






Glyph定位表(GPOS)为一个字库所支持的每种script和language system里复杂的文本布局及渲染提供了关于glyph 放置的精确的控制。
概览
复杂的glyph定位在一些书写系统中变成了一个问题,比如Vietnamese,它使用了diacritical和其他的marks来改变字符的读音或意义。为了易读性及语言上的精确,这些书写系统需要控制所有的marks彼此之间的放置。

Figure 4a. Vietnamese words with marks.
其他的书写系统为了正确的排版组合而需要复杂的glyph定位。比如,Urdu glyphs是缮写的,并且沿着一条下降的倾斜的自右向左前进的文本线彼此连接。为了适当地渲染Urdu,一个文字处理客户端必须同时修改每个glyph的水平(X)和竖直(Y)位置。
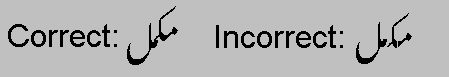
Figure 4b. Urdu layout requires glyph positioning control, as well as contextual substitution
通过GPOS表,一个字库开发者可以在一个 OpenType™字库中定义一个完整的位置调整features集合。GPOS数据,通过script和language system来组织,被一个文字处理客户端用于定位glyphs是很简单的。
通过TrueType 1.0来定位Glyphs
TrueType中的Glyph定位只使用两个值,placement和advance,来为文本布局描述一个glyph的位置。如果说glyphs是相对于一个沿着一条文本的线移动的虚拟的“pen point”来定位的话,则placement描述了相对于当前的“pen point”的glyph位置,而advance则描述了为了定位下一个glyph而需要把pen point移向何处(参见Figure 4c)。对于水平文字,placement对应于左边的bearing,而advance对应于advance宽度。

Figure 4c. Glyph positioning with TrueType
TureType仅能为水平布局在X方向上描述placement和advance,而为竖直布局在Y方向上描述这些值。对于简单的Latin文本布局,要正确的定位glyphs,这两个值可能足够了。但是,对于那些需要更复杂的布局的文本,则用于定位的值必须覆盖一个更丰富的范围。Placement和advance可能需要在竖直方向上做调整,同时也需要在水平方向上做调整。
TrueType中所定义的仅有的定位调整数据是pair kerning,它改变了两个glyphs之间水平方向上的间隔。一个典型的kerning表列出了glyphs对,并描述了一个文字处理客户端应该为glyphs之间加上或去掉多大的间隔来适当的显示每个glyphs对。它不提供关于如何调整每一对中的glyphs的特定信息,并且不能调整多于两个glyphs的上下文。
通过OpenType来定位Glyphs
OpenType字库为定位一个单独的glyph或定位多个glyphs彼此之间的位置提供了出色的控制和灵活性。通过同时使用GPOS表为placement和advance所定义的X和Y值,并通过使用glyph attachment点,一个客户端可以更精确地调整一个glyph的位置。
此外,GPOS表可以引用一个Device表来定义subtle,在任何字体大小和设备分辨率下依赖于设备的调整任何的placement或advance。比如,一个Device表可以指定在51 pixel per em(ppem)下的调整值,但50ppem下则不会发生。
OpenType字库中为放置操作所描述的X和Y值是在典型的笛卡尔坐标系统内的(原点在左边的base上),而无论是什么样的书写方向。此外,字库中所描述的所有的值是以font unit度量的。这一点对于字库设计者特别方便,因为glyphs是在相同的坐标系中画出来的。然而,需要注意的重要的一点是“advance width”的含义改变了,它依赖于书写方向。
比如,在自左向右的scripts里,如果第一个glph的advance宽度为100,则第二个glyph将在100.0处开始画,。在自右向左的scripts里,如果第一个glyph的advance宽度为100,则第二个glyph将在-100.0处开始画。对于一个top-to-bottom的feature,为了将一个glyph的advance 高度增加100,则YAdvance = 100。对于任何的feature,不管书写方向,为了将一个‘o’上的分音符号(dieresis)降低10个单位,则设置YPlacement = -10。
其他的GPOS features可以定义attachment点来结合glyphs并定位它们彼此之间的位置。一个glyph可能具有多个attachment点。这些点的使用将会依赖于被attached的glyph。比如,一个base glyph可能会为不同的diacritical marks而有不同的attachment点。
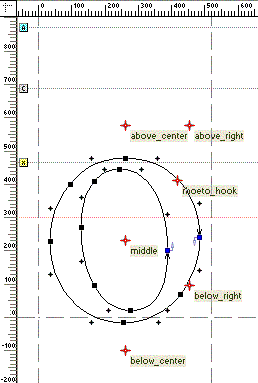
Base glyph with multiple attachment points.
为了减小字库文件的大小,一个base glyph也许会为所有的分配了一个特定类别的mark glyphs使用相同的attachment点。比如,一个base glyph可能有两个attachment点,一个在glyph的上面,而另一个在下面。然后所有的依附到glyphs上边的marks将被依附在高的点上,所有的依附到glyphs下边的marks将被依附到低的点上。Attachment点在某些scripts很有用,比如Arabic,它会给元音marks结合许多的glyphs。
Attachment点对于连接草书的glyphs也很有用。cursive 字库中的glyphs可以被设计来在渲染时依附或重叠。作为选择,字库开发者可以使用OpenType来创建一个cursive attachment feature并为每个glyph定义显式地退出和进入attachment点(参见Figure 4d)。

Figure 4d. Entry and exit points marked on contextual Urdu glyph variations
GPOS表为定位和attaching glyphs而支持8种类型的行为:
一个single adjustment定位一个glyph,比如一个上标或下标。
一个pair adjustment 定位两个glyphs彼此之间的位置。Kerning是pair adjustment的一个例子。
一个cursive attachment描述了cursive scripts和其他的在渲染时与attachment点连接的glyphs。
一个MarkToBase attachment定位combining marks相对于base glyphs的位置,比如定位Arabic,Hebrew和Vietnamese中的元音(vowels),diacritical marks,或tone marks。
一个MarkToLigature attachment定位combining marks相对于连字glyphs的位置。由于连字可能具有多个用于依附marks的点,字库开发者需要将每个mark关联到连字的其中一个glyph组件上。
一个MarkToMark attachment定位一个mark相对于另一个的位置,比如在Vietnamese中定位tone marks相对于vowel diacritical marks的位置。
Contextual positioning描述了在一个可识别的特定的glyphs,glyphs类别或多变的glyphs集合的序列内,如何在上下文中定位一个或多个glyphs。在“输入”上下文序列中可能会执行一个或多个定位操作。Figure 4e描述了一个需要定位调整的上下文。
Chaining Contextual positioning描述了如何在一个链接的上下文中定位一个或多个glyphs,在一个可识别的特定的glyphs,glyphs类别或多变的glyphs集合的序列内。在“输入”上下文序列中可能会执行一个或多个定位操作。

Figure 4e. Contextual positioning lowered the accent over a vowel glyph that followed an overhanging uppercase glyph
表的组织
GPOS表以一个表头开始,表头定义了到一个ScriptList,一个FeatureList和一个LookupList的偏移量(参见Figure 4f):
- ScriptList描述了字库中使用了glyph定位操作的所有scripts和language systems。
- FeatureList定义了渲染这些scripts和language systems所需的所有的glyph定位features。
- LookupList包含了实现每个glyph定位feature所需的所有lookup数据。
关于ScriptLists,FeatureLists和LookupLists的详细讨论,请参考OpenType通用表格式。下面的讨论将总结GPOS表是如何工作的。
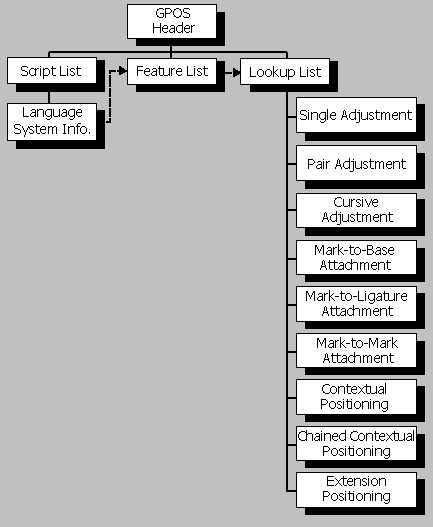
Figure 4f. High-level organization of GPOS table
GPOS表用这种方式进行组织,以使得文字处理客户端可以简单地定位应用于一个特定的script或language system的features和lookups。为了访问GPOS信息,客户端应该使用下面的过程:
- 在GPOS ScriptList表中定位当前的script。
- 如果language system已知,则搜索script表来找到正确的LangSys表;否则,使用script的默认language system(DefaultLangSys表)。
- LangSys表提供了指到GPOS FeatureList表内去的索引数字,客户端以此来访问一个所需的feature和许多附加的features。
- 检查每个feature的FeatureTag,并选择应用于一个输入glyph串的features。
- 每个feature提供了一个指向GPOS LookupList表内部的索引值的数组。lookup数据被定义在一个或多个子表中,子表中包含有关于特定的glyphs的信息及将要在它们上面执行的操作的种类。
- 由选择的feature集合收集所有的lookups,并以LookupList表中定义的顺序应用这些lookups。
一个lookup使用子表来定义用于实现一个feature的定位行为的特定的条件,类型和结果。一个lookup中所有的子表必须具有相同的LookupType,LookupType如LookupType Enumeration表中所列的那样:
LookupType Enumeration table for glyph positioning
| Value | Type | Description |
|---|---|---|
| 1 | Single adjustment | Adjust position of a single glyph |
| 2 | Pair adjustment | Adjust position of a pair of glyphs |
| 3 | Cursive attachment | Attach cursive glyphs |
| 4 | MarkToBase attachment | Attach a combining mark to a base glyph |
| 5 | MarkToLigature attachment | Attach a combining mark to a ligature |
| 6 | MarkToMark attachment | Attach a combining mark to another mark |
| 7 | Context positioning | Position one or more glyphs in context |
| 8 | Chained Context positioning | Position one or more glyphs in chained context |
| 9 | Extension positioning | Extension mechanism for other positionings |
| 10+ | Reserved | For future use (set to zero) |
每个Lookup都通过一个或多个子表来定义,子表的格式则依赖于定位操作的类型,及产生的存储效率。当glyph信息用多于一种格式来表示最好时,一个单独的lookup也许会定义多于一个的子表,只要所有的子表具有相同的LookupType即可。比如,一个给定的lookup内,一个glyph索引数组格式可能是表示一个目标glyphs集合的最好格式,而一个glyph索引范围格式对于另外一个集合可能更好。相同glyph或子串上的一系列定位操作需要多个lookups,每个分开的行为一个。这些情况下,ValueRecords中的值被累积起来。每个lookup会被给定一个LookupList表中的不同的数组号,并且它们会被以LookupList中的顺序应用。
在文字处理过程中,一个客户端在移向下一个lookup之前,会对字串中的每一个glyph应用一个lookup。对于一个glyph的处理,一个lookup会在客户端定位到了目标glyph或glyph上下文并执行了一个定位操作(如果指定了的话)之后结束。为了移向“下一个”glyph,客户端典型地会跳过所有参与了当前lookup操作的glyphs:被调整位置的glyphs,还有为操作形成了一个上下文的任何其他glyphs。
仅有一个例外:一个序列中的“下一个”glyph可能是为刚刚执行的操作形成了一个上下文的那些glyphs中的一个。比如,在pair定位操作(比如,kerning)的情形中,如果第二个glyph的position value record是null,则那个glyph将被当作是序列中的“下一个”glyph。
本章的剩余部分将会描述GPOS表头,和为每种LookupType定义的子表。一些GPOS子表共享其他的一些表:ValueRecords,Anchor表,和MarkArrays。为了简单的引用,被共享的表在本章的结尾处描述。
