






1背景介绍
crawldb1.1.0自动化测试工具的开发已经告一段落了,此间遇到过困难也走过弯路,自觉其中有一些值得吸取和谨记的地方,特此记录以备日后他人和自己参考。
Crawldb是spider抓取相关模块,其主要功能是进行抓取压力控制和流量分配。本版升级在策略和结构上都有较大变动。
2 Crawldb自动化思路
测试元素
任何自动化都需要处理测试相关元素,大约都可以划分为测试数据、测试逻辑、测试环境、被测系统相关等几个方面,粗略整理如下图所示。
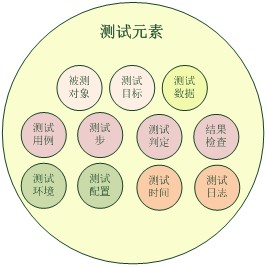
测试相关元素
采用不同思路处理这些测试元素,以不同形式进行组织,就会产生不同风格的自动化测试方法,其关注重点也会有所不同,比如:测试数据的自动生成、被测对象到测试用例的自动转化等等。本版Crawldb自动化关注点放在了测试系统自身的扩展性和重用性设计上,以此为基点进行设计更易于日后向其他方面拓展。
Crawldb自动化采用组件式设计方式,将测试系统设计为一组相互关联的测试组件,将测试用例设计为组件方法的调用序列。
组件化设计 --- 特点一
组件方式基于分层思想,将测试执行过程中与具体用例无关的公共部分提取出来放到底层,把测试逻辑相关部分放到上层,当被测系统原有feature发生变化时,只需要更新受影响的部分组件或用例;当被测系统升级新feature时,也只需补充对应组件和用例,不受影响的部分可直接重用。而且更为便利的是,在本模块手工测试或者其他模块的自动化或手工测试过程中,依然可以重用这些已经设计好的组件,大幅提高测试效率。
Crawldb自动化整体结构如下图所示:
● 测试逻辑在测试用例层体现:将crawldb主要策略分成几个大类,通过划分为TestSuite的一系列TestCase对测试执行过程进行逻辑上描述,覆盖测试方案中描述的所有需要自动化测试覆盖的feature
● 测试实现在测试组件层完成:抽取各个测试用例公共部分已组件形式实现,特有部分使用独立组件实现,用以支持全部自动化测试用例的执行过程,具体分为:
● 结果检查组件:包括对字段传递、压力执行、流量分配、备份/恢复等功能的检查
● 测试桩组件:包括模拟dapper桩模块与被测模块进行数据交互,并支持执行多种自定义行为
● 环境管理组件:包括对环境(部署及配置)的建立、清理和自检
● 接口通信组件:包括模拟上下游模块进行网络通信,以及对控制接口的封装
● 数据构造组件:包括对输入数据进行简单构造、组合构造、特殊构造,对输出数据进行解析、过滤
● 日志查询与统计组件:包括对日志进行信息提取、统计、时间修正等
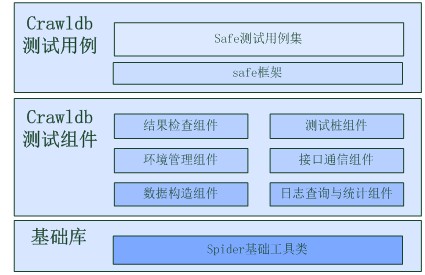
Crawldb自动化测试框架
自动化框架各部分对测试元素覆盖情况如下图所示,测试用例集会覆盖各种元素的逻辑部分,每个测试组件会覆盖一部分测试元素的实现部分。当被测对象的策略发生变动时,只需关注对应层次对应组件是否需要更新即可。
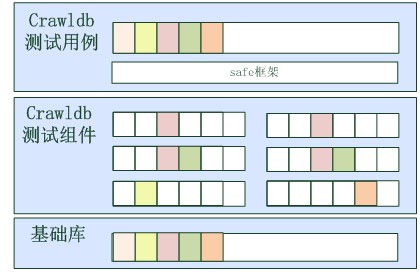
crawldb测试框架对测试元素的覆盖情况
一个例子
下面通过具体例子解读下前文所述的概念。
Crawldb基本策略字段传递的测试场景如下图所示,序列图中包含了5个发生交互的对象:
● Crawldb:表示被测对象
● CMD:命令控制组件,属于接口通信组件类,用于向crawldb发送命令
● Select:测试对象组件,属于接口通信组件类,模拟上游select向crawldb发送数据
● Dapper:伪dapper桩组件,属于测试桩组件类,模拟下游dapper与crawldb发生网络交互
● EC:测试对象组件,属于接口通信组件类,模拟下游ec接收crawldb发送的结果数据
● Check:属于测试结果检查组件类,根据测试输出给出测试是否通过的判定
该场景描述了crawldb基本的字段传递策略:crawldb启动后,接收上游select的发送数据,与dapper发生网络通信后,向下游ec发送处理结果,最后停止crawldb。
该测试场景中除了对交互流程进行描述外,还包含了测试用例所必须的其他元素:在check组件上还含有计时器动作和测试判定动作,check组件会根据crawldb与dapper、crawldb与ec的交互数据以及处理时间,判定该测试用例是否通过。
该测试用例执行时还使用了一些未在图中标明的组件,比如:环境管理组件、测试数据构造组件、日志查询与统计组件等。
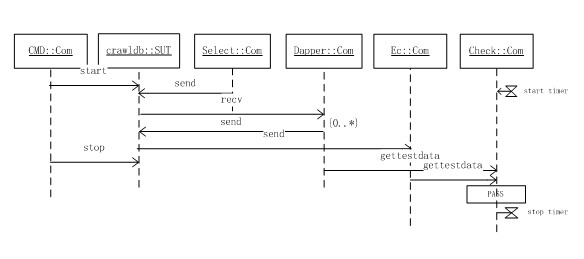
测试用例在测试组件上的执行
基于基础类库 --- 特点二
Crawldb另一个自动化测试特点是基于基础类库。(组内与特定模块无关的python公共库)。
