







1.压缩
压缩在大数据中的优势:减少储存文件所需要的磁盘空间,并加速数据在网络和磁盘上的传输。
压缩格式:
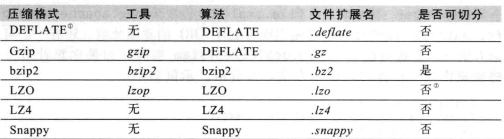
Gzip和bzip2比较时,bzip2的压缩率(压缩之后的大小除以源文件的大小)要小,所以说bzip2的压缩效果好。而这里就会压缩和解压缩的时候浪费更多的时间。
2.编解码工具
codec实现了一种压缩和解压缩算法(意思就是codec使用相关的算法对数据进行编码和解码)。在Hadoop中,一个对CompressionCodec接口的实现代表一个codec。
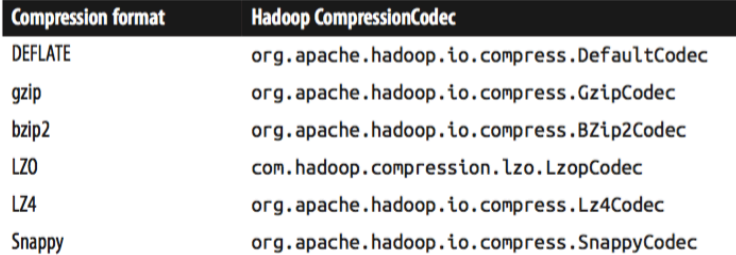
对于不同的压缩算法有不同的编解码工具。获取编解码工具的方式有两种,1是根据文件扩展名让程序自己去选择相应的编解码工具,2是直接指定编解码工具。
3.java编程操作文件压缩和解压缩
1.实现编解码的流程,是在对文件读写时在流中对文件进行编码和解码。
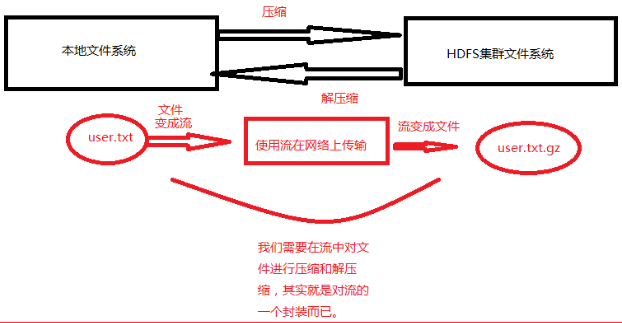
2. 编解码相关的类或方法

CompressionCodec接口中

CompressionCodecFactory类

3.代码实例
实例1:将本地文件上传压缩到HDFS集群中
package com.jf.hdfs;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.LocalFileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.compress.CompressionCodec;
import org.apache.hadoop.io.compress.CompressionCodecFactory;
import org.apache.hadoop.io.compress.CompressionOutputStream;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class WriteComPressionFile extends Configured implements Tool {
public int run(String[] args) throws Exception {
Configuration conf = getConf();
String input = conf.get("input");
String output = conf.get("output");
// 本地文件系统
LocalFileSystem lfs = FileSystem.getLocal(conf);
// 集群文件系统
FileSystem fs = FileSystem.get(URI.create(output), conf);
// 读取本地文件的输入流
FSDataInputStream is = lfs.open(new Path(input));
// 向集群写文件的输出流
FSDataOutputStream os = fs.create(new Path(output));
CompressionCodecFactory ccf = new CompressionCodecFactory(conf);
// 根据文件后缀名选择编解码工具
CompressionCodec codec = ccf.getCodec(new Path(output));
// 代编解码工具的输出流
CompressionOutputStream cos = codec.createOutputStream(os);
IOUtils.copyBytes(is, cos, 1024, true);
// 输出选择的编解码工具名称
System.out.println(codec.getClass().getName());
return 0;
}
public static void main(String[] args) throws Exception {
System.exit(ToolRunner.run(new WriteComPressionFile(), args));
}
}
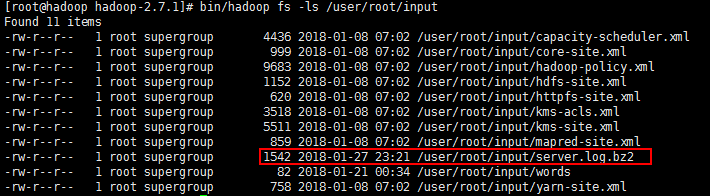
执行测试:上传server.log文件到集成环境中并命名为server.log.bz2
hadoop-2.7.1/bin/hadoop jar my_hadoop-0.0.1-SNAPSHOT.jar com.jf.hdfs.WriteComPressionFile -Doutput=/user/root/input/server.log.bz2 -Dinput=/home/softwares/server.log执行结果:输出使用的编解码工具

查看集群内上传路径:
实例2:将实例1中上传的文件解压到本地环境
package com.jf.hdfs;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.LocalFileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.compress.CompressionCodec;
import org.apache.hadoop.io.compress.CompressionCodecFactory;
import org.apache.hadoop.io.compress.CompressionInputStream;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class ReadCompressionFile extends Configured implements Tool {
public int run(String[] args) throws Exception {
Configuration conf = getConf();
String input = conf.get("input");
String output = conf.get("output");
// 本地文件系统
LocalFileSystem lfs = FileSystem.getLocal(conf);
// 集群文件系统
FileSystem fs = FileSystem.get(URI.create(input), conf);
// 本地文件输出流
FSDataOutputStream os = lfs.create(new Path(output));
// 集群文件输入流
FSDataInputStream is = fs.open(new Path(input));
//获取转码工具
CompressionCodecFactory ccf = new CompressionCodecFactory(conf);
CompressionCodec codec = ccf.getCodec(new Path(input));
//代转码器的输入流
CompressionInputStream cis = codec.createInputStream(is);
IOUtils.copyBytes(cis, os, 1024, true);
System.out.println(codec.getClass().getName());
return 0;
}
public static void main(String[] args) throws Exception {
System.exit(ToolRunner.run(new ReadCompressionFile(), args));
}
}
执行测试:下载实例1上传的server.log.bz2文件到本地目录为server2.log
hadoop-2.7.1/bin/hadoop jar my_hadoop-0.0.1-SNAPSHOT.jar com.jf.hdfs.ReadCompressionFile -Doutput=/home/softwares/server2.log -Dinput=/user/root/input/server.log.bz2查看本地文件夹下文件是否存在















 169
169











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