GPOS表头
GPOS表以一个表头开始,它包含有一个最初被设为1.0(0x00010000)的版本号(Version),和到三个表的偏移量:ScriptList,FeatureList和LookupList。关于这些表的描述,请参考章节, OpenType Common Table Formats。本章结尾处的示例1显示了一个GPOS表头的定义。
GPOS Header
| Value | Type | Description |
|---|---|---|
| Fixed | Version | Version of the GPOS table-initially = 0x00010000 |
| Offset | ScriptList | Offset to ScriptList table-from beginning of GPOS table |
| Offset | FeatureList | Offset to FeatureList table-from beginning of GPOS table |
| Offset | LookupList | Offset to LookupList table-from beginning of GPOS table |
LookupType1:Single Adjustment Positioning Subtable
一个single adjustment positioning子表(SinglePos)被用于调整单个的glyph的位置,比如一个上标或下标。此外,一个SinglePos子表通常被用于为上下文定位实现lookup数据。
一个SinglePos子表将具有两种格式中的一种:一种给一系列的glyphs应用相同的adjustment,或者一种为每个唯一的glyph应用一个不同的adjustment。
Single Adjustment Positioning: Format 1
一个SinglePosFormat1子表给Coverage表中所列出的每个glyph应用相同的定位值或多个值。例如,当一个字库使用了老式的数字符号时,这种格式可以被应用于统一地降低所有的数组符号glyphs的位置。
Format 1子表有一个格式标识符(PosFormat),一个到一个定义了将通过定位值而被调整的glyphs的Coverage表的偏移量(Coverage),及格式标识符(ValueFormat)组成,格式标识符(ValueFormat)描述了ValueRecord中数据的数量和种类。
ValueRecord描述了应用于所有覆盖的glyphs的一个或多个定位值(Value)。比如,如果Coverage表中所有的glyphs既需要水平调整,又需要竖直的调整,则ValueRecord将既为XPlacement,又为YPlacement指定值。
本章结尾处的示例2显示了一个用于调整上标glyphs placement的SinglePosFormat1子表。
SinglePosFormat1 subtable: Single positioning value
| Value | Type | Description |
|---|---|---|
| uint16 | PosFormat | Format identifier-format = 1 |
| Offset | Coverage | Offset to Coverage table-from beginning of SinglePos subtable |
| uint16 | ValueFormat | Defines the types of data in the ValueRecord |
| ValueRecord | Value | Defines positioning value(s)-applied to all glyphs in the Coverage table |
Single Adjustment Positioning: Format 2
一个SinglePosFormat2子表提供了一个ValueRecords的数组,其中为Coverage表中的每个glyph包含了一个定位值。这种格式相对于Format 1更加的灵活,但它也需要字库文件中更多的空间。
比如,假设Cyrillic script将被用于左对齐的文本。则对于所有的glyphs,Format 2可以为左边bearings定义位置调整数据来对齐段落的左边界。为了达到这一点,Coverage表将列出script中的每一个glyph,并且SinglePosFormat2子表将为每个覆盖的glyph定义一个ValueRecord。相应地,每个ValueRecord将为左边bearing指定一个XPlacement调整值。
注意:定义在一个SinglePos子表中的所有的ValueRecord必须具有相同的ValueFormat。在这个例子中,如果XPlacement是一个ValueRecord在光学地对齐glyphs时所需的仅有的值,则XPlacement将是子表的ValueFormat中所描述的仅有的值。
如在Format 1中的一样,Format 2子表由一个格式标识符(PosFormat),一个到 一个 定义了将通过定位值而被调整的glyphs的Coverage表的偏移量(Coverage),及一个格式标识符(ValueFormat)组成,格式标识符(ValueFormat)描述了ValueRecord中数据的数量和种类。此外,Format 2子表还包括:
一个ValueRecords的个数(ValueCount)。为Coverage表中的每个glyph定义一个ValueRecord。
一个ValueRecords的数组,描述了定位值(Value)。由于这个数组遵从Coverage Index顺序,则第一个ValueRecord应用于Coverage表中所列出的第一个glyph,以此类推。
本章结尾处的示例3显示了如何通过一个SinglePosFormat2子表调整三个dash glyphs的间隔。
SinglePosFormat2 subtable: Array of positioning values
| Value | Type | Description |
|---|---|---|
| uint16 | PosFormat | Format identifier-format = 2 |
| Offset | Coverage | Offset to Coverage table-from beginning of SinglePos subtable |
| uint16 | ValueFormat | Defines the types of data in the ValueRecord |
| uint16 | ValueCount | Number of ValueRecords |
| ValueRecord | Value [ValueCount] | Array of ValueRecords-positioning values applied to glyphs |
Lookup Type 2: Pair Adjustment Positioning Subtable
一个pair adjustment positioning子表(PairPos)被用于调整两个glyphs彼此之间的位置-比如,来为glyphs对描述kerning数据。然而,相比于一个典型的kerning表,一个PairPos子表提供了更多的灵活性及关于glyph定位的精确的控制。PairPos子表可以同时在X和Y方向上独立地调整一个pair中的每个glyph,并且可以显式地描述应用于每个glyph的特定的调整类型。此外,一个PairPos子表可以使用Device表在每种字体大小及设备分辨率下,精细地调整glyph的位置。
PairPos子表可以是两种格式中的一种:一种通过索引独立地描述glyphs(Format 1),或者一种通过类别来描述glyphs(Format 2)。
Pair Positioning Adjustment: Format 1
Format 1使用glyph索引来为一个或多个glyph对访问定位数据。所有的pair被描述的顺序有文本的布局方向来决定。
注意:对于自右向左书写的文字,最右端的glyph将是glyph对中的第一个glyph;相反地,对于自左向右书写书写的文字,最左端的glyph是第一个。
一个PairPosFormat1子表包含一个格式标识符(PosFormat)和两个ValueFormats:
- ValueFormat1应用于每个pair中第一个glyph的ValueRecord。所有第一个glyphs的ValueRecords必须都使用ValueFormat1。如果ValueFormat1被设为0,则对应的glyph没有ValueRecord,并且,不应该被调整位置。
- ValueFormat2应用于每个pair中第二个glyph的ValueRecord。所有第二个glyphs的ValueRecords必须都使用ValueFormat2。如果ValueFormat2被设为null,则pair中的第二个glyph将是一个lokkup应该被执行于其上的“下一个”glyph。
一个PairPos子表也定义了一个到一个Coverage表的偏移量(Coverage),其中列出了每个pair中第一个glyph的索引。多于一个的pair可以使用相同的首glyph,但Coverage表将只列出那个glyph一次。
这个子表也包含一个到PairSet表的偏移量的数组(PairSet)及一个其定义的表的个数(PairSetCount)。PairSet数组为Coverage表中所列出的每个glyph包含一个偏移量,并使用与Coverage Index相同的顺序。
PairPosFormat1 subtable: Adjustments for glyph pairs
| Value | Type | Description |
|---|---|---|
| uint16 | PosFormat | Format identifier-format = 1 |
| Offset | Coverage | Offset to Coverage table-from beginning of PairPos subtable-only the first glyph in each pair |
| uint16 | ValueFormat1 | Defines the types of data in ValueRecord1-for the first glyph in the pair -may be zero (0) |
| uint16 | ValueFormat2 | Defines the types of data in ValueRecord2-for the second glyph in the pair -may be zero (0) |
| uint16 | PairSetCount | Number of PairSet tables |
| Offset | PairSetOffset [PairSetCount] | Array of offsets to PairSet tables-from beginning of PairPos subtable-ordered by Coverage Index |
一个PairSet枚举出了所有以一个覆盖的相同的glyph开始的glyphs对。一个PairValueRecords数组(PairValueRecord)为每个pair包含一个记录,并以每个pair中第二个glyph的GlyphID为序列出记录。PairValueCount描述了集合中PairValueRecords中的个数。
PairSet table
| Value | Type | Description |
|---|---|---|
| uint16 | PairValueCount | Number of PairValueRecords |
| struct | PairValueRecord [PairValueCount] | Array of PairValueRecords-ordered by GlyphID of the second glyph |
一个PairValueRecord描述了一个pair中的第二个glyph(SecondGlyph),并为每个glyph定义了一个ValueRecord(Value1和Value2)。如果在PairPos子表中ValueFormat1被设为了0,ValueRecord1将会是空的;类似地,如果ValueFormat2是0,则Value2将是空的。
本章结尾处的示例4显示了一个PairPosFormat1子表,其中定义了两个pair kerning的cases。
PairValueRecord
| Value | Type | Description |
|---|---|---|
| GlyphID | SecondGlyph | GlyphID of second glyph in the pair-first glyph is listed in the Coverage table |
| ValueRecord | Value1 | Positioning data for the first glyph in the pair |
| ValueRecord | Value2 | Positioning data for the second glyph in the pair |
Pair Positioning Adjustment: Format 2
Format 2将一个pair定义为一个两glyph类别的集合,并且改变一个类别中所有的glyphs的位置。比如,这个格式在Japanese scripts就很有用,其中对包含了标点符号glyphs的所有glyphs对应用特定的kerning操作。一个类别将被定义为所有的可能与标点符号marks结合的glyphs,而另一个类别将会是相似的标点符号glyphs的群组。
PairPos Format 2子表以一个格式标识符(PosFormat)和一个到一个Coverage表的偏移量(Coverage)开始,其中偏移量凑PairPos子表的开始处计算起。其中Coverage表中列出了每个glyph对中可能出现的第一个glyphs的索引。多个pair可能以相同的glyph开始,但Coverage表只列出那个glyph索引一次。
