






学习网站: 中国大学MOOC
网址: https://www.icourse163.org/
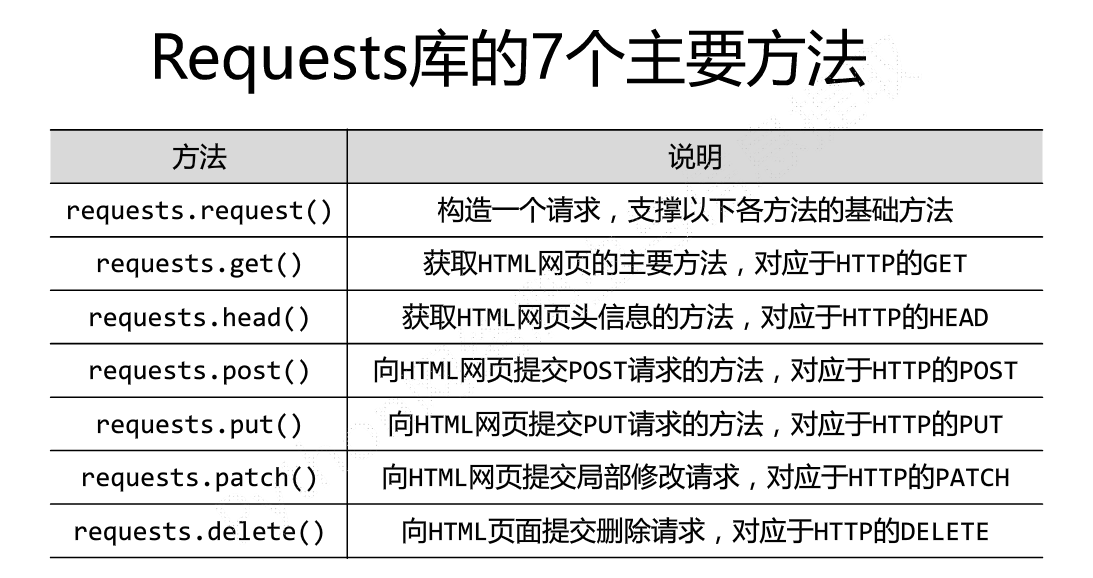
用requests库的get()反法会返回一个response对象。
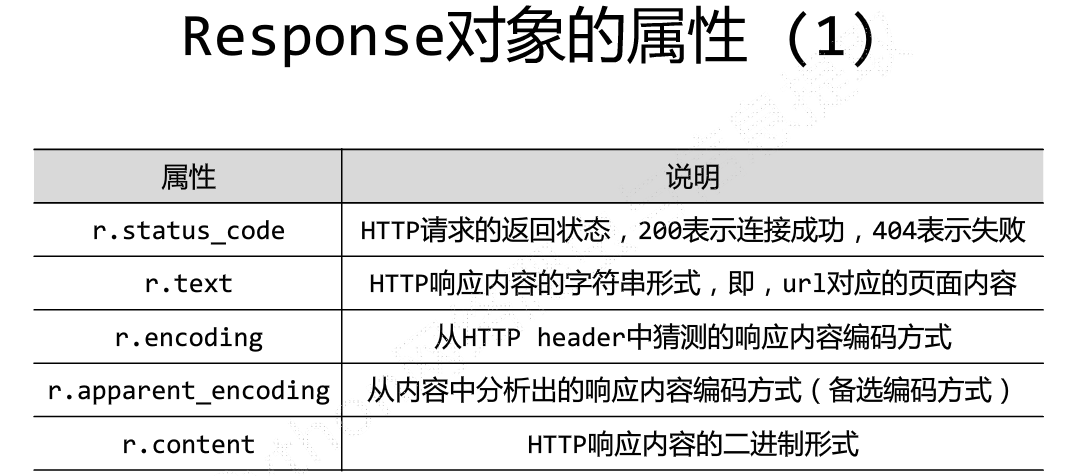
可能会出现的异常:
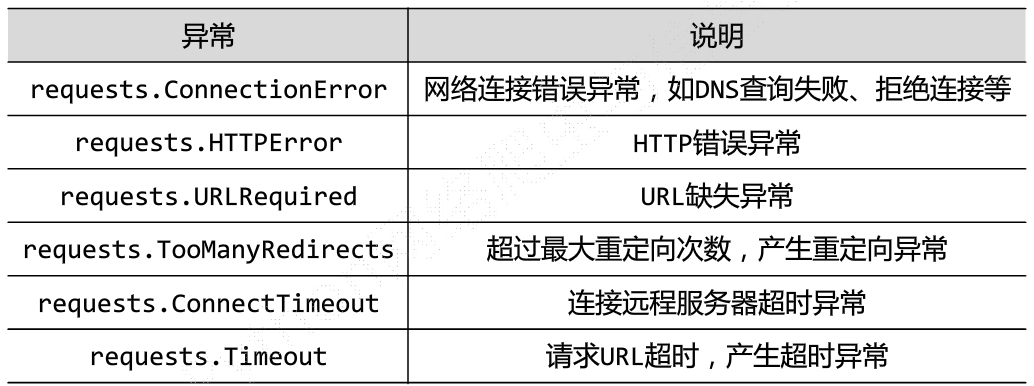
r=requests.get(url)
r.raise_for_status()在方法内部判断r.status_code是否等于200,如果不等于200,会返回异常,利于try-except进行异常处理。
爬取网页的通用代码框架:
import requests def getHTMLText(url): try: r=requests.get(url,timeout=30) r.raise_for_status() #如果状态不是200,则返回异常。 r.encoding = r.apparent_encoding #将从内容分析的响应编码方式赋值r.encoding,更准确。 return r.text except: return "产生异常"
if __name__ == "__main__":
url = ""
print(getHTMLText(url))