spider此前的自动化测试大都各自为政,许多相似的功能(比如构造ulpack数据包)在各个自动化系统中都有涉及,造成了重复开发。本版 crawldb自动化基于spider公共库,以派生子类或直接引用的方式继承公共库已实现的功能,包括配置文件的操作、ulpack数据包构造等,降低了开发成本。
使用Safe框架 --- 特点三
Safe是psqa统一自动化框架,其实体主要包括python开发的基础工具类库和E家宝接口。
Safe框架同样包含了许多与具体模块无关的公共库,如:网络通信、日志尾部检索等功能,在crawldb自动化测试系统中都有引用。Safe更令人称道之处是其测试管理以及与E家宝的结合上。Safe提供了Controller、Case、Suite等核心基类进行测试用例的执行、管理;提供了 reportlib进行测试结果的汇总、展现;提供了decorator功能进行测试步跟踪。基于safe的自动化系统加强了用例组织、管理能力,测试过程的跟踪以及测试结果的展现。
综上所述,Crawldb自动化测试设计是基于基础类库,以组件化方式设计完成的,在用例管理执行方面采用了Safe框架和E家宝结合的方式。
本小节讨论了crawldb自动化测试设计思路和特点,接下来会进一步讨论自动化设计中较为通用的测试数据构造、测试结果判定等内容。
3测试数据构造
测试数据包括输入数据和输出数据两类:
● 一类是测试输入数据,用于发送给被测对象,触发被测对象的内部计算逻辑;
● 一类是被测对象返回的测试输出数据
自动化测试工具设计开发时通常要支持测试输入数据的构造,以及测试输出数据的解析与判定。接下来两小节会分别讨论下crawldb自动化测试过程中的输入数据构造和输出数据解析、判定。
数据格式描述
crawldb自动化测试过程中,需要构造的最主要测试数据是select发给crawldb的数据,属于pack包类型,具体格式如下表所示。
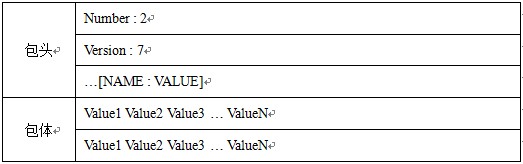
select2crawldb包格式
select2crawldb数据包由包头、包体构成,包头由名值对组成,包体由行组成。包体行数由包头Number字段取值指定,包体每行的格式由包头 Version字段取值指定,包体每行是由特定分隔符分隔的一系列字段值组成(每个字段均有特定含义,比如某列表示url等)。
数据构造需求
crawldb测试需要覆盖到以下数据包:
● 指定各个包头字段取值;
● 指定各个包体字段取值;
● 指定包头Version字段值,自动化修改包体行格式;
● 指定包头Number字段值,自动构造对应数目包体行;
● 支持包体中url字段不重复;
● 支持数据包前增加登录包;
● 支持异常数据的构造;
外部接口设计
在crawldb1.1.0自动化测试采用了ulpackgen(spider基础库)的方式构造输入包,以dict参数形式传入特定字段的取值(或集合)进行构造,接口设计如下表所示:

数据构造接口描述表
内部实现设计
在实现方面ps2c:: ps.spider.crawldb.lib.cdbPack.PackSelect2Crawldb:
● 单包构造功能通过直接使用ulpack实现。
● 多包、组合、去重、多类型等构造功能,通过Select2CrawldbFieldGenerator、BodyLine实现。
Select2CrawldbFieldGenerator
select2crawldb包体行中某字段的生成器。继承自ulpackgen.BodyGenerator并重写了values()、 update()方法,前者从BodyLine中提取字段值,后者构造BodyLine并用其更新包体内容以达到更新包体字段取值的目的;通过在 update()中加入对Version的判断来支持多种包体类型
BodyLine
用于描述select2crawldb的包体一行,含有Version属性描述类型、各Version包体行格式及字段默认取值;在 Select2CrawldbFieldGenerator.update()内构造,并用其更新包体;通过__getitem__、 __setitem__来与ulpack保持对外接口的一致性。
PackSelect2Crawldb
对外用于构造select2crawldb数据包的工具类;传入参数为dict类型,name为字段名称,value为字段取值集合;根据dict构造包体字段生成器Select2CrawldbFieldGenerator;包体字段依赖于包头Version字段取值;自增情况:根据传入的index修改包体url取值为自增字符串,返回下一个可用的index。
4测试结果判定
思路与方法