一个PairPosFormat2子表也包含两个ValueFormat2:
- ValueFormat1应用于每个pair中第一个glyph的ValueRecord。所有的第一个glyph的ValueRecords必须都使用ValueFormat1。如果ValueFormat1被设为了0,则对应的glyph没有ValueRecord,并且因而不应该被重新定位。
- ValueFormat2应用于每个pair中第二个glyph的ValueRecord。所有第二个glyphs的ValueRecords必须都使用ValueFormat2。如果ValueFormat2被设为null,则pair中的第二个glyph将是一个lokkup应该被执行于其上的“下一个”glyph。
PairPosFormat2需要所有pair中的每个glyph被分配一个类别,而类别则通过一个称为类别值的整数来识别。(关于类别的详细信息,请参考章节,OpenType通用表格式。)然后Pairs在一个二维数组中被表示为一个两类别值的序列。多个pairs可能在一个一个Format 2子表中表示。
一个PairPosFormat2子表包含了到两个类别定义表的偏移量:一个给所有pairs中的第一个glyphs分配类别值(ClassDef1),一个给所有pairs中的第二个glyphs分配类别值(ClassDef2)。如果一个pair中的两个glyphs使用相同的类别定义,则ClassDef1和ClassDef2的偏移值可以是相同的,但它们不需要一定是相同的。这个子表也确定了定义在ClassDef1中glyph类别值的个数(Class1Count),及ClassDef2中glyph类别值的个数(Class2Count),包括Class 0。
对于ClassDef1表中所确定的每个类别值,一个Class1Record枚举了所有包含了一个特定的类别作为第一个组件的pairs。Class1Record数组依据类别值存储所有的Class1Records。
注意:Class1Records不是通过一个类别值标识符来标记的。反而是数组中一个Class1Record的索引值定义了由那个记录所代表的类别值。比如,第一个Class1Record枚举了以一个Class 0glyph开始的pairs,第二个Class2Record枚举了以一个Class 1glyph开始的pairs,以此类推。
PairPosFormat2 subtable: Class pair adjustment
| Value | Type | Description |
|---|---|---|
| uint16 | PosFormat | Format identifier-format = 2 |
| Offset | Coverage | Offset to Coverage table-from beginning of PairPos subtable-for the first glyph of the pair |
| uint16 | ValueFormat1 | ValueRecord definition-for the first glyph of the pair-may be zero (0) |
| uint16 | ValueFormat2 | ValueRecord definition-for the second glyph of the pair-may be zero (0) |
| Offset | ClassDef1 | Offset to ClassDef table-from beginning of PairPos subtable-for the first glyph of the pair |
| Offset | ClassDef2 | Offset to ClassDef table-from beginning of PairPos subtable-for the second glyph of the pair |
| uint16 | Class1Count | Number of classes in ClassDef1 table-includes Class0 |
| uint16 | Class2Count | Number of classes in ClassDef2 table-includes Class0 |
| struct | Class1Record [Class1Count] | Array of Class1 records-ordered by Class1 |
每个Class1Record包含一个Class2Records的数组(Class2Record),它也是以类别值来排序的。必须为ClassDef2表中的每个类别都声明一个Class2Record,包括Class 0。
Class1Record
| Value | Type | Description |
|---|---|---|
| struct | Class2Record[Class2Count] | Array of Class2 records-ordered by Class2 |
一个Class2Record由两个ValueRecords组成,一个为一个class pair中的第一个glyph(Value1),一个为第二个glyph(Value2)。如果PairPos子表中,ValueFormat1或ValueFormat2的值为0,则对应的记录(ValueRecord1或ValueRecord2)将是空的。
本章结尾处的示例5演示了通过一个PairPosFormat2子表中的glyph类别实现的pair kerning。
Class2Record
| Value | Type | Description |
|---|---|---|
| ValueRecord | Value1 | Positioning for first glyph-empty if ValueFormat1 = 0 |
| ValueRecord | Value2 | Positioning for second glyph-empty if ValueFormat2 = 0 |
Lookup Type 3: Cursive Attachment Positioning Subtable
一些cursive字库被设计出来,以使得相邻的glyphs在通过他们默认的定位操作被渲染时结合在一起。然而,如果结合glyphs需要定位调整,那么一个cursive attachment positioning (CursivePos) 子表可以描述如何通过对齐两个锚点(anchor points)来连接glyphs:一个glyph指定的退出点和紧跟其后的glyph指定的入口点。
这种子表具有一种格式:CursivePosFormat1。它以一个格式标识符(PosFormat)及一个到一个Coverage表的偏移量(Coverage)开始,其中Coverage表列出了定义了cursive attachment数据的所有glyphs。
此外,这种子表为Coverage表中所列的每个glyph包含有一个EntryExitRecord,这种子表还包含有那些记录的个数(EntryExitCount),及一个与Coverage Index相同顺序排序的那些记录的数组(EntryExitRecord)。
CursivePosFormat1 subtable: Cursive attachment
| Value | Type | Description |
|---|---|---|
| uint16 | PosFormat | Format identifier-format = 1 |
| Offset | Coverage | Offset to Coverage table-from beginning of CursivePos subtable |
| uint16 | EntryExitCount | Number of EntryExit records |
| struct | EntryExitRecord[EntryExitCount] | Array of EntryExit records-in Coverage Index order |
每个EntryExitRecord由两个偏移量组成:一个指向描述了glyph上的入口点的Anchor表(EntryAnchor),一个指向描述了glyph上的退出点的Anchor点(ExitAnchor)。(关于Anchor表的一个完整的描述,请参见本章的结尾处。)
为了使用CursivePosFormat1子表来定位glyphs,一个文字处理客户端将一个glyph的ExitAnchor点和它后面的glyph的EntryAnchor点对齐。如果没有对应的锚点(anchor points)出现,则EntryAnchor或者ExitAnchor偏移量可能是NULL。
本章结尾处,示例6描述了Urdu语言中的cursive glyph attachment。
EntryExitRecord
| Value | Type | Description |
|---|---|---|
| Offset | EntryAnchor | Offset to EntryAnchor table-from beginning of CursivePos subtable-may be NULL |
| Offset | ExitAnchor | Offset to ExitAnchor table-from beginning of CursivePos subtable-may be NULL |
Lookup Type 4: MarkToBase Attachment Positioning Subtable
MarkToBase attachment (MarkBasePos) 子表用于定位combining mark glyphs相对于base glyphs的位置。比如,Arabic,Hebrew和Thai scripts会把元音(vowels),diacritical marks和tone marks结合到baseglyphs。
在MarkBasePos子表中,每一个mark glyph具有一个锚点(anchor point)并与一个mark类别关联起来。每个base glyph会为它使用的每种marks类别定义一个锚点(anchor point)。
比如,假设两种mark类别:所有定位于base glyphs上方的marks(Class 0),及所有定位于base glyphs下方的marks(Class 1)。在这种情形中,使用这些marks的每个base glyph将定义两个锚点(anchor point),一个用于附上Class 0中所列出的mark glyphs,一个用于附上Class 1中所列出的mark glyphs。
为了确定结合了一个mark的base glyph,文字处理客户端必须由glyph串中base glyph前面的mark回头往后看。为了结合mark和base glyph,客户端将对齐它们的attachment点,相对于base glyph最终的pen point (advance)位置定位mark。
MarkToBase Attachment子表具有一种格式:MarkBasePosFormat1。该子表以一个格式标识符(PosFormat)及到两个Coverage表的偏移量开始:一个列出了所有在该子表中引用的mark glyphs (MarkCoverage),一个列出了所有在该子表中引用的base glyphs (BaseCoverage)。
对于MarkCoverage表中的每个mark glyph,一个记录确定了他的类别和一个到它的Anchor表的偏移量,其中Anchor表描述了mark的attachment点 (MarkRecord)。一个mark类别通过一个称为类别值的特定整数来识别。ClassCount确定了所有MarkRecords中所定义的独特的mark类别的总数。
MarkBasePosFormat1子表也包含一个到一个MarkArray表的偏移量,其中包含有通过MarkCoverage Index存储于一个数组中的所有的MarkRecords(MarkRecord)。一个MarkArray表也包含有所定义的MarkRecords的个数(MarkCount)。(关于MarkArrays和MarkRecords的详细信息,请参见本章的结尾处。)
MarkBasePosFormat1子表也包含一个到一个BaseArray表的偏移量(BaseArray)。
MarkBasePosFormat1 subtable: MarkToBase attachment point
| Value | Type | Description |
|---|---|---|
| uint16 | PosFormat | Format identifier-format = 1 |
| Offset | MarkCoverage | Offset to MarkCoverage table-from beginning of MarkBasePos subtable |
| Offset | BaseCoverage | Offset to BaseCoverage table-from beginning of MarkBasePos subtable |
| uint16 | ClassCount | Number of classes defined for marks |
| Offset | MarkArray | Offset to MarkArray table-from beginning of MarkBasePos subtable |
| Offset | BaseArray | Offset to BaseArray table-from beginning of MarkBasePos subtable |
BaseArray表由一个数组(BaseRecord)和BaseRecords的个数(BaseCount)组成。数组以与BaseCoverage Index相同的顺序存储了BaseRecords。BaseCoverage表中的每个base glyph都有一个BaseRecord。
BaseArray table
| Value | Type | Description |
|---|---|---|
| uint16 | BaseCount | Number of BaseRecords |
