法被用来避免数据的排序操作
警惕 InnoDB 和 MyISAM 创建 Hash 索引陷阱
MySql 最常用存储引擎 InnoDB 和 MyISAM 都不支持 Hash 索引,它们默认的索引都是 B-Tree。但是如果你在创建索引的时候定义其类型为 Hash,MySql 并不会报错,而且你通过 SHOW CREATE TABLE 查看该索引也是 Hash,只不过该索引实际上还是 B-Tree。
比如表 data_dict 的 DDL:
- CREATE TABLE `data_dict` (
- `data_type` varchar(32) NOT NULL COMMENT '数据字典类型',
- `data_code` tinyint(4) NOT NULL COMMENT '数据字典代码',
- `data_name` varchar(64) NOT NULL COMMENT '数据字典值',
- PRIMARY KEY (`data_type`,`data_code`)
- ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='数据字典表';
我们为 data_name 字段建立 Hash 索引:
- ALTER TABLE data_dict ADD INDEX data_dict_dn USING HASH (data_name);
打印结果:
受影响的行: 0
时间: 0.345s
然后查看建表 DDL:
- SHOW CREATE TABLE data_dict;
打印结果:
CREATE TABLE `data_dict` (
`data_type` varchar(32) NOT NULL COMMENT '数据字典类型',
`data_code` tinyint(4) NOT NULL COMMENT '数据字典代码',
`data_name` varchar(64) NOT NULL COMMENT '数据字典值',
PRIMARY KEY (`data_type`,`data_code`),
KEY `data_dict_dn` (`data_name`) USING HASH
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='数据字典表'
是 Hash,所以我们以为创建 Hash 索引成功。
事实上并非如此,我们都被 MySql 给骗了,我们使用 SHOW INDEXES FROM 语句对该表索引进行检索:
- SHOW INDEXES FROM data_dict;
打印结果:

