








上次介绍了分类算法K近邻,其属于预测分类的一种,那么这次我们就学习一下数据挖掘算法中的关联算法Apriori,其最原始的应用就是挖掘交易数据中商品之间的关联,最经典的就是“尿布和啤酒”的案例,当然在当今这个互联网技术发达的时代,关联算法已经得到了很大的发展,在各行各领域上都有了各自的拓展和取得成效,下面就直奔主题。
一、重要的定义
事务型数据:关联分析的数据一般是事务型数据,事务型数据的特点是数据集中每一行记录对应一个事务(交易数据的明细),每个事务中的元素称为项,项集就是包含1个或者多个项的集合,若包含K个项,则称为K项集。
支持度:一个项集的支持度是指该项集在事务型数据中出现的频率。例如一组包含了100个项集的事务型数据,其中项集{A,B}在事务型数据中共有出现了30次,则项集{A,B}的支持度为0.3,可以定义项集X的支持度函数如下,其中,N指事务型数据的总记录数,count(x)指项集X在事务型数据中出现的次数:
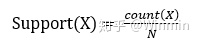
置信度:支持度很低的项集规则一般情况下判断为偶然出现,支持度通常用来过滤掉那些无意义的项集规则。一个项集的置信度是指是用于度量该项集的预测准确度,简单来讲就是假设有一个二项集,已知其第一项为项A,而这个项集第二项为项B的概率为P,则P就是这个二项集的置信度 ,置信度函数可以表示为:
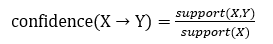
提升度:若频繁项集规则的支持度和置信度都比较高,我们称这些规则为强规则。要想知道这些强规则是否有效,要根据提升度的计算结果判断。提升度表示含有X的条件下,同时含有Y的概率,与Y总体发生的概率之比。简单理解的话,假设Lift(X→Y)的值为a,则表示顾客在已经购买了商品X的前提条件下,会再去购买商品Y的可能性是一般顾客购买商品Y可能性的a倍。提升度函数可表示为:
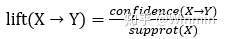
二、Apriori算法原理与性质
Apriori算法的核心是利用频繁项集性质的先验性质,即一个频繁项集的所有子集必须也是频繁的,也就是n-1项集用于探索n项集,从而减少关联规则的搜寻空间。Apriori算法需要在事先给定支持度阈值,作为判断频繁项集的标准。首先对事务型数据集进行扫描,产生第一个候选数据项集,且该候选数据集为1项集集合。根据事先给定的支持度,筛选出符合阈值要求的集合作为1项频繁项集,记作S_1。然后再次从原始数据集中搜索包含S_1的2项集集合作为下一个候选数据项集,记作S_2。采用相同的方法,直到生成频繁n项集S_n,且已n+1项集不能达到支持度和置信度的限制条件。至此&#x
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