| struct | BaseRecord[BaseCount] | Array of BaseRecords-in order of BaseCoverage Index |
一个BaseRecord为MarkArray的MarkRecords中确定的每个mark类别(包括Class 0)声明一个Anchor表。每个Anchor表为base glyph确定一个用于附上一个特定类别中所有marks的attachment点。一个BaseRecord包含一个到Anchor表的偏移量的数组(BaseAnchor)。基于0的偏移量数组定义了base glyph用于附上mark的attachment 点的完整的集合。
注意:Anchor表不是通过类别值标识符来标记的。相反,数组中一个Anchor表的索引值定义了由该Anchor表表示的类别值。
本章结尾处的示例7通过一个MarkBasePosFormat1子表定义了base glyph上面及下面的mark定位。
BaseRecord
| Value | Type | Description |
|---|---|---|
| Offset | BaseAnchor[ClassCount] | Array of offsets (one per class) to Anchor tables-from beginning of BaseArray table-ordered by class-zero-based |
Lookup Type 5: MarkToLigature Attachment Positioning Subtable
MarkToLigature attachment(MarkLigPos)子表用于定位combining mark glyph相对于连字base glyphs的位置。通过前述MarkToBase attachment,一个单独的base glyph为mark的每种类别定义一个attachment点。与此相比,MarkToLigature attachment描述了多个组件组合而成的连字glyph,其中每个组件都可以为mark的每种类别定义一个attachment点。
因而,对于marks的每种类别,一个连字glyph可能具有多个base attachment点。对于一个mark的特定的attachment点是由连字的组件(其子表与mark关联在一起)来定义的。
MarkLigPos子表可以被用于定义多个mark-to-ligature attachments。在这种子表中,每个mark glyph具有一个锚点(anchor point)并被与一个marks类别关联在一起。每个连字glyph指定了一个二维的数据数组:一个连字中的每个组件定义了一个锚点(anchor point)的数组,每个marks类别都有一个锚点。比如,假设两种mark类别:所有定位于base glyphs上方的marks(Class 0),及所有定位于base glyphs下方的marks(Class 1)。在这种情形中,一个base连字glyph的每个组件都可以定义两个锚点(anchor point),一个用于附上Class 0中所列出的mark glyphs,一个用于附上Class 1中所列出的mark glyphs。作为选择,如果language system不允许在第二个组件上面附上marks,则定一个连字组件也许会定义两个锚点(anchor point),marks的每种类别一个,而第二个连字组件也许会不定义锚点(anchor point)。
为了使用一个MarkToLigature attachment子表来定位一个combining mark,文字处理客户端必须从连字glyph前面的mark向后执行。为了正确地访问这种子表,客户端必须跟踪与相应的mark关联在一起的组件。对齐attachment点来结合相应的mark和连字。
MarkToLigature attachment子表具有一种格式:MarkLigPosFormat1。这种子表以一个格式标识符(PosFormat)和到两个Coverage表的偏移量开始,其中Coverage表中列出了这种子表中引用的所有的mark glyphs (MarkCoverage)和连字glyphs (LigatureCoverage)。
对于MarkCoverage表中的每个glyph,一个MarkRecord确定了他的类别及一个到它的Anchor表的偏移量,其中Anchor表中描述了那个mark的attachment。一个mark类别是通过一个称为类别值的特定整数来标识的。ClassCount记录了所有MarkRecords中所定义的不同mark类别的个数。
MarkBasePosFormat1子表包含一个偏移量,由该子表的起始处计算,指向一个MarkArray表,而该表则以MarkCoverage Index的顺序在一个数组中存储了所有的MarkRecords。(关于MarkArrays和MarkRecords的详细信息,请参见本章的结尾处。)
MarkBasePosFormat1子表也包含一个到一个LigatureArray表的偏移量(LigatureArray)。
MarkLigPosFormat1 subtable: MarkToLigature attachment
| Value | Type | Description |
|---|---|---|
| uint16 | PosFormat | Format identifier-format = 1 |
| Offset | MarkCoverage | Offset to Mark Coverage table-from beginning of MarkLigPos subtable |
| Offset | LigatureCoverage | Offset to Ligature Coverage table-from beginning of MarkLigPos subtable |
| uint16 | ClassCount | Number of defined mark classes |
| Offset | MarkArray | Offset to MarkArray table-from beginning of MarkLigPos subtable |
| Offset | LigatureArray | Offset to LigatureArray table-from beginning of MarkLigPos subtable |
LigatureArray表包含一个个数(LigatureCount),及一个到LigatureAttach表的偏移量的数组(LigatureAttach)。LigatureAttach数组列出了到LigatureAttach表的偏移量,LigatureCoverage表中所列出的每个连字glyph一个,以与LigatureCoverage Index相同的顺序。
LigatureArray table
| Value | Type | Description |
|---|---|---|
| uint16 | LigatureCount | Number of LigatureAttach table offsets |
| Offset | LigatureAttach [LigatureCount] | Array of offsets to LigatureAttach tables-from beginning of LigatureArray table-ordered by LigatureCoverage Index |
每个LigatureAttach表由一个数组(ComponentRecord)及一个连字中组件glyphs的个数(ComponentCount)组成。数组以与连字中组件相同的排序存储了ComponentRecords。记录的排序也对应于位子的书写方向。对于自左向右书写的文字,第一个组件在左边;对于自右向左书写的文字,第一个组件在右边。
LigatureAttach table
| Value | Type | Description |
|---|---|---|
| uint16 | ComponentCount | Number of ComponentRecords in this ligature |
| struct | ComponentRecord[ComponentCount] | Array of Component records-ordered in writing direction |
ComponentRecord,连字中的每个组件一个,包含一个到相应的Anchor表的偏移量的数组,其中Anchor表定义了用于将attach附到相应的组件上的所有attachment点(LigatureAnchor)。对于MarkArray records中标识的每种mark类别(包括Class 0),会有一个Anchor表描述用于将一个特定的类别中所有的marks附到连字base glyph的点,相对于组件而言。
在一个ComponentRecord中,基于0的LigatureAnchor数组根据类别列出了到Anchor表的偏移量。如果一个组件不为一个特定的mark类别定义attachment点,则到相应的Anchor表的偏移量将会是NULL。
本章结尾处的示例8显示了一个在Arabic script中用于将mark accent附到一个连字glyph的MarkLisPosFormat1子表。
ComponentRecord
| Value | Type | Description |
|---|---|---|
| Offset | LigatureAnchor [ClassCount] | Array of offsets (one per class) to Anchor tables-from beginning of LigatureAttach table-ordered by class-NULL if a component does not have an attachment for a class-zero-based array |
Lookup Type 6: MarkToMark Attachment Positioning Subtable
MarkToMark attachment (MarkMarkPos) 子表与MarkToBase attachment的形式一致的,尽管它的功能不同。MarkToMark attachment定义了一个mark相对于另一个mark的位置,比如,在Vietnamese中,定位tone marks相对于vowel diacritical marks的位置。
衣服的mark是Mark1,被依附的base mark是Mark2。在MarkMarkPos子表中,每个Mark1 glyph具有一个anchor attachment point并与一个marks类别关联起来。每个Mark2 glyph为每种marks类别定义一个锚点(anchor point)。比如,设想有两个Mark1类别:所有放在Mark2 glyphs左边的marks(Class 0),和所有放在Mark2 glyphs右边的marks(Class 1)。使用了这些marks的每个Mark2 glyph会定义两个锚点(anchor point):以用于依附Class 0中所列出的Mark1 glyphs,一个用于依附Class 1中所列出的Mark1 glyphs。
与一个Mark1 gylph结合的Mark2 glyph是glyph串中相应的Mark1 glyph前面的那个glyph(可能会依据LookupFlags而跳过一些glyphs)。The subtable applies precisely when that Mark2 glyph is covered by Mark2Coverage. 为了结合mark glyphs,相应的Mark1 glyph会被移动,以使得相关的attachment points能够重合。MarkToBase,MarkToLigature和MarkToMark定位表的输入上下文是被定位的那个mark。如果一个序列包含有多个marks,一个lookup可以在它上面多次执行来定位它们。
MarkToMark attachment子表只有一种格式:MarkMarkPosFormat1。这种子表以一个格式标识符(PosFormat)和两个到Coverage表的偏移量开始,一个Coverage表会列出这种子表中引用的所有Mark1 glyphs (Mark1Coverage),另一个会列出这种子表中引用的所有Mark1 glyphs (Mark2Coverage)。
对于Mark1Coverage表中的每个mark glyph,一个MarkRecord会描述它的类别并包含一个指向其Anchor表的偏移量,而Anchor表则描述了mark的attachment点。一个mark类别用一个称为类别值的特殊整数来标识。(关于类别的更详细的信息,请参考章节,OpenType通用表格式。) ClassCount指定了定义在MarkRecords中不同的mark类别的总个数。
MarkMarkPosFormat1子表也包含两个偏移量,由该子表的起始位置算起,指向两个数组:
- MarkArray表以Mark1Coverage Index的顺序将所有的MarkRecords包含于一个数组中(MarkRecord)。MarkArray表也包含有所定义的MarkRecords的个数(MarkCount)。
- Mark2Array表由一个数组(Mark2Record)和Mark2Records的个数(Mark2Count)组成。
关于MarkArrays和MarkRecords的详细信息,请参考本章的末尾处的说明。
MarkMarkPosFormat1 subtable: MarkToMark attachment
| Value | Type | Description |
|---|---|---|
| uint16 | PosFormat | Format identifier-format = 1 |
| Offset | Mark1Coverage | Offset to Combining Mark Coverage table-from beginning of MarkMarkPos subtable |
