







第一步
在D盘下创建Hadoop目录,将Hadoop-2.6.5复制到Hadoop目录下。
(1)复制hadoop-eclipse-plugin-2.5.2.jar 到 eclipse安装目录/plugins/ 下,把hadoop.dll放到c:/windows/system32下,把winutils.exe放到Hadoop的安装目录如D:\Hadoop\hadoop-2.6.5\bin\下替换原有的winutils.exe文件

(2)重启eclipse,配置hadoop installation directory。 如果安装插件成功,打开Window–>Preferences,你会发现Hadoop Map/Reduce选项,在这个选项里你需要配置Hadoop installation directory。配置完成后退出。
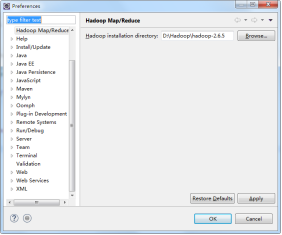
(3)配置Map/Reduce Locations。
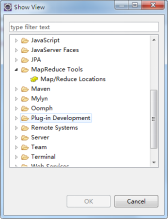
在Window–>Show View中打开Map/Reduce Locations。
修改yarn-site.xml(Linux下的)
<property>
<name>yarn-resourcemanager.scheduler.address</name>
<value>192.168.142.139:8030</value>
</property>
core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop:9000</value>
</property>
(5)如下图,点击右下角,在弹出的对话框中你需要配置Location name,如设置名称为Hadoop,还要配置Map/Reduce Master和DFS Master。这里面的Host、Port分别为你在yarn-site.xml、core-site.xml中配置的地址及端口,User name是虚拟机的名字,如hadoop。


(6)配置完后点击Finish退出。点击DFS Locations–>Hadoop如果能显示文件夹,说明配置正确,如果显示"拒绝连接",请检查你的配置或防火墙是否关闭。

注意:这时一定要关闭linux防火墙,如果不加的话会连接不上。
(7)上传模拟数据文件夹。
通过Hadoop的命令在HDFS上创建目录/hdfs,命令如下
[root@hdoop Desktop]# hdfs dfs –mkdir /hdfs
然后我们在eclipse上单击“DFS Locations”右键选择“reconnect”下,然后发现文件夹变成(4)了,如图所示。

eclipse连接虚拟机
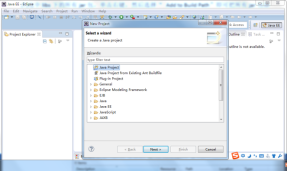
(1)打开 Eclipse开发工具,单击File选择“New”→“Java project”,新建名称为“ Hadoop的Java项目,单击右键“ hadoop项目,选择“New”→“ Package”,如图所示。
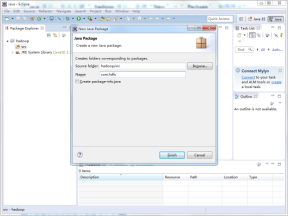
(2)输入包名称“ com.hdfs”,单击“Finish”按钮,如图所示。
(3)新建java类,选中包名并单击右键,选择“New”→“ Class”,如图所示。
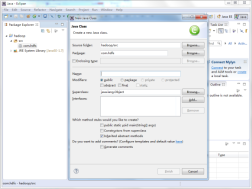
(4)在name项输入“HdfsTest " 类名称,单击" Finish”按钮完成,如图所示。
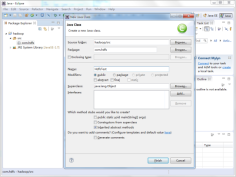
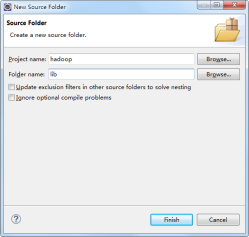
(5)在创建的项目目录下创建文件夹lib,通过选中文件夹“src”并点击右键,选择“New”→“SourceFolder”,在“Folder name”项输入lib,然后点击“finish”,如图所示。
(6)拷贝第五章实验资料下Hadoop jar文件夹下的所有 hadoop的 jar包到lib文件夹下
(7)选中lib下的所有jar包,单击右键,然后选择”Add to Build Path”,即可把所有jar包添加到path环境中。
(8)编写程序。
package com.hadoopdemo1;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.junit.Before;
import org.junit.Test;
public class HdfsTest {
// 获取HADOOP FileSystem对象
private FileSystem fs = null;
/*
* 初始化环境变量
*/
@Before
public void init() throws Exception {
/*
* new URI(“hdfs://192.168.11.128:9000”) 连接HDFS new Configuration()
* 使用HADOOP默认配置 “root” 登录用户
*/
fs = FileSystem.get(
new URI("hdfs://192.168.142.139:9000"), new Configuration(), "root");
}
/*
* 创建目录
*/
@Test
public void testMkdir() throws Exception {
boolean flag = fs.mkdirs(new Path("/javaApi/"));
System.out.println(flag ? "创建成功" : "创建失败");
}
}
(10)在项目栏目最右侧,选中要运行的方法“testMkdir”,单击右键,弹出菜单,选择“Run As Junit”→“Test”,等待执行结果,如图所示。

