







1、下载hadoop-eclipse-plugin-2.7.3插件,并解压
2、将hadoop-eclipse-plugin-2.7.3.jar拷贝到${ECLIPSE_HOME}下的plugins文件夹,
并重启eclipse,即可出现以下视图:
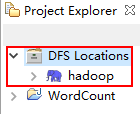
3、将hadoop-eclipse-plugin-2.7.3下的bin目录所有文件拷贝到window下的Hadoop目录下的bin目录中
4、同时将bin目录下的hadoop.dll拷贝到C:\windows\system32目录下
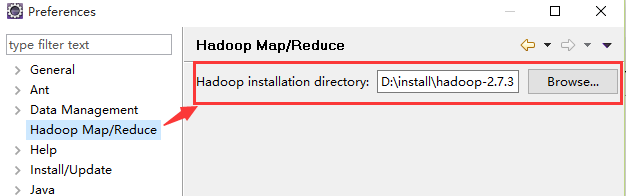
5、eclipse配置hadoop安装目录
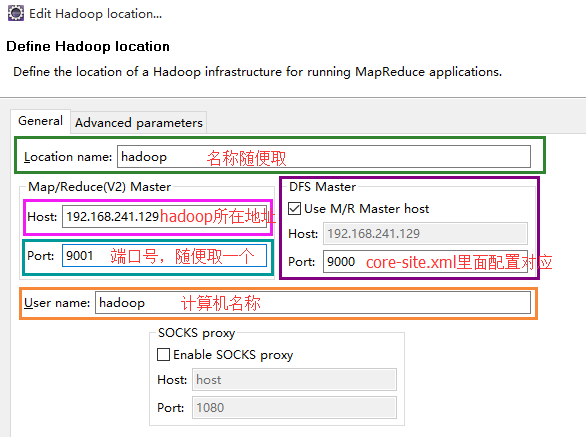
6、创建Hadoop Location
7、运行WordCount实例
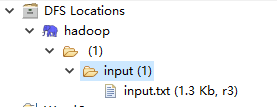
1. 创建输入目录input,并上传数据文件input.txt,不可创建输出文件夹,不然会报错。
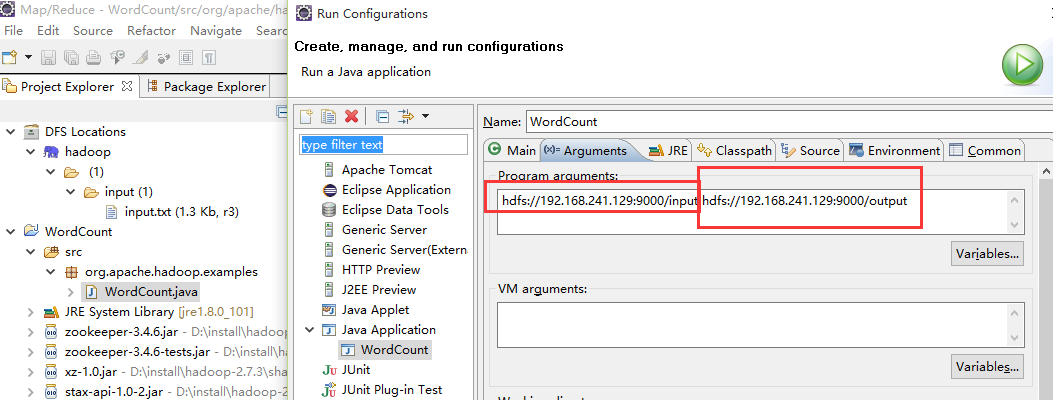
2. 配置运行参数(如下图),最后点击run即可
说明:input指的的文件夹,直接挂在"/"目录下,与hdfs://192.168.241.129:9000/input对应
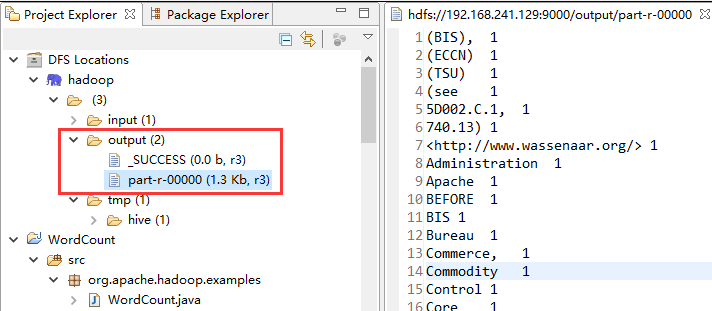
3. 输入结果如下图
4. 附:WordCount.java源码
package com.hadoop.example;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public static class TokenizerMapper extends
Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer extends
Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
System.setProperty("HADOOP_USER_NAME", "root");
System.setProperty("hadoop.home.dir", "D:/install/hadoop-2.7.3");
// System.setProperty("yarn.resourcemanager.address", "master:8032");
System.setProperty("yarn.resourcemanager.hostname", "master");
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args)
.getRemainingArgs();
if (otherArgs.length < 2) {
System.err.println("Usage: wordcount <in> [<in>...] <out>");
System.exit(2);
}
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
for (int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job, new Path(
otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
5、可打成Runnable JarFile包运行
#可运行包执行命令:hadoop jar {jar} {input} {output}
hadoop jar WordCount.jar hdfs://192.168.241.129:9000/input hdfs://192.168.241.129:9000/output















 4909
4909











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