| Offset | Mark2Coverage | Offset to Base Mark Coverage table-from beginning of MarkMarkPos subtable |
| uint16 | ClassCount | Number of Combining Mark classes defined |
| Offset | Mark1Array | Offset to MarkArray table for Mark1-from beginning of MarkMarkPos subtable |
| Offset | Mark2Array | Offset to Mark2Array table for Mark2-from beginning of MarkMarkPos subtable |
Mark2Array,接下来显示,为Mark2Coverage表中所列的每个Mark2 glyph包含有一个Mark2Record。它以与Mark2Coverage Index相同的顺序存储那些records。
Mark2Array table
| Value | Type | Description |
|---|---|---|
| uint16 | Mark2Count | Number of Mark2 records |
| struct | Mark2Record [Mark2Count] | Array of Mark2 records-in Coverage order |
每个Mark2Record包含一个到Anchor表的偏移量的数组(Mark2Anchor)。基于0的偏移量数组,由Mark2Array表的起始位置算起,定义了用于将Mark1 glyphs依附于一个特定的Mark2 glyph的Mark2 attachment点的完整集合。Mark2Anchor数组中的Anchor表以Mark1的类别值来排序。
一个Mark2Record会为MarkArray的MarkRecords中所确定的每个mark类别(包括 Class 0)都声明一个Anchor表。每个Anchor表描述一个用于将一个特定类别中所有的Mark1 glyph依附于相应的Mark2 glyph上的Mark2 attachment点。
本章结尾处的示例9显示了一个在Arabic script中,用于将一个mark依附于另一个mark的MarkMarkPosFormat1子表。
Mark2Record
| Value | Type | Description |
|---|---|---|
| Offset | Mark2Anchor [ClassCount] | Array of offsets (one per class) to Anchor tables-from beginning of Mark2Array table-zero-based array |
Lookup Type 7: Contextual Positioning Subtables
ContextPositoning(ContextPos)子表定义了最为强大的一种glyph定位lookup类型。它描述了上下文中的glyph定位操作,从而一个文字处理客户端可以调整某一glyphs模式中的一个或多个glyphs的位置。每个子表描述了一个或多个“输入”glyph序列及将会在那个序列上执行的一个或多个定位操作。
ContextPos可以是三种格式中的一种,这三种格式与用于上下文glyph置换的格式对应。一种格式。一种格式适用于特定的glyph序列(Format 1),一种按照glyph类别来定义上下文(Format 2),而第三种格式则依照glyphs集合来定义上下文(Format 2)。
ContextPos子表的所有三种格式都在一个PosLookupRecord中描述定位数据。下面是那种record的一个描述。
PosLookupRecord
所有的上下文定位子表都在一个PosLookupRecord中描述定位数据。每个record包含一个SequenceIndex,它指示了glyph序列中定位操作所发生的地方。此外,一个LookupListIndex确定了将在由SequenceIndex所指示的glyph位置上应用的lookup。
lookups被应用于整个glyph序列的顺序,被称为“设计顺序”,可能是非常重要的,因而,PosLookupRecord数据也应该照着来定义。
示例10,11和12中所定义的上下文定位表展示了PosLookupRecords。
PosLookupRecord
| Value | Type | Description |
|---|---|---|
| uint16 | SequenceIndex | Index to input glyph sequence-first glyph = 0 |
| uint16 | LookupListIndex | Lookup to apply to that position-zero-based |
Context Positioning Subtable: Format 1
Format 1将一个glyph定位操作的上下文定义为一个特定的glyphs序列。比如,一个上下文可能是<To>,<xyzabc>,<!?*#@>或任何其他的glyph序列。
在上下文内,Format 1将特定的一些glyph位置(不是glyph索引)标识为特定的调整的目标。当文本处理客户端定位到了一个子串中的一个上下文时,它通过应用为一个目标位置所定义的lookup data来执行位置调整。
比如,suppose that accent mark glyphs above lowercase x-height vowel glyphs must be lowered when an overhanging capital letter glyph precedes the vowel。当客户端在文字中定位到了这个上下文时,相应的子表确定了重音符号的位置及一个lookup索引。一个lookup详述了一个降低元音上的重音符号的位置以使得它不与overhanging capital产生冲突的定位行为。
ContextPosFormat1在两个地方定义上下文。一个Coverage表详述了输入序列中的第一个glyph,而一个PosRule表则确定了其余的glyphs。为了描述前面例子中使用的上下文,Coverage表列出了那个序列的第一个组件的glyph索引(overhanging capital),而一个PosRule表则为lowercase x-height vowel glyph和重音符号定义了索引。
一个单独的ContextPosFormat1子表也许会定义多于一个上下文glyph序列。如果不同的上下文序列以相同的glyph开始,则相应的Coverage表应该只列出那个glyph一次,因为Coverage表中所有的首glyphs都必须是唯一的。比如,如果有三个上下文每个都以一个“s”开始,有两个上下文每个都以一个“t”开始,则相应的Coverage表中将只列出一个“s”和一个“t”。
对于每个上下文,会有一个PosRule表顺序列出所有跟在首glyph后面的glyphs。这个表也包含有一个PosLookupRecords的数组,其中为上下文中的每个glyph位置(包括第一个glyph位置)详述了定位lookup数据。
所有定义了以相同的首glyph开始的上下文的PosRule会被分为一组并被定义在一个PosRuleSet表中。比如,三个定义了以“s”开头的上下文的PosRule表被分为一组并放进一个PosRuleSet表中,两个定义了以t”开头的上下文的PosRule表被分为一组并放进另一个PosRuleSet表中。Coverage表中所列出的每个唯一的glyph都必须具有一个PosRuleSet表来为一个覆盖的glyph定义所有的PosRule表。
为了定位一个上下文glyph序列,文本处理客户端在每次遇到一个新的文字glyph时都会在Coverage表中搜索。如果Coverage表中存在那个glyph,则客户端就读取对应的PosRuleSet表并检查这个集合中的每个PosRule表来确定其中定义的上下文的剩余部分是否与文字中后面的glyphs匹配。如果上下文与子串匹配,则客户端会查找目标glyph位置,为那个位置应用相应的lookup,并完成定位行为。
一个ContextPosFormat1子表包含一个格式标识符(PosFormat),一个到一个Coverage表的偏移量(Coverage),一个所定义的PosRuleSets的个数(PosRuleSetCount),及一个到PosRuleSet表的偏移量的数组(PosRuleSet)。如前所述,必须为Coverage表中所列出的每个glyph定义一个PosRuleSet表。
在PosRuleSet数组中,PosRuleSet表是以Coverage Index的顺序排序的。数组中的第一个PosRuleSet应用于Coverage表中所列出的第一个GlyphID,数组中的第二个PosRuleSet应用于Coverage表中所列出的第二个GlyphID,依此类推。
ContextPosFormat1 subtable: Simple context positioning
| Value | Type | Description |
|---|---|---|
| uint16 | PosFormat | Format identifier-format = 1 |
| Offset | Coverage | Offset to Coverage table-from beginning of ContextPos subtable |
| uint16 | PosRuleSetCount | Number of PosRuleSet tables |
| Offset | PosRuleSet [PosRuleSetCount] | Array of offsets to PosRuleSet tables-from beginning of ContextPos subtable-ordered by Coverage Index |
一个PosRuleSet表由一个以任意顺序排列的到PosRule表的偏移量的数组(PosRule),及集合中所定义的PosRule表的个数(PosRuleCount)组成。
PosRuleSet table: All contexts beginning with the same glyph
| Value | Type | Description |
|---|---|---|
| uint16 | PosRuleCount | Number of PosRule tables |
| Offset | PosRule [PosRuleCount] | Array of offsets to PosRule tables-from beginning of PosRuleSet-ordered by preference |
一个PosRule表包含有一个输入上下文序列中被匹配的glyphs的个数(GlyphCount),包括序列中的第一个glyph,及描述了那个上下文的glyph索引的数组(Input)。Coverage表说明了上下文中第一个glyph的索引,则Input数组以上下文序列中的第二个glyph开始。因此,数组中的第一个索引位置是指定数组1,而不是0。Input数组以对应的glyphs出现的顺序列出了字串中的glyph索引。对于自右向左书写的文本,最右端的glyph将是第一个;相反地,对于自左向右书写的文本,最左端的glyph将是第一个。
一个PosRule表也包含一个将在输入glyph序列上被执行的定位操作的个数(PosCount)及一个PosLookupRecords的数组(PosLookupRecord)。每个record都指定了一个输入glyph序列中的位置,及一个将在那个位置应用的定位lookup的LookupList索引。数组应该以设计顺序列出记录,或者lookups应该被应用于整个glyph序列的顺序。
本章结尾处的示例10演示了通过一个ContextPosFormat1子表来实现的上下文中的glyph kerning。
PosRule subtable
| Value | Type | Description |
|---|---|---|
| uint16 | GlyphCount | Number of glyphs in the Input glyph sequence |
| uint16 | PosCount | Number of PosLookupRecords |
| GlyphID | Input [GlyphCount - 1] | Array of input GlyphIDs-starting with the second glyph |
| struct | PosLookupRecord[PosCount] | Array of positioning lookups-in design order |
Context Positioning Subtable: Format 2
Format2,相对于Format1更加灵活,描述了基于类别的上下文定位。对于这种格式,一个称为类别值的特定整数必须被分配给所有的上下文glyph序列中的每个glyph组件。然后上下文被定义为glyph类别值的序列。这种子表可能在同一时间定义多个的上下文。
为了阐明基于类别的上下文规则的概念,设想某些三glyphs的序列需要特殊的kerning。该glyph序列由一个悬在右边的大写字母glyph,一个标点符号glyph,及一个引用(quote) glyph组成。在这种情况下,大写字母glyphs的集合将构成一个glyph类别(Class 1),标点符号glyph的集合将构成第二个glyph类别(Class 2),及引用符号glyphs的集合将构成第三个glyph类别(Class 3)。输入上下文也许会用一个上下文规则来指定(PosClassRule),其中规则描述为“形成了三glyphs类别序列的glyph串的集合,一个glyph来自于Class 1,后面跟一个来自于Class 2的glyph,再后面跟一个来自于Class 3的glyph。”
每个ContextPosFormat2子表都包含一个到一个类别定义表的偏移量(ClassDef),其中定义了该子表描述的输入上下文中所有的glyphs的类别值。通常,会为一个字库中包含的每一个ContextPosFormat2子表实例都声明一个唯一的ClassDef,尽管多个Format 2子表也可以共享ClassDef表。类别是互斥集;在同一时间一个glyph不能属于多个类别。替换上下文序列中的glyphs的输出glyphs不需要类别值,因为它们是在其他地方用GlyphID来描述的。
