






环境:Linux, 8G 内存。60G 硬盘 , Hadoop 2.2.0
为了构建基于Yarn体系的Spark集群。先要安装Hadoop集群,为了以后查阅方便记录了我本次安装的详细步骤。
事前准备
- 192.168.1.1 #hadoop1 : master
- 192.168.1.2 #hadoop2 : datanode1
- 192.168.1.3 #hadoop3: datanode2
- 192.168.1.1 hadoop1
- 192.168.1.2 hadoop2
- 192.168.1.3 hadoop3
这也是短域名实现的方式。
$mkdir -p /hadoop/hdfs
$mkdir -p /hadoop/tmp
$mkdir -p /hadoop/log
$mkdir -p /usr/java ###java安装路径
$mkdir -p /usr/hadoop ###hadoop安装路径
$chmod -R 777 /hadoop能够依据自己的情况确定安装路径。
安装Java
本次下载 jdk-7u60-linux-x64.tar.gz
$tar -zxvf jdk-7u60-linux-x64.tar.gz
$mv jdk1.7.0_60 java$source .bash_profile$ java -version
java version "1.7.0_60"
Java(TM) SE Runtime Environment (build 1.7.0_60-b19)
Java HotSpot(TM) 64-Bit Server VM (build 24.60-b09, mixed mode)配置SSH 无password登录
$ mkdir .ssh
$ cd .ssh
$ ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/export/home/zilzhang/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in ~/.ssh/id_rsa.
Your public key has been saved in ~/.ssh/id_rsa.pub.
The key fingerprint is:
b0:76:89:6a:44:8b:cd:fc:23:a4:3f:69:55:3f:83:e3 ...
$ ls -lrt
total 2
-rw------- 1 887 Jun 30 02:10 id_rsa
-rw-r--r-- 1 232 Jun 30 02:10 id_rsa.pub
$ touch authorized_keys
$ cat id_rsa.pub >> authorized_keys
hadoop2和hadoop3上。相同生成公钥和私钥。
[hadoop2]$ mv id_rsa.pub pub2
[hadoop3]$ mv id_rsa.pub pub3把pub2,pub3都scp到hadoop1上,然后
$ cat pub2 >> authorized_keys
$ cat pub3 >> authorized_keys
把authorized_keys scp到hadoop2和hadoop3上。这样就能够免password登录了。
一言以蔽之,就是在每台node上生成公钥和私钥,把全部公钥的内容汇总成authorized_keys,并把authorized_keys分发到集群全部node上同样的文件夹,这样每一个node都拥有整个集群node的公钥。互相之间就能够免password登录了。
验证免password登录。在hadoop1上:
$ ssh haoop1
ssh: Could not resolve hostname haoop1: Name or service not known
[zilzhang@hadoop3 hadoop]$ ssh hadoop1
The authenticity of host 'hadoop1 (192.168.1.1)' can't be established.
RSA key fingerprint is 18:85:c6:50:0c:15:36:9c:55:34:d7:ab:0e:1c:c7:0f.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'hadoop1' (RSA) to the list of known hosts.
#################################################################
# #
# This system is for the use of authorized users only. #
# Individuals using this computer system without #
# authority, or in excess of their authority, are #
# subject to having all of their activities on this #
# system monitored and recorded by system personnel. #
# #
# In the course of monitoring individuals improperly #
# using this system, or in the course of system #
# maintenance, the activities of authorized users #
# may also be monitored. #
# #
# Anyone using this system expressly consents to such #
# monitoring and is advised that if such monitoring #
# reveals possible evidence of criminal activity, #
# system personnel may provide the evidence of such #
# monitoring to law enforcement officials. #
# #
# This system/database contains restricted data. #
# #
#################################################################
[hadoop1 ~]$安装Hadoop
$ wget http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-2.2.0/hadoop-2.2.0.tar.gz
$ tar -zxvf hadoop-2.2.0.tar.gz
$ mv hadoop-2.2.0 /usr/hadoopexport HADOOP_HOME=/usr/hadoop
export HADOOP_MAPARED_HOME=${HADOOP_HOME}
export HADOOP_COMMON_HOME=${HADOOP_HOME}
export HADOOP_HDFS_HOME=${HADOOP_HOME}
export YARN_HOME=${HADOOP_HOME}
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export HDFS_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export YARN_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
<name>hadoop.tmp.dir</name>
<value>/hadoop/tmp</value>
<description>A base for other temporary directories.</description>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://192.168.1.1:9000</value>
</property>
5. $HADOOP_HOME/etc/hadoop/slaves 内容变为(datanode)
192.168.1.2
192.168.1.3
6. $HADOOP_HOME/etc/hadoop/hdfs-site.xml 加入