实例一:爬取京东商品信息
老师的例子是荣耀8,我的是荣耀10.

全代码:
import requests url = "https://item.jd.com/7081550.html" try: r = requests.get(url) r.raise_for_status() r.encoding = r.apparent_encoding print(r.text[:1000]) except: print("爬去失败")
实列二: 亚马逊商品信息的爬取
这个实例老师是想教我们怎样伪造访问头,但是亚马逊好像已经取消对python爬虫的访问限制了,所以我就直接把老师的代码贴在这。

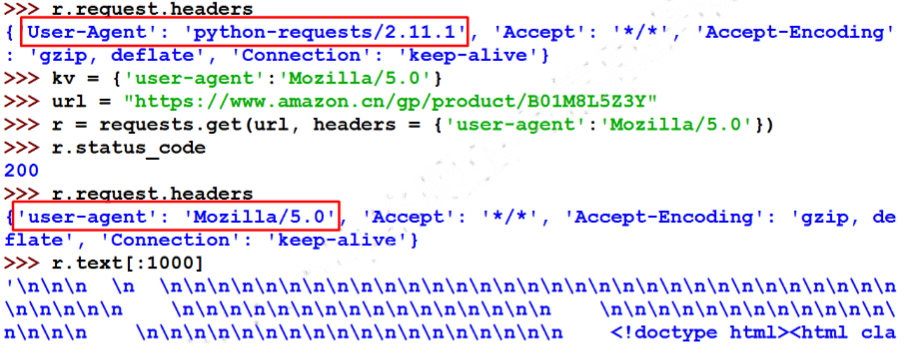

由图可以看出 访问被限制了后,可以在get()方法中改变访问头(改变参数headers)来爬取。
实例三:百度/360搜索关键词提交
百度关键词接口:
http://www.baidu.com/s?wd=keyword
360的关键词接口:
http://www.so.com/s?q=keyword
百度搜索全代码:
import requests keyword = "Python" try: kv = {"wd":keyword} r= requests.get("http://www.baidu.com/s",params = kv) print(r.request.url) r.raise_for_status() print(len(r.text)) except: print("爬取失败")
360搜索全代码:
import requests keyword = "Python" try: kv = {"q":keyword} r= requests.get("http://www.so.com/s",params = kv) print(r.request.url) r.raise_for_status() print(len(r.text)) except: print("爬取失败")
实例4:网络图片的爬取和存储
我们知道,网络上的图片和视频大都是用二进制存储的。所以我们用content属性下载图片。
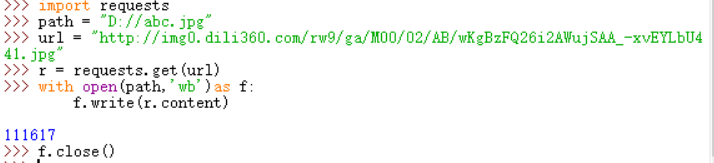
图片爬取全代码:
import requests import os url = "http://img0.dili360.com/rw9/ga/M00/02/AB/wKgBzFQ26i2AWujSAA_-xvEYLbU441.jpg" root = "D://pics//" path = root+url.split('/')[-1] try: if not os.path.exists(root): os.mkdir(root) if not os.path.exists(path): r = requests.get(url) with open(path,'wb')as f: f.write(r.content) f.close() print("文件保存成功") else: print("文件以存在") except: print("爬取失败")
实例5:IP地址归属地的自动查询
例子没什么特别之处,就不写了。















 6126
6126











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