ContextPosFormat2子表也包含一个格式标识符(PosFormat),并定义有一个到一个Coverage表的偏移量(Coverage)。对于这种格式,Coverage表将列出可能成为任何一个基于类别的上下文的首glyph的glyphs的完整集合中每个glyph的glyph索引(而不是类别)。换句话说,Coverage表为所有的上下文类别序列中可能成为首class的所有classes中包含的glyphs包含了glyph索引的列表。比如,如果上下文以一个Class 1或Class 2的glyph开始,则Coverage表将列出所有Class 1和Class 2 glyphs的索引。一个ContextPosFormat2子表也定义了一个到PosClassSet表的偏移量的数组(PosClassSet),及一个PosClassSet表的个数(包括Class 0)(PosClassSetCnt)。在该数组中,PosClassSet表以类别值的升序(从0到PosClassSetCnt - 1)来排序。
一个PosClassSet数组为每种glyph类别都包含一个偏移量,包括Class 0。PosClassSets不是显式地用一个类别值来标记的;而是,PosClassSet在PosClassSet数组中的索引值定义了一个PosClassSet所表示的类别。比如,数组中所列的第一个PosClassSet包含所有定义了以一个Class 0 glyphs为起始glyph的上下文的PosClassRules,第二个PosClassSet包含所有定义了以一个Class 1 glyphs为起始glyph的上下文的PosClassRules,依此类推。如果没有以一个特定类别开始的PosClassRules(即,如果一个PosClassSet不包含有PosClassRules),则PosClassSet数组中到那个特定的PosClassSet的偏移量将被设为NULL。
ContextPosFormat2 subtable: Class-based context glyph positioning
| Value | Type | Description |
|---|---|---|
| uint16 | PosFormat | Format identifier-format = 2 |
| Offset | Coverage | Offset to Coverage table-from beginning of ContextPos subtable |
| Offset | ClassDef | Offset to ClassDef table-from beginning of ContextPos subtable |
| uint16 | PosClassSetCnt | Number of PosClassSet tables |
| Offset | PosClassSet [PosClassSetCnt] | Array of offsets to PosClassSet tables-from beginning of ContextPos subtable-ordered by class-may be NULL |
定义了以相同的类别为起始类别的上下文的所有的PosClassRules被分组在一起并被定义在一个PosClassSet表中。因此,PosClassSet表本身确定了一个上下文的第一个组件的类别。
一个PosClassSet枚举了所有以一个特定的glyph类别开始的PosClassRules。比如PosClassSet0表示所有的PosClassRules,其中的每一个都描述了以Class 0 glyph开始的上下文;PosClassSet1表示所有的PosClassRules,其中的每一个都描述了以Class 1 glyph开始的上下文。
每个PosClassSet表由一个该PosClassSet中所定义的PosClassRules的个数(PosClassRuleCnt)及一个到PosClassRule表的偏移量的数组(PosClassRule)组成。PosClassSet的PosClassRule数组中的PosClassRule以任意顺序排序。
PosClassSet table: All contexts beginning with the same class
| Value | Type | Description |
|---|---|---|
| uint16 | PosClassRuleCnt | Number of PosClassRule tables |
| Offset | PosClassRule[PosClassRuleCnt] | Array of offsets to PosClassRule tables-from beginning of PosClassSet-ordered by preference |
对于每个上下文,一个PosClassRule表为它包含了一个给定上下文中glyph类别的个数(GlyphCount),包括上下文序列中的第一个类别。一个类别数组列出了所有的类别,从第二个类别开始,即上下文中跟在第一个类别后面的类别。所列出的第一个类别表示了上下文序列中的第二个位置。
注意:文本的顺序依赖于文字的书写方向。对于自右向左书写的文字,最右端的glyph将是第一个。相反地,对于自左向右书写的文字,最左端的glyph将是第一个。
Class数组中描述的值是那些定义在ClassDef表中的值。比如,考虑一个上下文序列:Class 2,Class 7,Class 5,Class 0。Class数组将是:Class[0] = 7,Class[1] = 5,Class[2] = 0。序列中的第一个类别Class 2,是通过到偏移量的PosClassSet数组的索引值来定义的。Class数组中所列出的glyph类别总数及序列必须与输入上下文中包含的glyphs类别总数及序列相匹配。
一个PosClassRule也包含一个将在上下文上执行的定位操作的个数(PosCount)及一个PosLookupRecords的数组(PosLookupRecord),其中数组提供了定位数据。对于上下文中需要一个定位操作的每个位置,会有一个PosLookupRecord确定了一个LookupList索引及一个输入glyph类别序列中的位置,其中lookup将在此位置被应用。PosLookupRecord数组以设计顺序列出了PosLookupRecords,或者lookups将被应用于整个glyph序列的顺序。
本章结尾处的示例11演示了一个ContextPosFormat2子表,它用glyph类别来改变glyph串中重音符号的位置。
PosClassRule table: One class context definition
| Value | Type | Description |
|---|---|---|
| uint16 | GlyphCount | Number of glyphs to be matched |
| uint16 | PosCount | Number of PosLookupRecords |
| uint16 | Class [GlyphCount - 1] | Array of classes-beginning with the second class-to be matched to the input glyph sequence |
| struct | PosLookupRecord[PosCount] | Array of positioning lookups-in design order |
Context Positioning Subtable: Format 3
Format3,基于Coverage的上下文定位,将一个上下文规则定义为一个Coverage的序列。序列中的每个位置为与上下文模式匹配的glyphs集合确定了一个不同的Coverage表。通过Format 3,定义在不同Coverage表中的glyph集合可能有交叉,而不像Format 2那样为lookup确定了固定的类别分配值(上下文序列中的每个位置都是一致的)和独有的类别(一个glyph不能同时属于多个类别)。
比如,考虑一个输入上下文,它包含一个大写字母glyph(位置0),后面跟着一个窄的大写字母glyph(位置1),然后是另一个大写字母glyph(位置2)。这个上下文需要3个Coverage表,每个位置一个:
- 在位置0,即第一个位置,其Coverage表将列出所有大写字母glyphs的集合。
- 在位置1,即第二个位置,其Coverage表将列出所有的窄的大写字母glyphs的集合,它是位置0所对应的Coverage表中所列出的glyphs的一个子集。
- 在位置2,其Coverage表将再次列出所有的大写字母glyphs的集合。
注意:位置0和位置2可以使用相同的Coverage表。
不像Format 1和2,这种格式在同一时间只定义一个上下文规则。它由一个格式标识符(PosFormat),一个将被匹配的序列中glyphs的个数(GlyphCount),及描述了输入上下文序列的一个Coverage偏移量的数组(Coverage)组成。
注意:Coverage数组中所列出的Coverage表必须是依据于书写方向的文字顺序而列出的。对于自右向左书写的文字,最右端的glyph将是第一个。相反地,对于自左向右书写的文字,最左端的glyph将是第一个。
这个子表也包含一个将在输入Coverage序列上被执行的定位操作的个数(PosCount)及一个以设计顺序排序或以lookups被应用于整个glyph序列的顺序排序的PosLookupRecords的数组(PosLookupRecord),
本章结尾处的示例12通过一个ContextPosFormat3子表来改变数学方程式中数学符号glyphs的位置。
ContextPosFormat3 subtable: Coverage-based context glyph positioning
| Value | Type | Description |
|---|---|---|
| uint16 | PosFormat | Format identifier-format = 3 |
| uint16 | GlyphCount | Number of glyphs in the input sequence |
| uint16 | PosCount | Number of PosLookupRecords |
| Offset | Coverage [GlyphCount] | Array of offsets to Coverage tables-from beginning of ContextPos subtable |
| struct | PosLookupRecord [PosCount] | Array of positioning lookups-in design order |
LookupType 8: Chaining Contextual Positioning Subtable
一个Chaining Contextual Positioning子表(ChainContextPos)描述了上下文中的glyph定位操作,而同时具有一种在glyphs序列中向后看(look back)和/或向前看(look ahead)的能力。Chaining Contextual Positioning子表的设计与Contextual Positioning子表的设计是并行的,它也有三种格式可用。
为了描述上下文,Coverage表列出输入序列中的第一个glyph,而ChainPosRule子表定义其余的。一旦在位置i处发现了一个覆盖的glyph,则客户端会读取对应的ChainPosRuleSet表,并检查其中的每个表,来决定它是否与文本中周围的glyphs匹配。如果字串<backtrack sequence>+<input sequence>+<lookahead sequence>与文本中位置i- BacktrackGlyphCount处的glyphs匹配。
如果有一个匹配,则客户端会为定位操作查找目标glyphs,并执行该操作。请注意(像在ContextPosFormat1子表中那样)这些lookups需要在文字中被覆盖的glyph到输入序列结尾处这一个范围内来执行。不会为backtracking序列及lookahead序列定义定位操作。
为了给input,backtrack和lookahead序列阐明glyph数组的排列,而提供下面的描述。Input序列从i处开始匹配,此处也是输入序列匹配的开始的位置。backtrack序列从i - 1处开始排列,并且随着逐渐的远离i处而增加偏移值。lookahead序列从输入序列后面的位置开始,并以逻辑顺序递增。
| Logical order - | a | b | c | d | e | f | g | h | i | j |
| i | ||||||||||
| Input sequence - | 0 | 1 | ||||||||
| Backtrack sequence - | 3 | 2 | 1 | 0 | ||||||
| Lookahead sequence - | 0 | 1 | 2 | |
Chaining Context Positioning Format 1: Simple Chaining Context Glyph Positioning
这种格式与Context Positioning lookup的Format 1一直,除了它用一个ChainPosRule表替换了PosRule表。(相应地,ChainPosRuleSet表与PosRuleSet表的不同之处也仅仅在于它是列出了到ChainPosRule子表的偏移量,而不是PosRule表;ChainContextPosFormat1子表是列出了到ChainPosRuleSet子表的偏移量而不是PosRuleSet子表。)
ChainContextPosFormat1 subtable: Simple context positioning
| Value | Type | Description |
|---|---|---|
| uint16 | PosFormat | Format identifier-format = 1 |
