






对象的序列化,反序列化
对象的序列化:
就是将Object转换成byte序列
对象的反序列化:
将byte序列转换成Object
序列化流。反序列化流
序列化流(ObjectOutputStream),是字节的过滤流—>主要方法:writeObject()
反序列化流(ObjectInputStream)—>主要方法:readObject()
序列化接口(Serializable)
对象必须实现序列化接口。才干进行序列化。否则将出现异常
这个接口,没有不论什么方法,仅仅是一个标准。
主要的对象序列化的操作:
student实体类:
package com.test.ObjectInputStream;
import java.io.Serializable;
public class Student implements Serializable{
private String name;
private int age;
private String sex;
public Student(String name, int age, String sex) {
super();
this.name = name;
this.age = age;
this.sex = sex;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public String getSex() {
return sex;
}
public void setSex(String sex) {
this.sex = sex;
}
@Override
public String toString() {
return "Student [name=" + name + ", age=" + age + ", sex=" + sex + "]";
}
}
对象序列化与反序列化操作类:
package com.test.ObjectInputStream;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
public class ObjectInputStreamTest {
public static void main(String[] args) throws IOException {
String filename = "C:\\Users\\Administrator\\Desktop\\javaIO\\測试ObjectOutputStream的文件.txt";
// //1.对象的序列化
// ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream(filename));
// Student stu = new Student("小灰灰", 22, "男");
// oos.writeObject(stu);
// oos.flush();
// oos.close();
//2.对象的反序列化
ObjectInputStream ois = new ObjectInputStream(new FileInputStream(filename));
try {
Student stu1 = (Student) ois.readObject();
System.out.println(stu1);
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
ois.close();
}
}
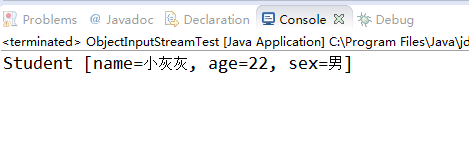
结果截图:
上边的样例是:先通过对象的序列化把对象序列化的内容写入到文件里,然后在通过对象的反序列化从文件里再把对象序列化的内容读取出来。
注意:须要使用序列化的地方:网络传输对象数据时
transient关键字的使用:
当student实体类中name属性前加入transient修饰的时候,那么该属性不会进行jvm默认的序列化,也能够自己完毕这个属性的序列化。
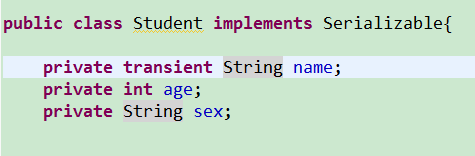
那么上边程序的执行结果为:
事实上查看ArrayList类的源代码:
ArrayList类实现了序列化接口:

ArrayList中的元素数据的数组使用了transient关键字修饰:
/**
* The array buffer into which the elements of the ArrayList are stored.
* The capacity of the ArrayList is the length of this array buffer. Any
* empty ArrayList with elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA
* will be expanded to DEFAULT_CAPACITY when the first element is added.
*/
transient Object[] elementData; // non-private to simplify nested class accessArrayList中的readObject()方法
/**
* Reconstitute the <tt>ArrayList</tt> instance from a stream (that is,
* deserialize it).
*/
private void readObject(java.io.ObjectInputStream s)
throws java.io.IOException, ClassNotFoundException {
elementData = EMPTY_ELEMENTDATA;
// Read in size, and any hidden stuff
s.defaultReadObject();
// Read in capacity
s.readInt(); // ignored
if (size > 0) {
// be like clone(), allocate array based upon size not capacity
ensureCapacityInternal(size);
Object[] a = elementData;
// Read in all elements in the proper order.
for (int i=0; i<size; i++) {
a[i] = s.readObject();
}
}
}ArrayList中的writeObjct()方法:
/**
* Save the state of the <tt>ArrayList</tt> instance to a stream (that
* is, serialize it).
*
* @serialData The length of the array backing the <tt>ArrayList</tt>
* instance is emitted (int), followed by all of its elements
* (each an <tt>Object</tt>) in the proper order.
*/
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException{
// Write out element count, and any hidden stuff
int expectedModCount = modCount;
s.defaultWriteObject();
// Write out size as capacity for behavioural compatibility with clone()
s.writeInt(size);
// Write out all elements in the proper order.
for (int i=0; i<size; i++) {
s.writeObject(elementData[i]);
}
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
}ArrayList类中的元素数据数组为什么要用transient关键字修饰呢?
原因:
并非不想被序列化,而是自己实现了自己的序列化和反序列化的操作来提高性能。由于ArrayList并不能确定数据元素的个数。所以用transient关键字修饰的根本原因是把数组中的有效元素做序列化。无效元素就不进行序列化了,这样能够提高性能。
序列化中子类和父类构造函数的调用问题
两个问题:
(1)一个类实现了序列化的接口,那么它的子类都能够进行序列化。
(2)对子类对象进行反序列化操作的时候,假设其父类没有实现序列化接口。那么其父类的构造函数会被显式调用。
package com.test.ObjectInputStream;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.io.Serializable;
public class ObjectSerialTest {
public static void main(String[] args) {
String filename = "C:\\Users\\Administrator\\Desktop\\javaIO\\測试序列化调用问题的文件.txt";
try {
// WriteObject(filename);
ReadObject(filename);
} catch (Exception e) {
e.printStackTrace();
}
}
public static void WriteObject(String filename) throws Exception {
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream(
filename));
Person3 person3 = new Person3();
oos.writeObject(person3);
oos.flush();
oos.close();
}
public static void ReadObject(String filename) throws Exception {
ObjectInputStream ois = new ObjectInputStream(new FileInputStream(
filename));
Person1 person = (Person1) ois.readObject();
System.out.println(person);
ois.close();
}
}
class Person1 {
public Person1() {
System.out.println("person1");
}
}
class Person2 extends Person1 implements Serializable {
public Person2() {
System.out.println("person2");
}
}
class Person3 extends Person2 {
public Person3() {
System.out.println("person3");
}
}
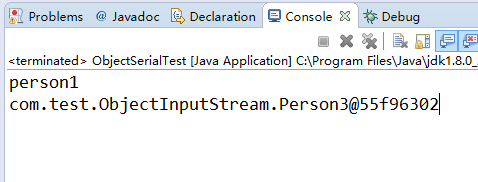
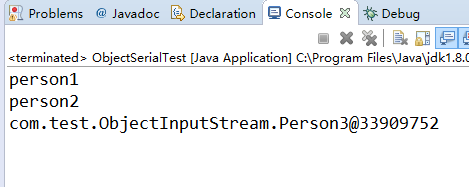
结果截图:
上边的代码当更改为Person3的两个父类都没有实现序列化接口,而是仅仅有Person3实现了序列化接口时,反序列化就会产生这种结果(如图)。
,所以通过上边的样例就能够知道第二个问题的结论。
















 1171
1171

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