打回原形了。不过也不要失望,虽然常见存储引擎并不支持 Hash 索引,但 InnoDB 有另一种实现方法:自适应哈希索引。InnoDB 存储引擎会监控对表上索引的查找,如果观察到建立哈希索引可以带来速度的提升,则建立哈希索引。
我们可以通过 SHOW ENGINE INNODB STATUS 来查看当前自适应哈希索引的使用状况:
=====================================
2015-07-07 10:51:19 1d68 INNODB MONITOR OUTPUT
=====================================
Per second averages calculated from the last 36 seconds
......
-------------------------------------
INSERT BUFFER AND ADAPTIVE HASH INDEX
-------------------------------------
Ibuf: size 1, free list len 2633, seg size 2635, 0 merges
merged operations:
insert 0, delete mark 0, delete 0
discarded operations:
insert 0, delete mark 0, delete 0
Hash table size 348731, node heap has 2 buffer(s)
0.00 hash searches/s, 0.00 non-hash searches/s
......
从中我们可以看到自适应哈希索引的相关信息:有使用大小、使用情况、每秒使用自适应哈希索引搜索的情况等。
MySql 各种存储引擎的特性对比详单:
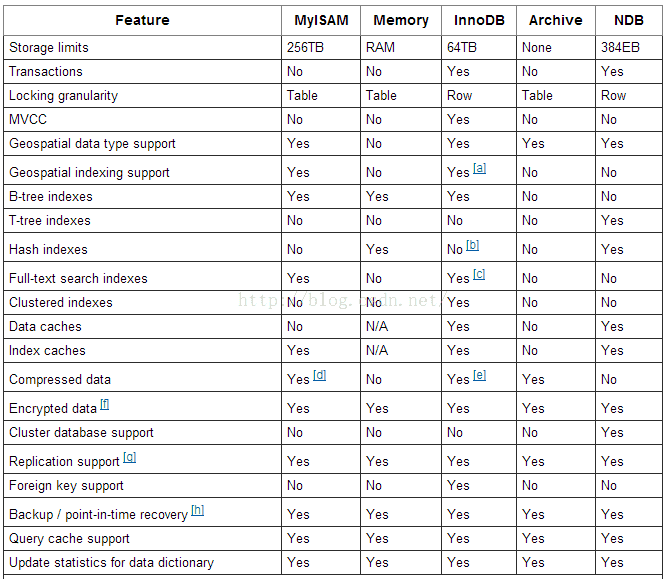
从中我们可以看出,
- InnoDB 支持事务,支持行级别锁定,支持 B-tree、Full-text 等索引,不支持 Hash 索引;
- MyISAM 不支持事务,支持表级别锁定,支持 B-tree、Full-text 等索引,不支持 Hash 索引;
- Memory 不支持事务,支持表级别锁定,支持 B-tree、Hash 等索引,不支持 Full-text 索引;
- NDB 支持事务,支持行级别锁定,支持 Hash 索引,不支持 B-tree、Full-text 等索引;
- Archive 不支持事务,支持表级别锁定,不支持 B-tree、Hash、Full-text 等索引;
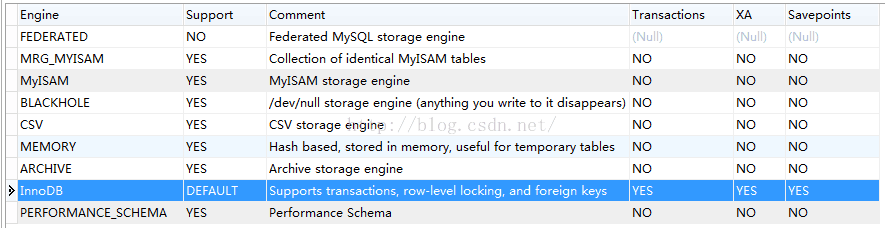
从中可以看出,InnoDB 是该版本 MySql 的默认存储引擎,也只有 InnoDB 能够支持事务、行级别锁定、外键;支持的 MEMORY 是基于哈希的,数据都存放于内存,适用于临时表。没有看到既支持事务又支持哈希索引的 NDB 的身影。
为印证默认的存储引擎,我们创建一个测试表 data_dict_test,注意建表语句里没有定义存储引擎:
- CREATE TABLE `data_dict_test` (
- `data_type` varchar(32) NOT NULL COMMENT '数据字典类型',
- `data_code` tinyint(4) NOT NULL COMMENT '数据字典代码',
- `data_name` varchar(64) NOT NULL COMMENT '数据字典值',
- PRIMARY KEY (`data_type`,`data_code`)
- ) DEFAULT CHARSET=utf8 COMMENT='数据字典表';
[SQL] CREATE TABLE `data_dict_test` (
`data_type` varchar(32) NOT NULL COMMENT '数据字典类型',
`data_code` tinyint(4) NOT NULL COMMENT '数据字典代码',
`data_name` varchar(64) NOT NULL COMMENT '数据字典值',
PRIMARY KEY (`data_type`,`data_code`)
) DEFAULT CHARSET=utf8 COMMENT='数据字典表';
受影响的行: 0
时间: 0.262s
然后查看建表 DDL:
- SHOW CREATE TABLE data_dict_test;
CREATE TABLE `data_dict_test` (
`data_type` varchar(32) NOT NULL COMMENT '数据字典类型',
`data_code` tinyint(4) NOT NULL COMMENT '数据字典代码',
`data_name` varchar(64) NOT NULL COMMENT '数据字典值',
PRIMARY KEY (`data_type`,`data_code`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='数据字典表'
这次 SHOW CREATE TABLE 没有欺骗我们,明确给出的就是 InnoDB,虽然我们建表时没有指定。
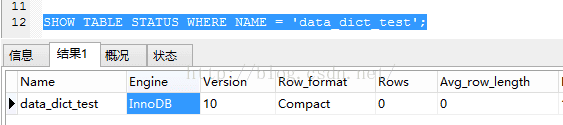
笔者建议使用 SHOW TABLE STATUS 语句来查看特定表的存储引擎:
- SHOW TABLE STATUS WHERE NAME = 'data_dict_test';
参考资料
- http://dev.mysql.com/doc/refman/5.6/en/storage-engines.html
- http://dba.stackexchange.com/questions/2817/why-does-mysql-not-have-hash-indices-on-myisam-or-innodb


<><><>
<>























 8819
8819

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