| Offset | Coverage | Offset to Coverage table-from beginning of ContextPos subtable |
| uint16 | ChainPosRuleSetCount | Number of ChainPosRuleSet tables |
| Offset | ChainPosRuleSet [ChainPosRuleSetCount] | Array of offsets to ChainPosRuleSet tables-from beginning of ContextPos subtable-ordered by Coverage Index |
一个ChainPosRuleSet表由一个以任意顺序排序的到ChainPosRule表的偏移量的数组(ChainPosRule),及集合中所定义的ChainPosRule表的个数(ChainPosRuleCount)组成。
ChainPosRuleSet table: All contexts beginning with the same glyph
| Value | Type | Description |
|---|---|---|
| uint16 | ChainPosRuleCount | Number of ChainPosRule tables |
| Offset | ChainPosRule [ChainPosRuleCount] | Array of offsets to ChainPosRule tables-from beginning of ChainPosRuleSet-ordered by preference |
ChainPosRule subtable
| Type | Name | Description |
|---|---|---|
| uint16 | BacktrackGlyphCount | Total number of glyphs in the backtrack sequence (number of glyphs to be matched before the first glyph) |
| GlyphID | Backtrack [BacktrackGlyphCount] | Array of backtracking GlyphID's (to be matched before the input sequence) |
| uint16 | InputGlyphCount | Total number of glyphs in the input sequence (includes the first glyph) |
| GlyphID | Input [InputGlyphCount - 1] | Array of input GlyphIDs (start with second glyph) |
| uint16 | LookaheadGlyphCount | Total number of glyphs in the look ahead sequence (number of glyphs to be matched after the input sequence) |
| GlyphID | LookAhead [LookAheadGlyphCount] | Array of lookahead GlyphID's (to be matched after the input sequence) |
| uint16 | PosCount | Number of PosLookupRecords |
| struct | PosLookupRecord [PosCount] | Array of PosLookupRecords (in design order) |
Chaining Context Positioning Format 2: Class-based Chaining Context Glyph Positioning
这种lookup格式与Context Positioning格式2是平行的,只是将PosClassSet子表变为ChainPosClassSet,并将PosClassRule子表变为ChainPosClassRule子表。
为了链接上下文,三种类别被用于glyph ClassDef表:Backtrack ClassDef,Input ClassDef,和Lookahead ClassDef。
ChainContextPosFormat2 subtable: Chaining class-based context glyph positioning
| Value | Type | Description |
|---|---|---|
| uint16 | PosFormat | Format identifier-format = 2 |
| Offset | Coverage | Offset to Coverage table-from beginning of ChainContextPos subtable |
| Offset | BacktrackClassDef | Offset to ClassDef table containing backtrack sequence context-from beginning of ChainContextPos subtable |
| Offset | InputClassDef | Offset to ClassDef table containing input sequence context-from beginning of ChainContextPos subtable |
| Offset | LookaheadClassDef | Offset to ClassDef table containing lookahead sequence context-from beginning of ChainContextPos subtable |
| uint16 | ChainPosClassSetCnt | Number of ChainPosClassSet tables |
| Offset | ChainPosClassSet [ChainPosClassSetCnt] | Array of offsets to ChainPosClassSet tables-from beginning of ChainContextPos subtable-ordered by input class-may be NUL |
定义了以相同的类别开始的上下文的所有的ChainPosClassRules被分组在一起并被定义在一个ChainPosClassSet表中。因此,ChainPosClassSet表确定了一个上下文第一个组件的类别。
ChainPosClassSet table: All contexts beginning with the same class
| Value | Type | Description |
|---|---|---|
| uint16 | ChainPosClassRuleCnt | Number of ChainPosClassRule tables |
| Offset | ChainPosClassRule[ChainPosClassRuleCnt] | Array of offsets to ChainPosClassRule tables-from beginning of ChainPosClassSet-ordered by preference |
ChainPosClassRule subtable
| Type | Name | Description |
|---|---|---|
| uint16 | BacktrackGlyphCount | Total number of glyphs in the backtrack sequence (number of glyphs to be matched before the first glyph) |
| uint16 | Backtrack [BacktrackGlyphCount] | Array of backtracking classes(to be matched before the input sequence) |
| uint16 | InputGlyphCount | Total number of classes in the input sequence (includes the first class) |
| uint16 | Input [InputGlyphCount - 1] | Array of input classes(start with second class; to be matched with the input glyph sequence) |
| uint16 | LookaheadGlyphCount | Total number of classes in the look ahead sequence (number of classes to be matched after the input sequence) |
| uint16 | LookAhead [LookAheadGlyphCount] | Array of lookahead classes(to be matched after the input sequence) |
| uint16 | PosCount | Number of PosLookupRecords |
| struct | PosLookupRecord [ChainPosCount] | Array of PosLookupRecords (in design order) |
Chaining Context Positioning Format 3: Coverage-based Chaining Context Glyph Positioning
Format3将一个链接上下文规则定义为一个Coverage表的序列。序列中的每个位置为与上下文模式匹配的glyphs集合定义了一个不同的Coverage表。通过Format 3,不同的Coverage表中所定义的glyph集合可能会交叉,不像Format 2那样确定了固定的类别分配值(backtrack,input或者lookahead序列中的每个位置都是一致的)和独有的类别(一个glyph不能同时属于多个类别)。
注意:Coverage数组中所列出的Coverage表的顺序必须遵从书写的方向。对于自右向左书写的文字,则最右端的glyph将是第一个。相反地,对于自左向右书写的文字,最左端的glyph将会是第一个。
这种子表也包含一个输入Coverage序列上将被执行的定位操作的个数(PosCount)及一个以设计顺序排序的PosLookupRecords的数组(PosLookupRecord):即,lookups应该被应用于整个glyph序列的顺序。
ChainContextPosFormat3 subtable: Coverage-based chaining context glyph positioning
| Type | Name | Description |
|---|---|---|
| uint16 | PosFormat | Format identifier-format = 3 |
| uint16 | BacktrackGlyphCount | Number of glyphs in the backtracking sequence |
| Offset | Coverage[BacktrackGlyphCount] | Array of offsets to coverage tables in backtracking sequence, in glyph sequence order |
| uint16 | InputGlyphCount | Number of glyphs in input sequence |
| Offset | Coverage[InputGlyphCount] | Array of offsets to coverage tables in input sequence, in glyph sequence order |
| uint16 | LookaheadGlyphCount | Number of glyphs in lookahead sequence |
| Offset | Coverage[LookaheadGlyphCount] | Array of offsets to coverage tables in lookahead sequence, in glyph sequence order |
| uint16 | PosCount | Number of PosLookupRecords |
| struct | PosLookupRecord [PosCount] | Array of PosLookupRecords,in design order |
LookupType 9: Extension Positioning
这中lookup提供了一种机制,以帮助在‘GPOS’表中将任何其他lookup类型的子表存储在一个32-bit偏移量的位置处。如果子表的总大小超出了‘GPOS’表中各种其他的偏移量都会有的16-bts的限制,则会需要用到这种表。这份规范中,把存储在32-bt偏移量位置处的子表称作“扩展”子表。
ExtensionPosFormat1 subtable
| Type | Name | Description |
|---|---|---|
| USHORT | PosFormat | Format identifier. Set to 1. |
| USHORT | ExtensionLookupType | Lookup type of subtable referenced by ExtensionOffset (i.e. the extension subtable). |
| ULONG | ExtensionOffset | Offset to the extension subtable, of lookup type ExtensionLookupType, relative to the start of the ExtensionPosFormat1 subtable. |