测试结果判定是自动化测试工具需要解决的重要问题。
把预期输出与被测系统的实际输出进行对比,是自动化测试系统较为常见的测试判定方法。预期输出可以保存成静态标准数据(或规则),也可以通过自动化测试工具自己计算得到。
在Crawldb自动化测试时采用了计算标准输出、将其与crawldb实际输出数据进行对比的方式判定测试结果,这样做避免了对标准结果的存储与维护。
标准数据计算方法
与crawldb发生数据交互的模块有select、dapper、ec,其输入输出数据均为ulpack包,包括:
● 输入数据:select2crawldb、dapper2crawldb
● 输出数据:crawldb2ec、crawldb2dapper
根据输入数据,可以确定输出数据中除时间相关因素以外的取值。
以crawldb2ec为例对crawldb基本处理流程进行简要分析(crawldb2dapper与此类似):
● crawldb2ec数据包由包头、包体两部分组成
● 包头含有select2crawldb包体中某行的字段名值集合,同时含有dapper2crawldb包头的名值集合
● 包体含有dapper2crawldb包体中页面部分
以crawldb的这种算法为依据,就能够设计出计算标准数据的方法。
dapper2crawldb包格式如下表所示:

dapper2crawldb包格式
设计时采用了一个std::dict进行两类标准数据的merge
● 首先解析select2crawldb的包体行并以名值对的形式存入std
● 然后解析dapper2crawldb以名值对形式merge进std中(包含页面部分)
这样就将标准数据存放在了字典std中。
实际输出数据转换
为了便于最终进行测试结果的判定,将实际输出数据也转换为字典类型,也即将crawldb2ec数据包的包体名值对以及包体存储在字典rcv中。
crawldb2ec包格式如下表所示:

crawldb2ec包格式
对比方法
经过良好设计的自动化测试工具,测试完成后不应仅仅给出PASS/FAIL的测试结论,在测试FAIL时,应该给出足够的能够提供分析被测系统问题的信息。
基于这种考虑,crawldb自动化测试工具在设计时,没有使用简单的字符串对比方式,而是先以结构化形式解析各版本的包体字段,采用diffDict结构进行结果对比:
● 把std和rcv两个字典中的diff字段保存在diffDict字典里,当diffDict为空时测试通过;
● 当diffDict不为空时测试失败,并且打印出diffDict内容,可以方便定位问题。
结果判断的其他问题
1、 上下游字段名不一致:
测试中时常出现一些字段,它们含义及取值一致,但是在不同模块接口上的名称不完全一致。比如:全称和缩写,大小写等。crawldb测试中通过预先定义了 renameList、delList、addList进行修正,解决了dapper2crawldb和crawldb2ec接口字段名称不一致的问题
2、字段默认取值:
因为select2crawldb有Version1~Version7这7种类型,字段数量有多有少。对于早期的类型,缺少有些字段的取值,crawldb给每一个字段都写死了一个默认值,每当上游没有发来该字段时,crawldb就会补齐该默认值。字段的默认取值可以预先配置默认值列表实现。
3、多包判定:
crawldb测试结果判定,并不只限于单个数据包,应该能支持输入数据、输出数据中均包含有多个数据包的情况。
这种情况实际上通过为每一个包选取一个key来解决的。我们选取“method+url”作为每一个输入、输出数据包的key,将前文所述的名值对作为value,通过比较std与rcv所含key数据是否相同,相同key对于value是否相同来实现多包的判定行为。
4、多种策略判定:
前文所述是crawldb最常见策略,事实上对于特殊的select2crawldb数据还存在另一种生成crawldb2ec的方式:不需要merge dapper2crawldb数据,直接数据转换并传递。该类测试的结果判定与前文类似,只是省略了merge dapper2crawldb到std的步骤,增加了填充特定字段名值集合的步骤。
5、登录验证:
登录是模块通信的常见过程,crawldb上下游各模块接口有的需要登录有的不需要登录,这种特性要求进行测试判定需要特殊处理,最终进行测试工具设计时,采用了过滤select2crawldb、dapper2crawldb登录包的方式进行。
(全文完)
转载于:https://blog.51cto.com/baidutech/743221
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