(11)显示运行结果,如图所示。
(11) 在浏览器上输入“192.168.142.139:50070”,查看是不是多了一个文件夹。
注意:要想执行上面的创建目录代码,必须关闭Linux的防火墙
读写文件
1.写文件
package com.hadoopdemo1;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.junit.Test;
public class HdfsWrite {
// 获取HADOOP FileSystem对象
private FileSystem fs = null;
/**
* 写文件
*
* new URI("hdfs://192.168.142.139:9000") 连接HDFS new Configuration()
* * 使用HADOOP默认配置 "root" 登录用户 FSDataOutputStream数据输出流
*
* */
@Test
public void WriteFile() throws Exception {
FileSystem hdfs = FileSystem.get(
new URI("hdfs://192.168.142.139:9000"), new Configuration(), "root");
Path dfs = new Path("/hdfs/ss.txt");
FSDataOutputStream out = hdfs.create(dfs);
out.writeUTF("cccc");
}
}
2.读文件
package com.hadoopdemo1;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.junit.Test;
public class HdfsRead {
// 获取HADOOP FileSystem对象
private FileSystem fs = null;
/**
* 读文件
* */
@Test
public void ReadFile() throws Exception {
Configuration conf = new Configuration();
FileSystem hdfs = FileSystem.get(
new URI("hdfs://192.168.142.139:9000"), conf, "root");
Path dfs = new Path("/hdfs/ss.txt");
FSDataInputStream input = hdfs.open(dfs);
System.out.print("myfile:" + input.readUTF());
input.close();
}
}
创建文件
package com.hadoopdemo1;
import java.io.ByteArrayInputStream;
import java.io.InputStream;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.junit.Test;
public class HdfsCreateFile {
// 获取HADOOP FileSystem对象
private FileSystem fs = null;
/**
* 创建文件
*/
@Test
public void CreateFile() throws Exception {
Configuration conf = new Configuration();
FileSystem hdfs = FileSystem.get(
new URI("hdfs://192.168.142.139:9000"), conf, "root");
Path dfs = new Path("/hdfs/new.txt");
FSDataOutputStream outputStream = hdfs.create(dfs);
InputStream in = new ByteArrayInputStream("Hello!Hadoop HDFS".getBytes("UTF-8"));
IOUtils.copyBytes(in, outputStream, 4096, true);
}
}
复制文件
1.本地文件复制到HDFS
如果要将文件从本地系统复制到HDFS中,可使用copyFromLocalFile()方法。
public void copyFromLocalFile(Path srcPath,Path dstPath)
此方法第一个参数要求必须是本地文件,第二个必须是HDFS文件。
public class CopyFromLocalFile {
/*
* 复制本地文件到HDFS
*/
@Test
public void testCopyFromLocalFile() throws Exception {
Configuration conf = new Configuration();
FileSystem hdfs = FileSystem.get(
new URI("hdfs://192.168.142.139:9000"), conf, "root");
Path srcFile = new Path("D:\\ebook_mysql.sql");
Path dstFile = new Path("/hdfs/ebook.txt");
hdfs.copyFromLocalFile(srcFile, dstFile);
}
}
2.HDFS文件复制到本地
如果要将文件从HDFS复制到本地系统中,可使用copyToLocalFile()方法。
public void copyToLocalFile(Path dstPath, Path srcPath)
