






1、介绍
KNN是k nearest neighbor 的简称,即k最邻近,就是找k个最近的实例投票决定新实例的类标。KNN是一种基于实例的学习算法,它不同于贝叶斯、决策树等算法,KNN不需要训练,当有新的实例出现时,直接在训练数据集中找k个最近的实例,把这个新的实例分配给这k个训练实例中实例数最多类。KNN也成为懒惰学习,它不需要训练过程,在类标边界比较整齐的情况下分类的准确率很高。KNN算法需要人为决定K的取值,即找几个最近的实例,k值不同,分类结果的结果也会不同。
2、举例
看如下图的训练数据集的分布,该数据集分为3类(在图中以三种不同的颜色表示),现在出现一个待分类的新实例(图中绿色圆点),假设我们的K=3,即找3个最近的实例,这里的定义的距离为欧氏距离,这样找据该待分类实例最近的三个实例就是以绿点为中心画圆,确定一个最小的半径,使这个圆包含K个点。
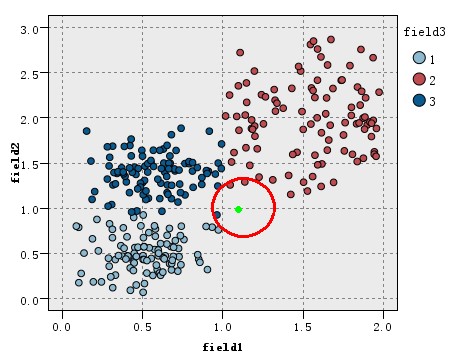
如图所示,可以看到红圈包含的三个点中,类别2中有三个,类别3有一个,而类别1一个也没有,根据少数服从多数的原理投票,这个绿色的新实例应属于2类。
3、K值的选取。
之前说过,K值的选取,将会影响分类的结果,那么K值该取多少合理。我们继续上面提到的分类过程,现在我们把K设置为为7,如下图所示:
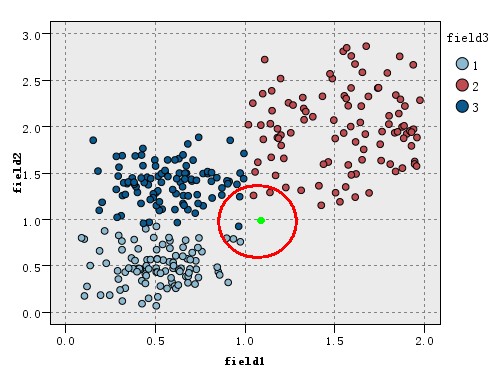
可以看到当k=7时,最近的7个点中1类有三个,2类和3类都有两个,这时绿色的新实例应该分给1类,这与K=5时的分类结果不同。
K值的选取没有一个绝对的标准,但可以想象,K取太大并不能提高正确率,而且求K个最近的邻居是一个O(K*N)复杂度的算法,k太大,算法效率会更低。
虽然说K值的选取,会影响结果,有人会认为这个算法不稳定,其实不然,这种影响并不是很大,因为只有这种影响只是在类别边界上产生影响,而在类中心附近的实例影响很小,看下图,对于这样的一个新实例,k=3,k=5,k=11结果都是一样的。
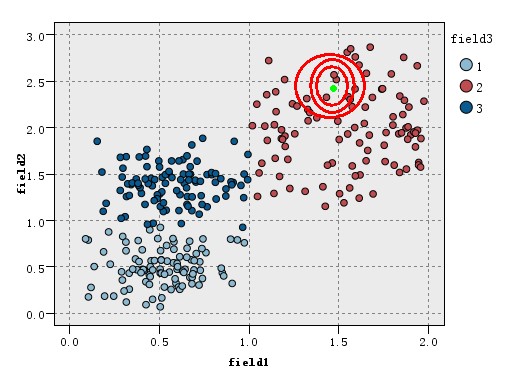
最后还有注意,在数据集不均衡的情况下,可能需要按各类的比例决定投票,这样小类的正确率才不会过低。
参考链接:http://www.cnblogs.com/fengfenggirl/archive/2013/05/27/knn.html














 19万+
19万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