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/hadoop/hdfs/name</value>
<final>true</final>
</property>
<property>
<name>dfs.federation.nameservice.id</name>
<value>ns1</value>
</property>
<property>
<name>dfs.namenode.backup.address.ns1</name>
<value>192.168.1.1:50100</value>
</property>
<property>
<name>dfs.namenode.backup.http-address.ns1</name>
<value>192.168.1.1:50105</value>
</property>
<property>
<name>dfs.federation.nameservices</name>
<value>ns1</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns1</name>
<value>192.168.1.1:9000</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns2</name>
<value>192.168.1.1:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.ns1</name>
<value>192.168.1.1:23001</value>
</property>
<property>
<name>dfs.namenode.http-address.ns2</name>
<value>192.168.1.1:13001</value>
</property>
<property>
<name>dfs.dataname.data.dir</name>
<value>file:/hadoop/hdfs/data</value>
<final>true</final>
</property>
<property>
<name>dfs.namenode.secondary.http-address.ns1</name>
<value>192.168.1.1:23002</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address.ns2</name>
<value>192.168.1.1:23002</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address.ns1</name>
<value>192.168.1.1:23003</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address.ns2</name>
<value>192.168.1.1:23003</value>
</property>
7. $HADOOP_HOME/etc/hadoop/yarn-site.xml 加入
<property>
<name>yarn.resourcemanager.address</name>
<value>192.168.1.1:18040</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>192.168.1.1:18030</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>192.168.1.1:50030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>192.168.1.1:18025</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>192.168.1.1:18141</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.web-proxy.address</name>
<value>hadoop1-9014.lvs01.dev.ebayc3.com:54315</value>
</property>
8. $HADOOP_HOME/etc/hadoop/httpfs-site.xml 加入
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>192.168.1.1</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
9. $HADOOP_HOME/etc/hadoop/mapred-site.xml 加入(配置job提交到yarn上而且配置history log server)
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<description>Execution framework set to Hadoop YARN.</description>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop1-9014.lvs01.dev.ebayc3.com:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop1-9014.lvs01.dev.ebayc3.com:19888</value>
</property>
<property>
<name>mapreduce.jobhistory.intermediate-done-dir</name>
<value>/log/tmp</value>
</property>
<property>
<name>mapreduce.jobhistory.done-dir</name>
<value>/log/history</value>
</property>
这个是说明把job放到yarn 上去跑。
10. 配置同步到其它datanode上
$ scp ~/.bash_profile hadoop2:~/.bash_profile
$ scp $HADOOP_HOME/etc/hadoop/hadoop-env.sh hadoop2:$HADOOP_HOME/etc/hadoop/
$ scp $HADOOP_HOME/etc/hadoop/core-site.xml hadoop2:$HADOOP_HOME/etc/hadoop/
$ scp $HADOOP_HOME/etc/hadoop/slaves hadoop2:$HADOOP_HOME/etc/hadoop/
$ scp $HADOOP_HOME/etc/hadoop/hdfs-site.xml hadoop2:$HADOOP_HOME/etc/hadoop/
$ scp $HADOOP_HOME/etc/hadoop/yarn-site.xml hadoop2:$HADOOP_HOME/etc/hadoop/
$ scp $HADOOP_HOME/etc/hadoop/httpfs-site.xml hadoop2:$HADOOP_HOME/etc/hadoop/
$ scp $HADOOP_HOME/etc/hadoop/mapred-site.xml hadoop2:$HADOOP_HOME/etc/hadoop/把hadoop2改成hadoop3,,把配置同步到hadoop3上
启动Hadoop集群
測试hadoop集群
$ jps
8606 NameNode
4640 Bootstrap
17007 Jps
16077 ResourceManager
8781 SecondaryNameNode2. 在hadoop2 上看进程是否开启
$ jps
5992 Jps
5422 NodeManager
3292 DataNode3. hadoop fs -ls / 看能否够列出文件
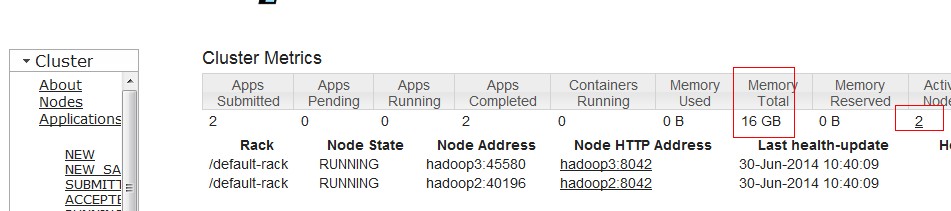
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.2.0.jar wordcount /input /output7假设执行正常,能够在job monitor页面看到job执行状况。
















 1374
1374

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