public class CopyToLocalFile {
/*
* 复制HDFS到本地文件
*/
@Test
public void testCopyFromLocalFile() throws Exception {
Configuration conf = new Configuration();
FileSystem hdfs = FileSystem.get(
new URI("hdfs://192.168.142.139:9000"), conf, "root");
Path dstFile = new Path("D:\\ebook_mysql2.sql");
Path srcFile = new Path("/hdfs/ebook.txt");
hdfs.copyToLocalFile(srcFile, dstFile);
}
}
5.3.8 删除文件
public boolean delete(Path f,boolean recursive);
参数2 recursive表示是否进行递归删除。如果f是一个文件或空目录,那么recursive的值就会被忽略。
public class HdfsDeleteFile {
// 获取HADOOP FileSystem对象
private FileSystem fs = null;
/**
* 删除文件
*/
@Test
public void DeleteFile() throws Exception {
Configuration conf = new Configuration();
FileSystem hdfs = FileSystem.get(
new URI("hdfs://192.168.142.139:9000"), conf, "root");
Path dfs = new Path("/hdfs/new.txt");
hdfs.delete(dfs,true);
}
}
文件查询
FileStatus封装了文件的元数据,通过这个对象可以获得文件路径,文件大小等信息。
public class HdfsFileStatus {
// 获取HADOOP FileSystem对象
private FileSystem fs = null;
/**
* 文件信息
* */
@Test
public void ReadFile() throws Exception {
Configuration conf = new Configuration();
FileSystem hdfs = FileSystem.get(new URI("hdfs://192.168.142.139:9000"), conf, "root");
Path dfs = new Path("/hdfs/ss.txt");
FileStatus stat = hdfs.getFileStatus(dfs);
System.out.println("文件路径:"+stat.getPath());
System.out.println("文件大小:"+stat.getLen());
System.out.println("副本数量:"+stat.getReplication());
System.out.println("用户:"+stat.getOwner());
System.out.println("权限:"+stat.getPermission().toString());
}
}
如果我们希望列出HDFS目录下的文件,可以使用listStatus()方法列出目录内容。
public class HdfsListFileStatus {
// 获取HADOOP FileSystem对象
private FileSystem fs = null;
/**
* 列出文件信息
* */
@Test
public void ReadFile() throws Exception {
Configuration conf = new Configuration();
FileSystem hdfs = FileSystem.get(
new URI("hdfs://192.168.142.139:9000"), conf, "root");
Path dfs = new Path("/hdfs");
FileStatus[] states = hdfs.listStatus(dfs);
for(FileStatus stat:states){
System.out.println(stat.getPath());
}
}
}
重命名文件
public class HdfsRenameFile {
// 获取HADOOP FileSystem对象
private FileSystem fs = null;
/**
* 删除文件
*/
@Test
public void DeleteFile() throws Exception {
Configuration conf = new Configuration();
FileSystem hdfs = FileSystem.get(
new URI("hdfs://192.168.142.139:9000"), conf, "root");
Path src = new Path("/hdfs/ss.txt");
if(hdfs.exists(src)){
Path dst = new Path("/hdfs/new2.txt");
hdfs.rename(src, dst);
}
else{
System.out.println("文件不存在!!!");
}
}
}















 4581
4581











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