ExtensionLookupType必须被设为任何其它的lookup类型而不是9。一个LookupType 9 lookup中的所有子表必须具有相同的ExtensionLookupType。扩展子表中所有的偏移量以平常的方式设置,比如,相对于扩展子表本身。
当一个OpenType layout引擎遇到一个LookupType 9 Lookup表时,它应该:
- 就像Lookup表的LookupType成员被设为了其子表的ExtensionLookupType一样来处理。
- 就像由ExtensionOffset所引用的每个扩展子表替换了引用它的LookupType 9 子表一样来处理。
共享的表:ValueRecord,Anchor Table和MarkArray
本章前面描述的一些lookup子表为定位操作的数据而引用了一个或多个相同的表:ValueRecord,Anchor Table和MarkArray。为了便于查询,那些共享的表在此处描述。
本章结尾处的示例14使用了一个ValueFormat表和ValueRecord来在GPOS中描述定位操作的值。
ValueRecord
GPOS子表使用ValueRecord来描述所有用于调整一个glyph或glyphs集合的位置的变量和值。一个ValueRecord可能定义加到(正值)字库中提供的placement和advance上或从中减掉(负值)的任意的X和Y值的组合(以设计单位)。一个ValueRecord也可能为每个特定的值包含一个到一个Device表的偏移量。如果一个ValueRecord描述了多个值,则这些值应该以ValueRecord定义中所显示的顺序列出。
文字处理客户端必须意识到GPOS表中ValueRecord灵活的和多维的属性。由于GPOS表为多种目的而使用ValueRecords,则ValueRecords的大小和内容也许会在子表之间有所不同。
ValueRecord (all fields are optional)
| Value | Type | Description |
|---|---|---|
| int16 | XPlacement | Horizontal adjustment for placement-in design units |
| int16 | YPlacement | Vertical adjustment for placement-in design units |
| int16 | XAdvance | Horizontal adjustment for advance-in design units (only used for horizontal writing) |
| int16 | YAdvance | Vertical adjustment for advance-in design units (only used for vertical writing) |
| Offset | XPlaDevice | Offset to Device table for horizontal placement-measured from beginning of PosTable (may be NULL) |
| Offset | YPlaDevice | Offset to Device table for vertical placement-measured from beginning of PosTable (may be NULL) |
| Offset | XAdvDevice | Offset to Device table for horizontal advance-measured from beginning of PosTable (may be NULL) |
| Offset | YAdvDevice | Offset to Device table for vertical advance-measured from beginning of PosTable (may be NULL) |
一个数据格式(ValueFormat),常常在每个GPOS子表的开始处声明,定义了ValueRecords描述的位置调整数据的类型。通常,相同的ValueFormat会应用于特定的GPOS子表中定义的每个ValueRecord。
ValueFormat决定了ValueRecords:
- 应用于placement,advance,或两者都有。
- 应用于水平定位(X 坐标),竖直定位(Y坐标),或两者均有。
- 可能会为特定的值中的任何一些引用一个或多个Device表。
ValueFormat中的每一个位对应于ValueRecord中的一个成员,并且将ValueRecord的大小增加2字节。一个0x0000的ValueFormat对应于一个空的ValueRecord,它表示没有位置的改变。为了标识每个ValueRecord中的成员ValueRecord使用了下面所示的位设定。为了用一个ValueFormat描述多个成员,则相关成员的位设定通过一个逻辑OR操作而被加在一起。
比如,为了调整一个glyph的左边bearing,则ValueFormat将被设为0x0001,而ValueRecord将定义XPlacement值。为了调整一个不同的glyph的advance宽度,其ValueFormat将是0x0004,而ValueRecord将描述XAdvance值。为了同时调整一个glyphs集合的XPlacement和XAdvance,其ValueFormat将是0x0005,而ValueRecord将以它们在ValueRecord定义中列出的顺序描述着两者。
ValueFormat bit enumeration (indicates which fields are present)
| Mask | Name | Description |
|---|---|---|
| 0x0001 | XPlacement | Includes horizontal adjustment for placement |
| 0x0002 | YPlacement | Includes vertical adjustment for placement |
| 0x0004 | XAdvance | Includes horizontal adjustment for advance |
| 0x0008 | YAdvance | Includes vertical adjustment for advance |
| 0x0010 | XPlaDevice | Includes horizontal Device table for placement |
| 0x0020 | YPlaDevice | Includes vertical Device table for placement |
| 0x0040 | XAdvDevice | Includes horizontal Device table for advance |
| 0x0080 | YAdvDevice | Includes vertical Device table for advance |
| 0xF000 | Reserved | For future use (set to zero) |
Anchor表
一个GPOS表使用锚点(anchor point)来定位一个glyph相对于另一个的位置。每个glyph定义一个锚点,文字处理客户端通过对齐它们对应的锚点来附上glyphs。
为了描述一个锚点,一个Anchor表可以使用三种格式中的一种。第一种格式使用设计单位来为锚点确定一个位置。另外两种格式使用轮廓点(Format 2)或设备表(Foramt 3)来改善锚点的位置。
Anchor Table: Format 1
AnchorFormat1由一个格式标识符(AnchorFormat)和描述了锚点位置的一对设计单位的坐标(XCoordinate和YCoordinate)组成。这种格式的好处是大小比较小,而且比较简单,但锚点无法被hinted来为不同设备分辨率调整它的位置。
本章结尾处的示例15使用了AnchorFormat1。
AnchorFormat1 table: Design units only
| Value | Type | Description |
|---|---|---|
| uint16 | AnchorFormat | Format identifier-format = 1 |
| int16 | XCoordinate | Horizontal value-in design units |
| int16 | YCoordinate | Vertical value-in design units |
Anchor Table: Format 2
像AnchorFormat1一样,AnchorFormat2指定了一个格式标识符(AnchorFormat),并为锚点指定了一对设计单位的坐标(Xcoordinate和Ycoordinate)。
为了微调锚点的位置,AnchorFormat2也提供了在一个glyph的轮廓上的一个glyph轮廓点的索引(AnchorPoint)。Hinting可以被用于移动AnchorPoint。在被渲染的文字中,AnchorPoint将为一个给定的ppem大小提供最终的位置调整数据。
本章结尾处的示例16使用AnchorFormat2。
AnchorFormat2 table: Design units plus contour point
| Value | Type | Description |
|---|---|---|
| uint16 | AnchorFormat | Format identifier-format = 2 |
| int16 | XCoordinate | Horizontal value-in design units |
| int16 | YCoordinate | Vertical value-in design units |
| uint16 | AnchorPoint | Index to glyph contour point |
Anchor Table: Format 3
像AnchorFormat1一样,AnchorFormat3也指定了一个格式标识符(AnchorFormat)并定位了一个锚点(Xcoordinate和Ycoordinate)。并且,像AnchorFormat2一样,它允许对坐标值进行优调。然而,AnchorFormat3是使用Device表,而不是一个轮廓点来做调整。
通过一个Device表,一个客户端可以为任何字体大小和设备分辨率来调整锚点的位置。AnchorFormat3可以为X坐标(XDeviceTable)和Y坐标(YDeviceTable)指定到Device表的偏移量。如果只有一个坐标需要调整,则另一个坐标其到Device表的偏移量可以被设为NULL。
本章结尾处的示例17显示了一个AnchorFormat3表。
AnchorFormat3 table: Design units plus Device tables
| Value | Type | Description |
|---|---|---|
| uint16 | AnchorFormat | Format identifier-format = 3 |
| int16 | XCoordinate | Horizontal value-in design units |
| int16 | YCoordinate | Vertical value-in design units |
| Offset | XDeviceTable | Offset to Device table for X coordinate- from beginning of Anchor table (may be NULL) |
| Offset | YDeviceTable | Offset to Device table for Y coordinate- from beginning of Anchor table (may be NULL) |
Mark Array
MarkArray表为一个mark glyph定义了类别和锚点。三种GPOS子表-MarkToBase,MarkToLigature和MarkToMark Attachment-使用了MarkArray表来为attaching mark描述数据。
MarkArray表包含一个mark记录的个数(MarkCount)及一个那些记录的数组(MarkRecord)。每个mark记录都定义了mark的类别及一个到为那个mark包含了数据的Anchor表的偏移量。
一个类别值可能是0,但MarkRecord必须显式地分配那个类别值(这不同于ClassDef表,ClassDef表中所有未分配类别值的glyphs自动地属于Class 0)。引用了MarkArray表的GPOS子表use the class assignments for indexing zero-based arrays that contain data for each mark class。
本章结尾处的示例18中,一个MarkArray表和两个MarkRecords定义了两个mark类别。
MarkArray table
| Value | Type | Description |
|---|---|---|
| uint16 | MarkCount | Number of MarkRecords |
| struct | MarkRecord [MarkCount] | Array of MarkRecords-in Coverage order |
MarkRecord
| Value | Type | Description |
|---|---|---|
| uint16 | Class | Class defined for this mark |
| Offset | MarkAnchor | Offset to Anchor table-from beginning of MarkArray table |
GPOS Subtable Examples
本章的剩余部分将描述一些GPOS子表的例子。
Done















 968
968

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









